作者|陶建辉
原文首发于:
我们写 C 程序,经常碰到 Crash,绝大部分情况下都是空指针或野指针造成,从 call stack 来看,一般很容易找出问题。但是有一类 Crash 很难 debug,那就是内存溢出。溢出的部分的内存空间正好覆盖另外一个线程访问的数据(比如一个结构体),那么另外一个线程读取这块数据时,获取的数据就是无效的,往往导致不可预见的错误,甚至 Crash。但因为造成数据溢出的线程已经离开现场,导致问题很难定位。这是我在 2020 年 5 月写的一篇内部博客,以我当时碰到的一个错误为例,将解决这类问题的方法分享出来,供大家参考,举一反三。
具体问题
在feature/query分支上,在community仓库,执行以下脚本,出现Crash。
./test.sh -f general/parser/col_arithmetic_operation.sim重现问题
我登录到指定的机器,查看了 core dump, 确实如此。Call Stack 截图如下:

第一步:看哪个地方 crash。是 shash.c:250 行,使用 GDB 命令 “f 1″ 查看 stack 1,查看*pObj,一下就看到 hashFp 为 NULL,自然会 crash。但为什么会设置为空?其他参数呢?dataSize 设为 0 也一定是错的。因此可以断定,这个结构体是不对的。我们需要看上一层调用是否传入了正确的参数。
第二步:使用 GDB “f 2″查看 stack 2,rpcMain.c:605 行,查看*pRpc,这些结构体里的参数显得很正常,包括指向 hash 的指针值看不出有什么问题。那因此可以断定调用是 OK 的,调用 taosGetStrHashData 应该提供了正确的参数。
第三步:既然参数对的,看 shash.c 的程序,那只可能是 SHashObj 这个结构体已经被释放,访问的时候,自然无效。再看代码,只有一个可能,函数 taosCleanUpStrHash 被调用,因此我在改函数里马上加上一行打印日志(注意 TDengine 的日志输出控制,系统配置文件 taos.cfg 里参数 asyncLog 要设置为 1,否则 crash 时,有可能日志不打印出来)。重新运行脚本,查看日志,发现 taosCleanUpStrHash 没有被调用过。那么现在只有一个可能,这一块数据的内存被其他线程写坏。
第四步:万幸,我们有很棒的运行时内存检查工具 valgrind, 可以通过运行它来找找蛛丝马迹。一运行(valgrind 有很多选项,我运行的是 valgrind –leak-check=yes –track-origins=yes taosd -c test/dnode1/cfg),一下就发现有 invalid write,截图如下:
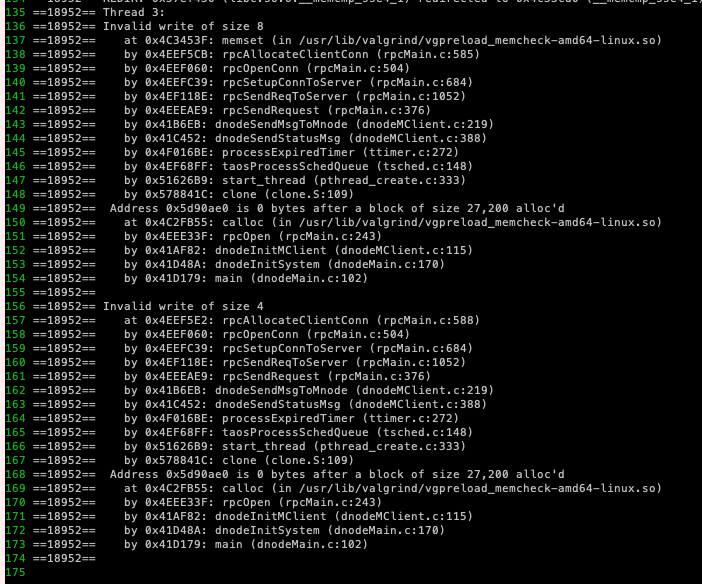
第五步:一看 valgrind 输出,就知道 rpcMain.c:585 有 invalid write, 这里是 memcpy。从编码上来看,这应该没有问题,因为拷贝的是固定大小的结构体 SRpcConn,每次运行到这里都会执行的。那么唯一的可能就是 pConn 指向的是无效的内存区,那 pConn 怎么可能是无效的?我们看一下程序:
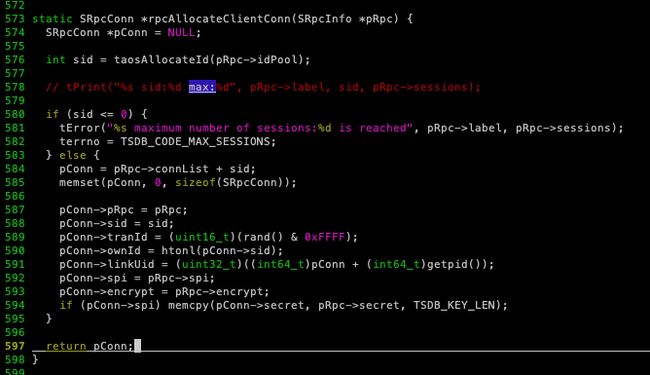
看 584 行,pConn = pRpc->connList + sid。这个 sid 是 taosAllocateId 分配出来的。如果 sid 超过 pRpc->sessions,那 pConn 毫无疑问就指向了无效的区域。那怎么确认呢?
第六步:加上日志 578 行,分配出的 ID 打印出来,编译,重新运行测试脚本。
第七步:crash,看日志,可以看到 sid 能输出到 99(max 是 100),还一切正常,但之后就崩溃。因此可以断言,就是由于分配的 ID 超过了 pRpc→session。
第八步:查看分配 ID 的程序 tidpool.c,一看就知道原因,ID 分配是从 1 到 MAX,而 RPC 模块只能使用 1 到 Max-1。这样当 ID 返回为 max 时,RPC 模块自然会产生 invalid write。
解决方案
既然知道原因,那就很好办,有两套方法:
- 在 tidpool.c,taosInitIdPool 里,将 maxId 减一,这样分配的 ID 只会是 1 到 max-1。
- 在 rpcMain.c 的 rpcOpen() 函数里,将
pRpc->idPool = taosInitIdPool(pRpc->sessions);改为
pRpc->idPool = taosInitIdPool(pRpc->sessions-1);如果应用要求最多 100 个 session,这么改,RPC 至多创建 99 个,为保证 100 个,再将
pRpc->sessions = pInit->sessions;改为
pRpc->sessions = pInit→sessions+1;验证
两种方法,都重新编译,运行测试脚本通过,crash 不再发生。
经验总结
遇到内存被写坏的场景,一定要用 valgrind 跑一次,看是否有 invalid write。因为它是一个动态检查工具,报的错误都应该是对的。只有把 invalid write 先解决,再去看 crash 问题。
怎么避免类似问题
这个 BUG 的核心是由于 tidpool.c 分配的 ID 范围是 1 到 max,而 RPC 模块假设的 ID 分配是 1 到 max-1。因此是模块之间的约定出了问题。
怎么避免?每个模块对外 API 要做详细说明,如果 API 做了调整,要通知大家,而且要运行完整的测试例,以免破坏了某种约定。
本文为 TDengine 的一则真实案例,git commit id:89d9d62,欢迎大家重现。