分析成果的链接
本文目录:
一 项目背景介绍
二 数据整理和罗列分析指标
三 使用Python聚合数据并实现自动更新
四 实现hive数据仓库以及处理日常需求
一 项目背景介绍
Adventure Works Cycles是Adventure Works样本数据库所虚构的公司,这是一家大型跨国制造公司。该公司生产和销售自行车到北美,欧洲和亚洲的商业市场。虽然其基地业务位于华盛顿州博塞尔,拥有290名员工,但几个区域销售团队遍布整个市场。
1 客户类型
个体:这些客户购买商品是通过网上零售店铺;
商店:这些是从Adventure Works Cycles销售代表处购买转售产品的零售店或批发店。
2 产品介绍
Adventure Works Cycles生产的自行车;
自行车部件,例如车轮,踏板或制动组件;
从供应商处购买的自行车服装,用于转售给Adventure Works Cycles的客户;
从供应商处购买的自行车配件,用于转售给Adventure Works Cycles的客户。
项目数据来源:数据来源于adventure Works Cycles公司的的样本数据库。
3 项目目标
通过现有数据监控商品的线上和线下销售情况,并且获取最新的商品销售趋势,以及区域分布情况,为公司的制造和销售提供指导性建议,以增加公司的收益。
二 数据整理和罗列分析指标
目的:了解数据库包含哪些信息,根据业务需要,罗列可分析的指标。
1 基本数据梳理
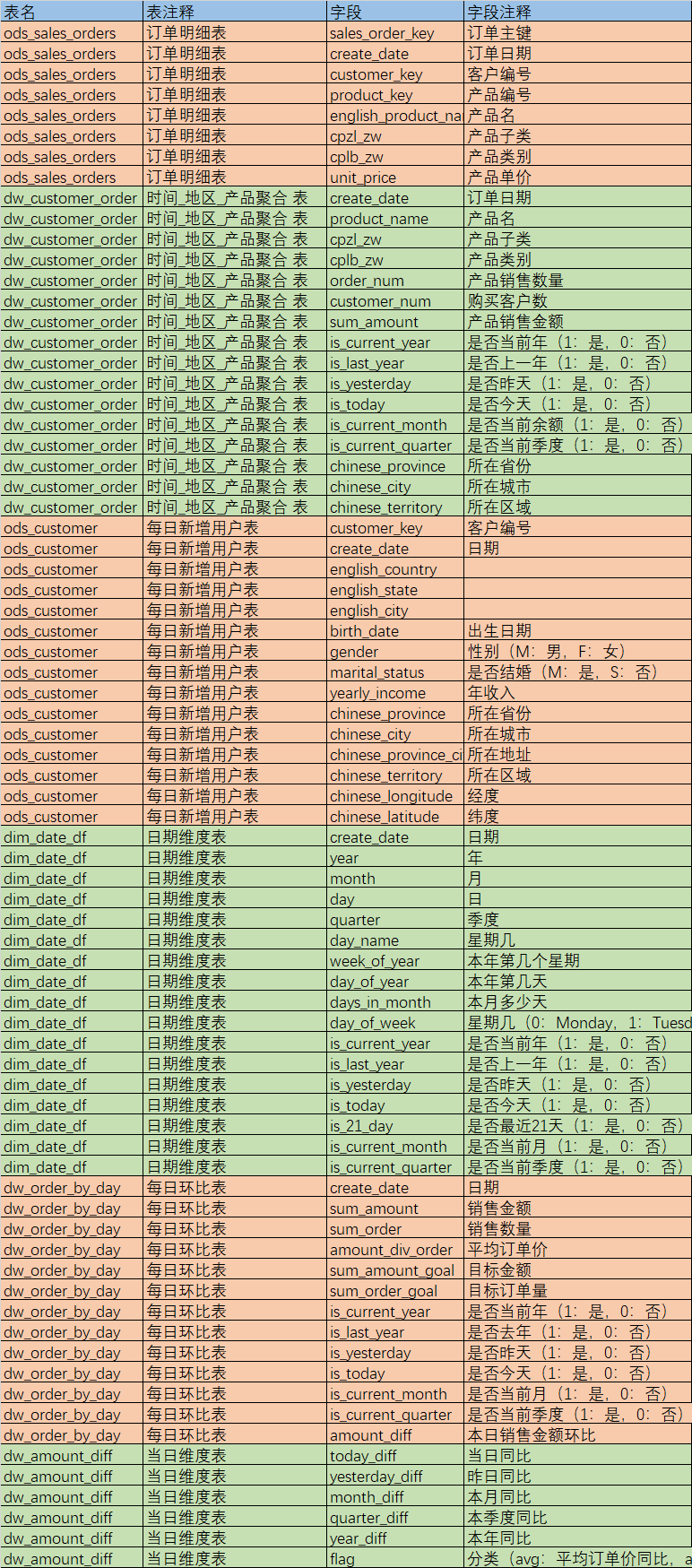
从mysql数据库中共有6张表,分别是订单明细表、时间地区产品聚合表、每日新增用户表、日期维度表、每日环比表、当日维度表,具体字段内容如下:
2 指标体系
分析维度:
时间维度——年、季度、月、周、日
地区维度——销售大区、国家、州/省、城市
产品维度——产品类别、产品子类
分析指标:
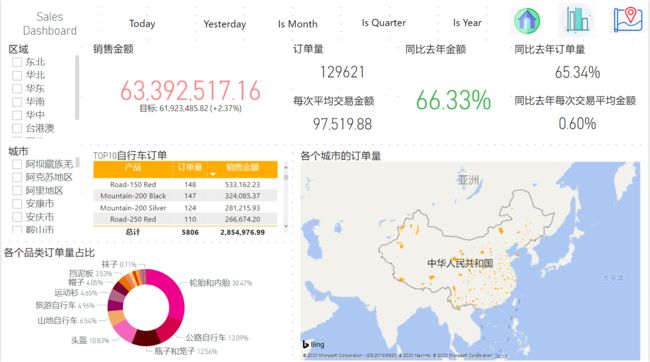
1 总销售额
2 总订单量
3 每次平均交易金额
4 同比去年金额
5 同比去年订单量
6 同比去年每次交易平均金额
7 销售额、销量目标达成率
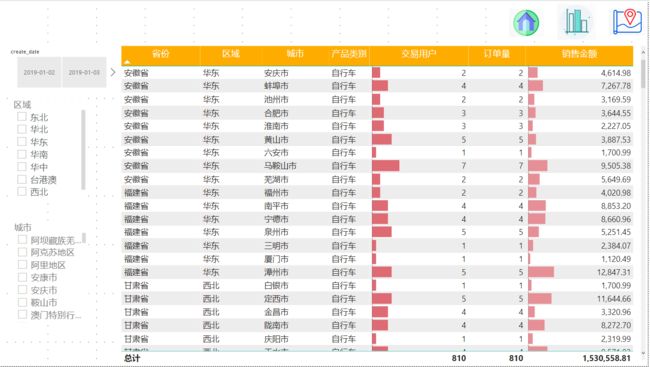
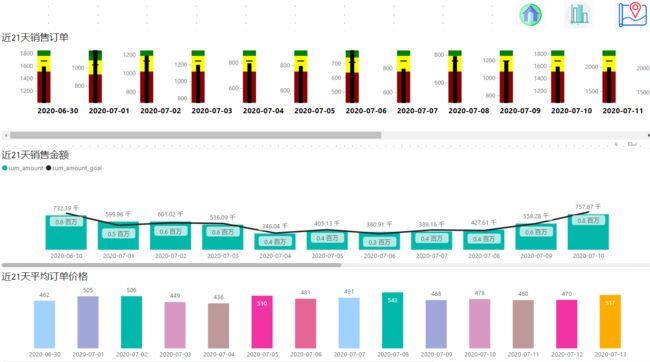
8 不同维度(时间、地区、产品)下的销售额、订单量
三 使用Python聚合数据并实现自动更新
1 根据基本数据,利用python进行加工
a 每日环比表(dw_order_by_day)
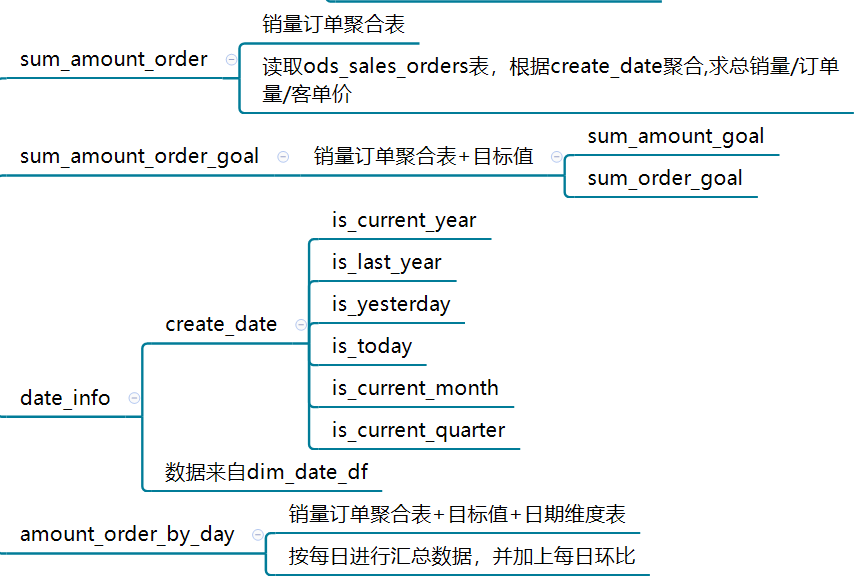
python部分代码如下:
def sum_amount_order(adventure_conn_read):
try:
sum_amount_order = pd.read_sql_query("select * from ods_sales_orders",
con=adventure_conn_read)
sum_amount_order = sum_amount_order.groupby("create_date").agg({
"unit_price": "sum",
"customer_key": pd.Series.nunique}).reset_index()
sum_amount_order.rename(columns={"unit_price":"sum_amount","customer_key":"sum_order"},inplace=True)
sum_amount_order['amount_div_order'] = sum_amount_order['sum_amount'] / sum_amount_order['sum_order']
return sum_amount_order
except Exception as e:
logger.info("sum_amount_order异常,报错信息:{}".format(e))
b 通过上表,生成同比数据表(dw_order_diff)

python部分代码如下:
def diff(stage, indictor):
"""
:param stage: stage:日期维度的判断,如:is_today 内有[0,1]
:param indictor: 需取值字段,如:sum_amount(总金额),sum_order(总订单量)
:return: 当前时间维度下总和,去年同期总和
"""
try:
current_stage_indictor = dw_order_by_day[dw_order_by_day
[stage] == 1][indictor].sum() # 求当前日期维度stage下的indictor总和
before_stage_indictor = list(dw_order_by_day[dw_order_by_day[stage] == 1]
["create_date"] + datetime.timedelta(days=-365)) # 取出当前日期维度下的前年对应日期列表
before_stage_indictor = dw_order_by_day[dw_order_by_day['create_date'].isin(before_stage_indictor)][indictor].sum() # 求当前日期维度下的前一年对应indictor总和
return current_stage_indictor, before_stage_indictor
except Exception as e:
logger.info("diff异常,报错信息:{}".format(e))
c 生成时间/地区/产品聚合表(update_sum_data)
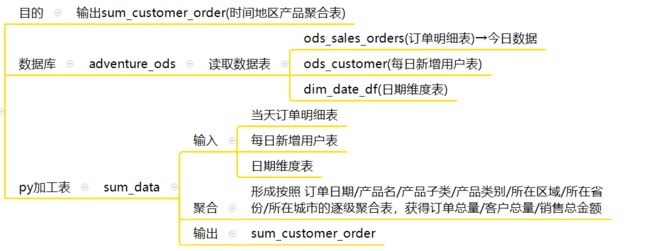
python部分代码如下:
def order_data(start_date, end_date, adventure_com_read):
"""
读取今日的ods_sales_orders(订单明细表)
:param star_time:
:param end_time:
:param adventure_com_read:
:return:
"""
try:
order_sql = """select sales_order_key,
create_date,
customer_key,
english_product_name,
cpzl_zw,
cplb_zw,
unit_price
from ods_sales_orders where create_date>='{start_date}' and create_date<'{end_date}'""".format(start_date=start_date[0], end_date=end_date[0])
order_info = pd.read_sql_query(order_sql, con=adventure_com_read)
return order_info
except Exception as e:
logger.info("order_data, 报错信息:{}".format(e))
2 在mysql追加索引优化查询速度,在python存储至sql
增添多进程
(1) mysql增加索引
mysql增加索引,类似于让搜索结果不需要遍历整个表,而是根据前缀索引一步步搜寻。类似于前缀树用法,比如where条件当中增加 '2019-1',那么索引会直接排除掉['2020','2018','2021']等这些年份结果,直接匹配前缀相符合的内容。
具体代码如下:
create index index_date on dw_order_by_day(create_date(7));
select * from dw_order_by_day where create_date='2019-02-11';
EXPLAIN select * from dw_order_by_day where create_date='2019-02-11';
(2) python增加多进程读取和存储
多进程就是多个程序同时在计算机进行执行活动,以此实现充分调用资源目的。项目中利用python的多进程语句应用到读取mysql,存储mysql这一方面去。
import multiprocessing
def runtask():
pass
def callBackTask(arg): # 回调函数必须要有一个形参,否则将报错
print("执行回调函数",arg)
if __name__ == "__main__":
pool = multiprocessing.Pool(5) # 设置进程池最大同时执行进程数
for index in range(20):
pool.apply_async(func=runtask,callback=callBackTask) # 并行的,有回调方法
# pool.apply(func=runtask,) # 串行的,无回调函数
pool.close() # 关闭进程池
pool.join() # #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程
加入到pool,join函数等待所有子进程结束
multiprocessing模块中的Pool 是进程池,进程池能够管理一定的进程,当有空闲进程时,则利用空闲进程完成任务,直到所有任务完成为止。以此为原理,将读取mysql部分利用 limit 限制及偏移,同时读取,实现多线程读取文件。同时,利用 mysql读取后形成的dataframe,使用dataframe.loc进行分块处理,实现多进程分块存储到mysql当中。
3 在Linux上部署代码,让其每日自动更新
- 定时执行模块:python 模块库 import schedule
- 与命令窗口交互模块: import os 的 os.system()
- 挂在后台功能则是利用linux系统自带的 & 挂后台, 使用后台运行命令,运行该代码,并将具体运行输出导到特定log文件
示例代码如下:
import schedule
import time
import datetime
import os
import requests
def job1():
"""
dw_order_by_day 每日环比表
"""
print('Job1:每天6:00执行一次')
print('Job1-startTime:%s' % (datetime.datetime.now().strftime('%Y-%m-%d
%H:%M:%S')))
os.system(
"/home/anaconda3/bin/python3 /home/frog005/adventure/dw_order_by_day.py
>> /home/frog005/adventure/hjf_logs/dw_order_by_day_schedule.log 2>&1 &")
time.sleep(20)
print('Job1-endTime:%s' % (datetime.datetime.now().strftime('%Y-%m-%d
%H:%M:%S')))
print('---------------------------------------------------------------------
---')
if __name__ == '__main__':
schedule.every().day.at('06:00').do(job1)
while True:
schedule.run_pending()
time.sleep(10)
print("wait", datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
四 实现hive数据仓库满足大数据需求
1 Hive的探索和学习
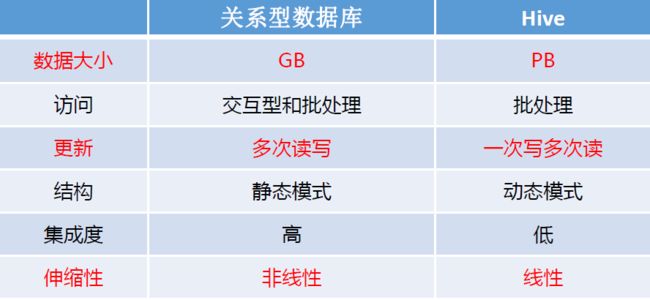
(1) Hive与关系型数据库的区别
使用Hive的命令行接口很像操作关系数据库,但是Hive和关系数
据库还是有很大的不同, Hive与关系数据库的区别具体如下:
- Hive和关系数据库存储文件的系统不同,Hive使用的是Hadoop的
HDFS(Hadoop的分布式文件系统),关系数据库则是服务器本地
的文件系统; - Hive使用的计算模型是Mapreduce,而关系数据库则是自身的计
算模型; - 关系数据库都是为实时查询的业务进行设计的,而Hive则是为海
量数据做数据挖掘设计的,实时性很差;实时性的区别导致Hive
的应用场景和关系数据库有很大的不同; - Hive不适合用于小数据集分析和交互式查询;
- Hive很容易扩展自己的存储能力和计算能力,这个是继承Hadoop
的,而关系数据库在这个方面要比数据库差很多。 - Hive并不支持事件或行级数据更新
(2) Mapreduce模型
- MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce。
a map:高度并行的map阶段,采用“分而治之”策略:
- 在这个阶段,输入数据被split为离散的块,可以被分别/并行处理
- 在map阶段,通常执行输入格式解析、投影(选择相关的字段)和过
滤(删除不感兴趣的记录)
b Reduce:一个聚合或汇总的阶段reduce阶段:
- 在这个阶段,map阶段的输出被聚合以产生期望的结果
-MapReduce核心概念
输入可以被分为(split)逻辑块(chunk),每个逻辑块最初可以被一个map task独
立地处理。这些单独处理的逻辑块的结果可以被物理地划分到不同的组,然后
被排序。每个排序过后的逻辑块被传递给一个reduce task。
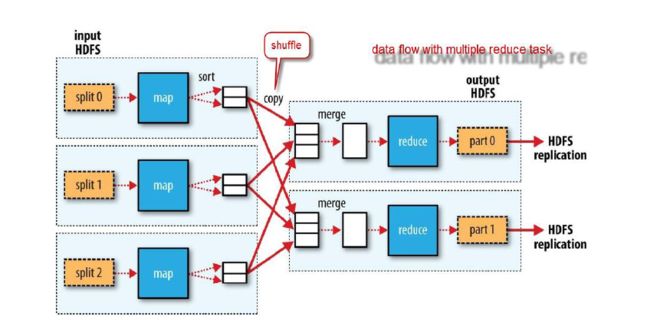
没有reduce task的数据流:
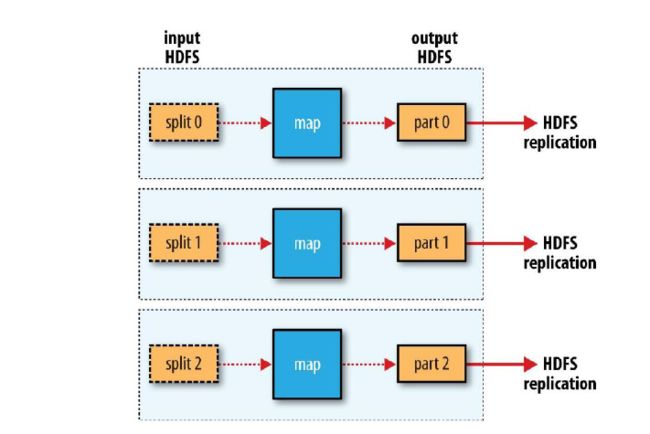
2 Sqoop抽取mysql数据导入hive
步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
步骤2:Sqoop启动一个Map-Only的MR作业,利用元数据信息并行将数据写入Hadoop。
Map-Only作业是指mapper执行所有任务的过程,reducer没有任务,mapper的输出是最终输出(如上图没有reduce task的数据流显示)。 Hadoop Map阶段获取一组数据并将其转换为另一组数据,其中各个元素被分解为元组(键/值对)。
-特点:可以指定hdfs路径,指定关系数据库的表,字段,连接数(不压垮数据库),可以导入多个表,支持增量导入(手动指定起始id、事件,或自动记录上次结束位置,自动完成增量导入)
下面是一个shell脚本代码:
## 导入查询出来的数据到Hive
hive -e "drop table if exists ods.dim_date_df" # 删除hive原有的旧表
sqoop import \
--hive-import \
## 告诉jdbc,连接mysql的url
--connect jdbc:mysql://IP:3306/数据库名?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&dontTrackOpenResources=true&defaultFetchSize=50000&useCursorFetch=true" \
--driver com.mysql.jdbc.Driver \ # Hadoop根目录
--username ##### \ ## 连接mysql的用户名
--password ##### \ ## 连接mysql的密码
--query \ ## 构建表达式执行
"select * from dim_date_df where "'$CONDITIONS'" " \ ##注意:必须要加上where"$CONDITIONS", 否则报错
--fetch-size 50000 \ ## 一次从数据库读取 n 个实例,即n条数据
--hive-table ods.dim_date_df \ ## 创建dim_date_df表(默认也会自动创建表)
--hive-drop-import-delims \ ## 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符
--delete-target-dir \ ## 如果目标文件已存在就把它删除
--target-dir /user/hadoop/sqoop/dim_date_df \ ## 指定的目录下面并没有数据文件,数据文件被放在了hive的默认/user/hadoop/sqoop/dim_date_df下面
-m 1 ## 迁移过程使用1个map(开启一个线程)
2 数据统计分析
导入数据后,我们就可以根据业务指标需求来做数据统计分析了,Hive的最大优势在于对窗口函数使用(mysql 8.0也加入了窗口函数),HQL的窗口分析函数的功能主要用来做数据统计分析的,典型分析应用包括:
- 按分区聚合(排序,top问题)
- 行间计算(时间序列分析)
- 关联计算(购物篮分析)
这里我们以项目中订单明细表统计2019年1-12月的累积产品销量为例,来展示Hive如何用窗口函数满足日常业务中统计分析需求,HQL代码语句如下:
SELECT
date_format(create_date,'YYYY-MM') as umonth,
count(sales_order_key) AS month_amount,
SUM(count(sales_order_key)) OVER (ORDER BY date_format(create_date,'YYYY-MM') ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_amount
FROM ods.ods_sales_orders
WHERE year(create_date) = '2019'
GROUP BY date_format(create_date,'YYYY-MM')
ORDER BY umonth ;
3 数据仓库的建立及数据聚合
在上述分析中,我们已经指出了实际业务中需要自主分析一些分析指标,接着在hive数据库中来做数据聚合表,表聚合后再到导出操作。 下面是shell脚本的简要代码,用来做聚合的HIVESQL语句,从ods库的时间地区产品等表抽数据做聚合整理。
hive -e "drop table if exists ods.dw_order_by_day" ## 删除原有的旧表
hive -e " ## hive创建表的语句
CREATE TABLE ods.dw_order_by_day(
)
"
## 这里是hive的查询语句,因为做聚合需要关联多张表做聚合,这里使用with查询来提高查询性能
hive -e "
with
dim_date as
(),
ods_cus as
()
## 查询的数据插入表中
insert into ods.dw_customer_order
select
"
这里的hivesql中运用了with as,with as 叫做子查询部分,也是HQL中重要查询语言,首先定义一个sql片段,该sql片段会被整个sql语句所用到,为了让sql语句的可读性更高些,作为提供数据的部分,也常常用在union等集合操作中。 with as就类似于一个视图或临时表,可以用来存储一部分的sql语句作为别名,不同的是with as 属于一次性的,而且必须要和其他sql一起使用才可以! 其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,这可以大大的简化SQL;更重要的是:一次分析,多次使用。
4 Sqoop导出分析结果到mysql的操作
Sqoop Export 导出:将数据从Hadoop(如hive等)导入关系型数据库导中
- 步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
- 步骤2:并行导入数据:
- 将Hadoop上文件划分成若干个split;
- 每个split由一个Map Task进行数据导入
下面是shell运行脚本:
sqoop export \
--connect "jdbc:mysql://IP:3306/数据库名?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&dontTrackOpenResources=true&defaultfetchSize=50000&useCursorfetch=true" \
--username ####\ ##数据库账号
--password #### \##数据库密码
--table dw_order_by_day \ ##mysql数据库建好的表
--export-dir /user/hive/warehouse/ods.db/dw_order_by_day \ #hive数据库数据路径,这个用show create table ods.dw_order_by_day 可以查看hive表的路径
--input-null-string "\\\\N" \
--input-null-non-string "\\\\N" \
--input-fields-terminated-by "\001" \
--input-lines-terminated-by "\\n" \
-m 1