python3.5《机器学习实战》学习笔记(一):k近邻算法
转载请注明作者和出处:http://blog.csdn.net/u013829973
系统版本:window 7 (64bit)
python版本:python 3.5
IDE:Spyder (一个比较方便的办法是安装anaconda,那么Spyder和jupyter以及python几个常用的包都有了,甚至可以方便的安装TensorFlow等,安装方法链接)
代码和数据集在: GitHub
- k近邻算法
- 1 k近邻算法概述
- 2 可视化与距离计算
- 3 python实现KNN
- 31 准备数据
- 32 k近邻算法
- 33 KNN算法完整代码
- k近邻算法总结
k近邻算法
1.1 k近邻算法概述
k近邻(k-nearest neighbor,KNN)是一种基本的分类与回归算法。于1968年由Cover和Hart提出。k近邻的输入是实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k近邻算法假设给定一个训练数据集,其中的实例类别已定,分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻法不具有显式的学习过程。简单的说,给定一个训练数据集,对新的输入实例,在训练集中找到与该实例最近邻的k个实例,这k个实例的多数属于哪个类,就把该输入实例分为这个类。这就是k近邻算法中k的出处,通常k是不大于20的整数。
k近邻算法的三个基本要素:k值的选择、距离度量、分类决策规则
下面我们就用一个简单的例子来更好的理解k近邻算法:
已知表格的前四部电影,根据打斗镜头和接吻镜头判断一个新的电影所属类别?
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| 1 | 3 | 104 | 爱情片 |
| 2 | 2 | 100 | 爱情片 |
| 3 | 99 | 5 | 动作片 |
| 4 | 98 | 2 | 动作片 |
| 未知电影? | 18 | 90 | 未知 |
已知的训练集包含两个特征(打斗镜头和接吻镜头)和类别(爱情片还是动作片)。根据经验,动作片往往打斗镜头比较多,而爱情片往往就是接吻的镜头比较多了。但是knn算法可没有我们这么感性的认识。
1.2 可视化与距离计算
我们首先对训练数据进行可视化:
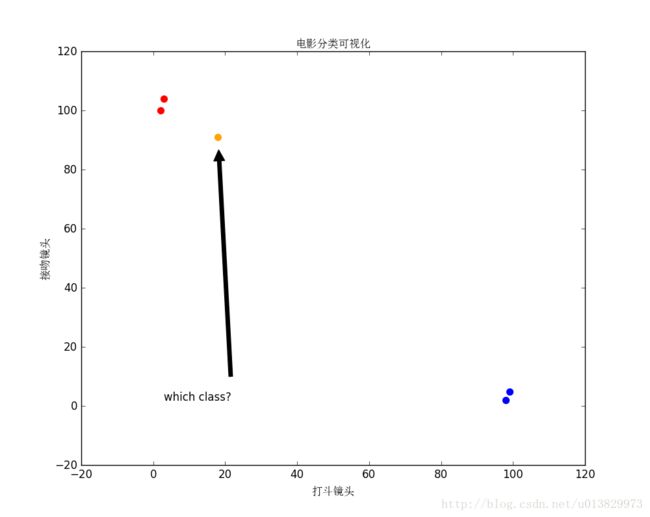
图1.1 电影分类(图中的红色点代表爱情片,蓝色点代表动作片,橙色点代表未知电影)
那么,knn是通过计算什么来判断未知电影属于哪一类的呢?答案:距离。我们首先计算训练集的所有电影与未知电影的欧式距离:(这里的距离除了欧式距离,还有曼哈顿距离、切比雪夫距离、闵可夫斯基距离等等)
欧式距离(Euclidean Distance)计算公式:两个n维向量 a(x11,x12,…,x1n) 与 b(x21,x22,…,x2n) 间的欧氏距离:
对于本例子n=2,
电影1与未知电影距离:20.5;
电影,2与未知电影距离:18.7;
电影3与未知电影距离:117.4;
电影4与未知电影距离:118.9;
现在我们得到了训练集中所有样本与未知电影的距离,按照距离递增排序,可以找到距离最近的电影,假设k=3,则三个最靠近的电影依次是电影1、电影2、电影3,而这三部电影类别2个为爱情片,一个为动作片,所以该未知电影的所属类别是爱情片。
有了上面的这个例子,我们来总结一下k近邻算法步骤:
对未知类别属性的数据集的每个点依次执行以下操作
(1) 计算已知类别数据集中的点与当前点之间的距离;
(2) 按照距离递增次序排序;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点所出现频率最高的类别作为当前点的预测分类
1.3 python实现KNN
我们仍然以上面的电影分类进行代码编写
1.3.1 准备数据
对表1.1中的训练数据,用numpy创建数据集和标签
'''
函数功能:创建数据集
Input: 无
Output: group:数据集
labels:类别标签
'''
import numpy as np
def createDataSet():#创建数据集
group = np.array([[3,104],[2,100],[99,5],[98,2]])
labels = ['爱情片','爱情片','动作片','动作片']
return group, labels
'''
函数功能: 主函数
'''
if __name__ == '__main__':
group,labels = createDataSet()#创建数据集
print('group:\n',group)#打印数据集
print('labels:',labels)程序运行结果:

1.3.2 k近邻算法
'''
函数功能: kNN分类
Input: inX: 测试集 (1xN)
dataSet: 已知数据的特征(NxM)
labels: 已知数据的标签或类别(1xM vector)
k: k近邻算法中的k
Output: 测试样本最可能所属的标签
'''
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] # shape[0]返回dataSet的行数
diffMat = np.tile(inX, (dataSetSize,1)) - dataSet
# tile(inX,(a,b))函数将inX重复a行,重复b列
sqDiffMat = diffMat**2 #作差后平方
sqDistances = sqDiffMat.sum(axis=1)
#sum()求和函数,sum(0)每列所有元素相加,sum(1)每行所有元素相加
distances = sqDistances**0.5 #开平方,求欧式距离
sortedDistIndicies = distances.argsort()
#argsort函数返回的是数组值从小到大的索引值
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
#取出前k个距离对应的标签
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#计算每个类别的样本数。字典get()函数返回指定键的值,如果值不在字典中返回默认值0
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
#reverse降序排列字典
#python2版本中的iteritems()换成python3的items()
#key=operator.itemgetter(1)按照字典的值(value)进行排序
#key=operator.itemgetter(0)按照字典的键(key)进行排序
return sortedClassCount[0][0] #返回字典的第一条的key,也即是测试样本所属类别1.3.3 KNN算法完整代码
# -*- coding: utf-8 -*-
'''
Created on Sep 10, 2017
kNN: k近邻(k Nearest Neighbors) 电影分类
author:we-lee
'''
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import operator
'''
函数功能:创建数据集
Input: 无
Output: group:数据集
labels:类别标签
'''
def createDataSet():#创建数据集
group = np.array([[3,104],[2,100],[99,5],[98,2]])
labels = ['爱情片','爱情片','动作片','动作片']
return group, labels
'''
函数功能: kNN分类
Input: inX: 测试集 (1xN)
dataSet: 已知数据的特征(NxM)
labels: 已知数据的标签或类别(1xM vector)
k: k近邻算法中的k
Output: 测试样本最可能所属的标签
'''
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] # shape[0]返回dataSet的行数
diffMat = np.tile(inX, (dataSetSize,1)) - dataSet # tile(inX,(a,b))函数将inX重复a行,重复b列
sqDiffMat = diffMat**2 #作差后平方
sqDistances = sqDiffMat.sum(axis=1)#sum()求和函数,sum(0)每列所有元素相加,sum(1)每行所有元素相加
distances = sqDistances**0.5 #开平方,求欧式距离
sortedDistIndicies = distances.argsort() #argsort函数返回的是数组值从小到大的索引值
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]#取出前k个距离对应的标签
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#计算每个类别的样本数。字典get()函数返回指定键的值,如果值不在字典中返回默认值0
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
#reverse降序排列字典
#python2版本中的iteritems()换成python3的items()
#key=operator.itemgetter(1)按照字典的值(value)进行排序
#key=operator.itemgetter(0)按照字典的键(key)进行排序
return sortedClassCount[0][0] #返回字典的第一条的key,也即是测试样本所属类别
'''
函数功能: 主函数
'''
if __name__ == '__main__':
group,labels = createDataSet()#创建数据集
print('group:\n',group)#打印数据集
print('labels:',labels)
zhfont = matplotlib.font_manager.FontProperties(fname=r'c:\windows\fonts\simsun.ttc')#设置中文字体路径
fig = plt.figure(figsize=(10,8))#可视化
ax = plt.subplot(111) #图片在第一行,第一列的第一个位置
ax.scatter(group[0:2,0],group[0:2,1],color='red',s=50)
ax.scatter(group[2:4,0],group[2:4,1],color='blue',s=50)
ax.scatter(18,90,color='orange',s=50)
plt.annotate('which class?', xy=(18, 90), xytext=(3, 2),arrowprops=dict(facecolor='black', shrink=0.05),)
plt.xlabel('打斗镜头',fontproperties=zhfont)
plt.ylabel('接吻镜头',fontproperties=zhfont)
plt.title('电影分类可视化',fontproperties=zhfont)
plt.show()
testclass = classify0([18,90], group, labels, 3)#用未知的样本来测试算法
print('测试结果:',testclass)#打印测试结果程序运行结果:

2 k近邻算法总结
优点:
1. 简单、有效、精度高;
2. 对离群值不敏感;
3. 无数据输入假定;
4 .可用于数值型数据和离散型数据;
缺点:
1. 计算复杂度高、空间复杂度高;
2. 样本不平衡问题(即有的类别的样本数量很多,而其它类别的样本数量很少),影响分类效果;(关于样本不平衡问题的解决方法,参见http://blog.csdn.net/u013829973/article/details/77675147)
3. 一般数值很大的时候不用这个,计算量太大。但是单个样本又不能太少 ,否则容易发生误分;
4. 最大的缺点是无法给出数据的内在含义,无法给出任何数据的基础结构信息,无法知晓平均实例样本和典型实例样本具有什么特征。
注意事项
1. K值的设定
较小的k值,学习的近似误差减小,但是估计误差会增大,意味着整体模型变得复杂,容易过拟合。
较大的k值,学习的近似误差增大,但是估计误差会减小,意味着整体模型变得简单。
在应用中k值一般取一个比较小的数值。采用交叉验证选取最优的k值。
2.优化改进
在确定最终的类别时,不是简单的使用多数表决投票,而是进行加权投票,距离越近权重越高。
k近邻法中,当训练集、距离度量、k值和分类决策规则确定后,其结果唯一确定。
k近邻法的实现需要考虑如何快速搜索k个最近邻点。kd树是一种便于对k维空间中的数据进行快速检索的数据结构。详见李航《统计学习方法》第三章
下一篇,我们会将knn算法应用到实际问题中,实战:改进约会网站的配对效果和手写识别系统!
如有不当之处,请留言,谢谢!