Python爬取猫眼电影榜单评分,以及评论
猫眼电影评论爬取
【目标】
(1)爬取榜单电影名称以及评分,简单的数据可视化。
(2)爬取《 你好,李焕英》的评论,用词云显示
第一步:了解反爬机制:
1.请求过多,ip地址会被封掉24h。
2. User-Agent要频繁更换
第二步:如何避免反爬:
1.使用虚拟ip(网站:https://h.shenlongip.com/index/index.html,注册可领取500ip)。
2. 引入fake-useragent,配合random函数。
第三步:确定URL地址
(1)猫眼榜单URL:
https://maoyan.com/board
(2)你好李焕英页面URL:
https://maoyan.com/films/1299372
第四步:
一:获取榜单电影名称,以及评分
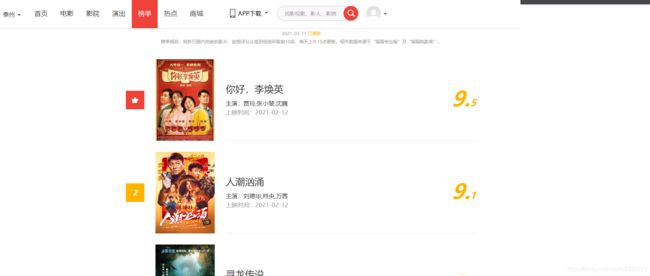
1.分析网页源代码

使用正则表达式
<dd>.*?<a href=.*? title="(.*?)" class="image-link".*?<p class="score"><i class="integer">(.*?)</i><i class="fraction">(.*?)</i>
代码实现:
def parse_html_one(self,one_url):
one_regex = '.*?(.*?)(.*?)'
one_html = self.get_html(url=one_url)
r_list = self.re_func(one_regex,one_html)
list01=[]
list02 =[]
j=1
for i in r_list:
list01.append(i[0])
list02.append(eval(i[1]+i[2]))
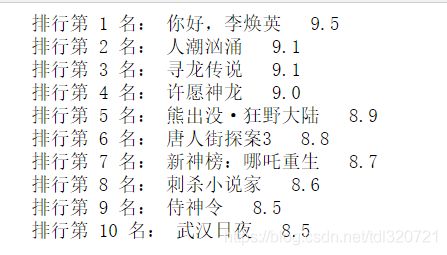
print("排行第 {} 名:".format(j),i[0],' '+i[1]+i[2])
j=j+1
输出结果:
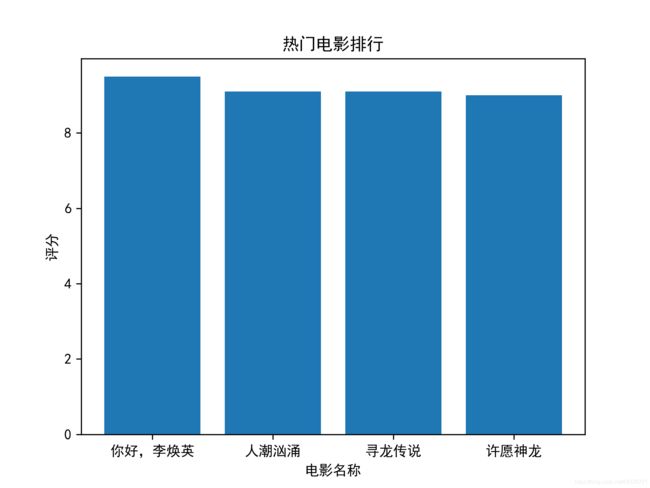
将排行前四的电影及评分用条形图展示:
代码实现:
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('电影名称')
plt.ylabel('评分')
plt.bar(list01[0:4], list02[0:4])
plt.title('热门电影排行')
plt.savefig('g:spider/猫眼电影/排行分析/谭——排行.png', dpi=300)
plt.show()
条形图展示:
二:爬取《 你好,李焕英》的评论,并用词云显示。
1.分析网页源代码:

用正则表达式表示:
<div class="comment-content">(.*?)</div>
将获取的内容保存到txt文件中
 读取txt文件,用词云展示
读取txt文件,用词云展示
def word_coud(self,s,name_list,text):
#功能:生成词云
cut_text = jieba.cut(text)
result = " ".join(cut_text)
font = r'C:\Windows\Fonts\simfang.ttf'
wc = WordCloud(collocations=False,
font_path=font,
width=800, height=800,
margin=2,
scale=20,
max_words=30,
background_color='white').generate(text.lower())
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file('g:spider/猫眼电影/排行分析//谭——{}.png'.format(name_list))
词云展示:

完整代码:
#需要安装re库,requests库,fake_useragent库,wordcloud库,jieba库,matplotlib库
#在cmd中使用pip install 相应的库
import re
import requests
import time
import random
from fake_useragent import UserAgent#代理池
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud
class Catfilmspidr:
def __init__(self):
self.paihang_url = 'https://maoyan.com/board'
self.list_url = 'https://maoyan.com/films/1299372'
#初始化
pass
def get_html(self,url):
#功能:请求网页
ip = '222.93.74.8:63325'
header = {
'User-Agent':UserAgent().random}
html = requests.get(url = url,proxies ={
'http' : 'http://{}'.format(ip),'https':'https://{}'.format(ip)},headers = header).content.decode('utf-8')
return html
def re_func(self,regex,html):
#功能:解析网页
pattern = re.compile(regex,re.S)
r_list = pattern.findall(html)
return r_list
def parse_html_one(self,one_url):
one_regex = '.*?(.*?)(.*?)'
one_html = self.get_html(url=one_url)
r_list = self.re_func(one_regex,one_html)
list01=[]
list02 =[]
j=1
for i in r_list:
list01.append(i[0])
list02.append(eval(i[1]+i[2]))
print("排行第 {} 名:".format(j),i[0],' '+i[1]+i[2])
j=j+1
#功能:生成条形图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel('电影名称')
plt.ylabel('评分')
plt.bar(list01[0:4], list02[0:4])
plt.title('热门电影排行')
plt.savefig('g:spider/猫眼电影/排行分析/谭——排行.png', dpi=300)
plt.show()
def parse_html_two(self,two_url):
#功能:提取网页内容
name_regex = '(.*?)
' #电影名称正则表达式
comment_regex ='(.*?)'#评论正则表达式
two_html = self.get_html(url=two_url)
name_list = self.re_func(name_regex,two_html)#获取电影名称(列表类型)
comment_list = self.re_func(comment_regex,two_html)#获取评论信息(列表类型)
file_name = 'g:spider/猫眼电影/排行分析/谭——{}.txt'.format(name_list[0])
f = open(file_name,'w',encoding='utf-8') #评论保存
print(name_list)
for i in comment_list:
f.write(i)
f.write('\n')
print('{}抓取成功'.format(name_list[0]))
f.close
self.word_parse(file_name,name_list[0])#词频分析
def word_parse(self,file_name,name_list):
#功能:词频分析,可以参照Python语言程序设计基础P171
text = open(file_name, "r",encoding='utf-8').read()
counts={
}
words = jieba.cut(text)
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items =list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
s=' '
for i in range(5):
word,count = items[i]
s=word+','+s
print('{}:{}'.format(word,count))
print(s)
self.word_coud(s,name_list,text) #生成词云 图片保存
def word_coud(self,s,name_list,text):
#功能:生成词云
cut_text = jieba.cut(text)
result = " ".join(cut_text)
font = r'C:\Windows\Fonts\simfang.ttf'
wc = WordCloud(collocations=False,
font_path=font,
width=800, height=800,
margin=2,
scale=20,
max_words=30,
background_color='white').generate(text.lower())
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file('g:spider/猫眼电影/排行分析//谭——{}.png'.format(name_list))
def run_spider(self):
self.parse_html_one(self.paihang_url)
self.parse_html_two(self.list_url)
if __name__=='__main__':
start_time = time.time()
spider =Catfilmspidr()
spider.run_spider()
end_time =time.time()
a=end_time - start_time
print('执行时间为:{0:.2f}'.format(a))