上一章我们学习了对智能合约开发来说至关重要的第一步:
- 知道了RAM、multi_index和EOS数据库各是什么以及它们之间的关系;
- 知道了multi_index是内存数据库的入口;
- 了解了multi_index内部的结构长什么样子;
今天这章,主要介绍multi_index的相关操作,趁机巩固一波上一章学习到的理论知识。
摘要
上一章说到multi_index的概念——多索引容器,multi_index容器的内部结构可以类比成传统数据库里的一张表,只不过这张表只有一列,每一行都是一个struct结构体。
这一章就要向大家介绍,如何具体使用multi_index。
primary keys
还是上一章中的例子:
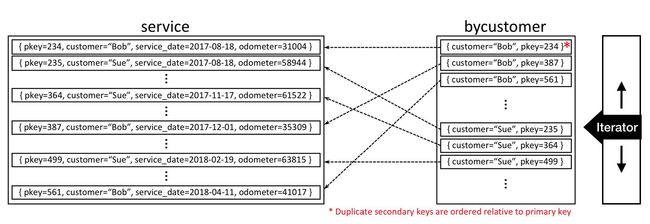
multi_index的容器(表)里每一行都是上面的struct结构体,并且都是按照主键升序排列。所以每一个multi_index中会有一个默认索引,也就是主键。如上图,就是按照主键(pkey)升序排列的。
uint64_t primary_key() const { return pkey; }
一般而言,在struct结构体中会声明一行获得主键的方法primary_key(),这里定义了主键类型为uint64_t,返回结构体中的pkey字段,即pkey这个字段就是整个结构体的主键。
自定义索引
既然叫multi_index,肯定不只可以根据主键进行索引,事实上,我们还可以自定义索引。例如可以在结构体中定义如下方法:
account_name get_customer() const {
return customer;
}
这就是我们自定义的索引。仿照之前的primary_key()可以看到,这个方法返回值的类型为account_name,返回的字段为customer。当然自定义的索引并不一定要返回结构体中的某个字段的变量,也可以将变量之间的运算结果作为索引。
这里先贴上结构体的完整表达,方便下面介绍如何使用多索引:
struct service_struct {
uint64_t pkey;
account_name customer;
Date date;
uint32_t odometer;
auto primary_key() const {return pkey;}
account_name get_customer() const {return customer;}
EOSLIB_SERIALIZE(service_struct,( pkey )( customer )( date )( odometer ))
}
typedef eosio::multi_index
>
> customer_index;
解释一下,使用上面的方式来定义索引,eosio::multi_index<...>的参数解释如下:
-
service: multi_index容器的表名(如上图) -
service_struct: 智能合约重定义的struct结构体名称,也可以理解成表中的一行记录; -
indexed_by<...>:-
N(bycustomer): 给索引起个名字 - bycustomer -
const_mem_fun<...>:-
account_name: 索引的类型 -
&service_struct::get_customer:通过service_struct结构体中的get_customer函数获得(索引)
-
-
通过上述表达,就可以再生成一张按customer为索引的表bycustomer(见本文第一张图)。左边是按照主键索引的原表service,右边的表就是我们按照customer的索引生成的新表(按customer从小到大进行排列),可以看到新表内的行内容和之前是一行的(见虚线指向原表),只不过按照customer字段进行了重新排列。
这里定义了customer_index类型,这样以后就可以直接用这个类型去初始化真正的multi_index表。
迭代器
上一章我们介绍过迭代器,可以把迭代器想象成一个电梯,通过在索引中上下滑动来定位数据。接着上面介绍的自定义索引comstomer_index:
account_name customer_acct = eosio::chain::string_to_name(customer_name);
auto cust_itr = customer_index.find(customer_acct);
通过上述代码,我们就可以找到bycustomer表中,customer为某个特定值的所有行(结构体)了。比如,第一张图中,如果传入的参数为"bob",那就可以找出所有customer为bob的数据了,放入迭代器里。通过迭代器就可以逐条获取我们想要的数据信息。
得到了迭代器之后,咱们再来看看怎么使用迭代器:
while(cust_itr != service.end() && cust_itr -> customer == customer_acct) {
// code to execute
cust_itr++;
}
其中cust_itr != service.end()表示迭代器并没有走到service表的结尾,&&之后也很容易看懂,再筛选customer的值。每次小的遍历结束是,迭代器+1,表示继续访问迭代器中的下一行。
索引和迭代器如何配合工作
通过上面的介绍,大家应该就可以理清multi_index和迭代器是如何配合工作的:
i通过multi_index可以得到一张按照特定字段索引的表,再通过对索引设置一些条件,就可以筛选得到一些迭代器,再通过对迭代器的遍历,就可以访问我们想要访问的数据了。
multi_index的初始化
上文关于multi_index多与定义有关,现在终于要开始实例化multi_index了。
multi_index(uint64_t code, uint64_t scope)
在上面的初始化(实例化)的语句中,可以看到有两个参数:
- code -拥有这张multi_index表的账户,该账户拥有对合约数据的读写权限;
- scope - 用户账户名下的区域。可以在code下定义多个scope,把属于不同scope的表隔离开;
这里的code和scope,都是用来为表建立访问权限的。
所以要想初始化上面的customer_index,可以使用:
// customer_index 就是之前 typedef 定义的类型
// bycustomer就是新表
// _self就是当前调用方法的账户
customer_index bycustomer(_self, _self);
添加 - emplace
这里顺便说一下find,multi_index使用.find来查询,代码接上往下写:
void demo::create(const uint64_t id,
const account_name cust_acct,
const Date date,
const uint32_t odometer) {
// 找出特定值的customer的数据
// 这里的auto相当于其他语言中的var,声明变量时不指定类型
auto itr = bycustomer.find(cust_acct);
// 查询customer = cust_acct的记录并要求该记录不存在
// 因为primary_key不能重复
// 所以插数据之前先查询一下,保证不重复
eosio_assert(itr == profile.end(), "Account already exists");
// 往索引里添加记录
bycustomer.emplace(cust_acct, [&](auto& c)) {
c.pkey = id;
c.customer = cust_acct;
c.date = date;
c.odometer = odometer;
}
}
其中[&](auto& c)是c11之后一种新的lambda表达式,有兴趣的同学可以自行深入了解,这里简单介绍一下,这个表达式大概表示:
除了该函数已有的参数,其他的参数例如 id, date, odometer这些,都是在上层的作用域中通过引用的形式传入函数内。
其中auto我们之前说过,表示不限制类型,但是也为引用。
看懂了添加记录,其他诸如删、改、查的操作也就不难看懂了,大家可以去官网查看相关例子:
https://eosio-cpp.readme.io/docs/using-multi-index-tables
结束语
本章我们学习了:
- 如何自定义索引;
- 如何生成以及使用迭代器;
- 索引和迭代器是如何配合使用的;
- multi_index的相关操作
希望大家学完之后可以去官网继续补充删、改、查的相关例子,以达到举一反三的效果。下面几篇我们将正式了解EOS智能合约开发的二三事。