Flink源码分析: 窗口机制的执行流程
这篇文章主要是研究一下Flink的window执行流程,但是不会详细的分析代码实现的细节,因为这部分的代码还是非常多的,先了解一下代码执行的整个流程,为后面分析WindowOperator的源码实现逻辑做一个铺垫.
关于Flink的window使用相信大家都比较熟悉了,日常开发中很多场景都会用到window,可以说window是Flink流计算的核心功能之一,我们先来看下官网对于window的使用流程介绍.(这里以keyed Windows为例).
stream .keyBy(...) <- keyed versus non-keyed windows .window(...) <- required: "assigner" [.trigger(...)] <- optional: "trigger" (else default trigger) [.evictor(...)] <- optional: "evictor" (else no evictor) [.allowedLateness(...)] <- optional: "lateness" (else zero) [.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data) .reduce/aggregate/fold/apply() <- required: "function" [.getSideOutput(...)] <- optional: "output tag"
这里的组件我就不在一一介绍了,可以看到有些是必须选择的,有一些是有默认值的,还有一些是可选择的,不同的场景使用方法也不一样.
在看源码之前先来看一下Flink数据流上的类型和操作.下图展示了 Flink 中目前支持的主要几种流的类型,以及它们之间的转换关系。
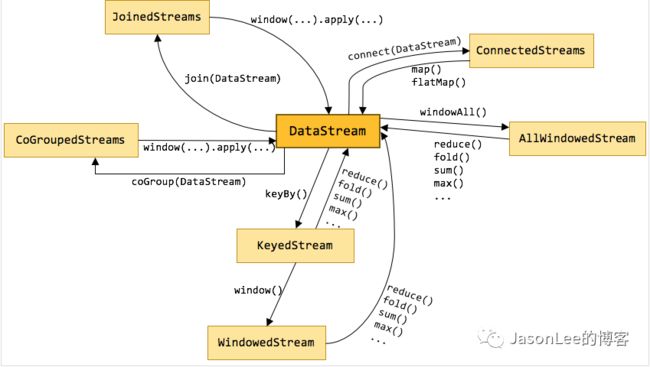
从上图可以看到所有的transform操作都是基于DataStream,然后经过transform操作又返回了DataStream类型(中间可能有别的类型但是最终都又回到了DataStream类型),对于window来说,首先DataStream经过keyby返回的是KeyedStream类型,用来表示根据指定的key进行分组的数据流,然后在经过window返回的是WindowedStream流类型,代表了根据key分组,并且基于WindowAssigner切分窗口的数据流,然后在对WindowedStream做比如sum,max,或者自定义的process函数操作后,最终又会返回DataStream类型.
需要注意的是WindowedStream并不是DataStream的子类,KeyedStream是DataStream的子类,但是他们都是在同一个包下面的.
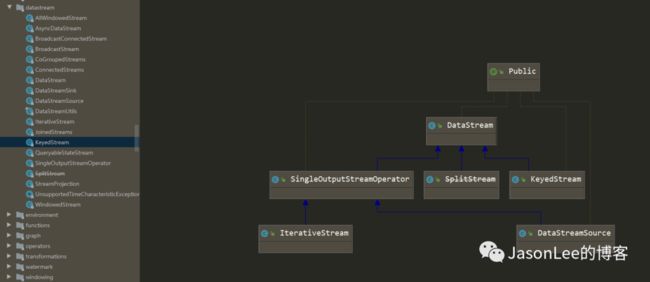
我们先来看一下KeyedStream中的window的源码如下:
@PublicEvolving public WindowedStream window(WindowAssigner assigner) { return new WindowedStream<>(this, assigner); }
可以看到它返回的是一个WindowedStream类型的数据,然后接着看WindowedStream的源码
public class WindowedStream { /** The keyed data stream that is windowed by this stream. */ private final KeyedStream input; /** The window assigner. */ private final WindowAssigner windowAssigner; /** The trigger that is used for window evaluation/emission. */ private Trigger trigger; /** The evictor that is used for evicting elements before window evaluation. */ private Evictor evictor; /** The user-specified allowed lateness. */ private long allowedLateness = 0L; /** * Side output {@code OutputTag} for late data. If no tag is set late data will simply be * dropped. */ private OutputTag lateDataOutputTag; @PublicEvolving public WindowedStream(KeyedStream input, WindowAssigner windowAssigner) { this.input = input; this.windowAssigner = windowAssigner; this.trigger = windowAssigner.getDefaultTrigger(input.getExecutionEnvironment()); } }
这里只贴了部分代码,可以看到WindowedStream的成员变量有KeyedStream,WindowAssigner,Trigger 等 这些不就是上面window程序结构里面的东西吗 上面的window操作就是调用了WindowedStream的构造方法,初始化了窗口分配器,输入数据,trigger几个变量.那Flink是怎么把这些组件串起来调用的呢? 就在我们自定义的窗口函数里面.
@Internal public SingleOutputStreamOperator process(ProcessWindowFunction function, TypeInformation resultType) { function = input.getExecutionEnvironment().clean(function); return apply(new InternalIterableProcessWindowFunction<>(function), resultType, function); }
这个方法是将给定的窗口函数应用于每个窗口。分别为每个窗口函数调用我们自己定义的方法.也就是我们自己定义的apply/process方法,不管是apply还是process最终都会调用apply方法.
private SingleOutputStreamOperator apply(InternalWindowFunction, R, K, W> function, TypeInformation resultType, Function originalFunction) {
final String opName = generateOperatorName(windowAssigner, trigger, evictor, originalFunction, null); KeySelector keySel = input.getKeySelector();
WindowOperator, R, W> operator;
if (evictor != null) { @SuppressWarnings({"unchecked", "rawtypes"}) TypeSerializer> streamRecordSerializer = (TypeSerializer>) new StreamElementSerializer(input.getType().createSerializer(getExecutionEnvironment().getConfig()));
ListStateDescriptor> stateDesc = new ListStateDescriptor<>("window-contents", streamRecordSerializer);
operator = new EvictingWindowOperator<>(windowAssigner, windowAssigner.getWindowSerializer(getExecutionEnvironment().getConfig()), keySel, input.getKeyType().createSerializer(getExecutionEnvironment().getConfig()), stateDesc, function, trigger, evictor, allowedLateness, lateDataOutputTag);
} else { ListStateDescriptor stateDesc = new ListStateDescriptor<>("window-contents", input.getType().createSerializer(getExecutionEnvironment().getConfig()));
operator = new WindowOperator<>(windowAssigner, windowAssigner.getWindowSerializer(getExecutionEnvironment().getConfig()), keySel, input.getKeyType().createSerializer(getExecutionEnvironment().getConfig()), stateDesc, function, trigger, allowedLateness, lateDataOutputTag); }
return input.transform(opName, resultType, operator); }
apply这个方法中间经过各种操作,最终调用了input.transform方法,这个方法返回的是SingleOutputStreamOperator类型的数据,SingleOutputStreamOperator又是DataStream的一个子类,所以最终还是返回了DataStream类型,和上面说的数据流上的类型和操作可以对应上.
apply方法的逻辑非常简单,主要就是判断evictor是否为空,然后分别走了不同的WindowOperator,其实最终真正的处理数据的逻辑是在WindowOperator里面的,window中的windowAssigner 、trigger、evictor这些都是被封装到
WindowOperator这个类里面的,然后又调用了DataStream的transform方法最终返回的还是DataStream类型. 到这里相信大家对整个流程会清晰一点了.
这篇文章就先介绍到这里,后面会单独分析WindowOperator的源码,因为这部分的关系还是比较复杂的.
总结一下:
这篇文章主要介绍了Flink的Window机制内部执行的流程,首先是DataStream经过keyby返回keyedstream类型,然后在经过window操作返回windowedstream类型,然后在windowedstream上调用我们自己定义的apply或者process方法,最终都会调用apply方法,这个方法里会把所有的东西封装到WindowOperator里面,最后调用transform方法返回DataStream流类型的数据,有一种跑了一圈又回到原地的感觉.
推荐阅读:
JasonLee,公众号:JasonLee的博客Flink到底能不能实现exactly-once语义
Flink1.10.0 SQL DDL 把计算结果写入kafka
JasonLee,公众号:JasonLee的博客Flink1.10.0 SQL DDL 把计算结果写入kafka
Flink 1.10.0 SQL DDL中如何定义watermark和计算列
JasonLee,公众号:JasonLee的博客Flink 1.10.0 SQL DDL中如何定义watermark和计算列
FlinkSQL使用DDL语句创建kafka源表
JasonLee,公众号:JasonLee的博客FlinkSQL使用DDL语句创建kafka源表
Flink 状态清除的演进之路
JasonLee,公众号:JasonLee的博客Flink 状态清除的演进之路
Flink动态写入kafka的多个topic
JasonLee,公众号:JasonLee的博客Flink动态写入kafka的多个topic
更多spark和flink的内容可以关注下面的公众号
