是科研人就要快!加速你的算法!
在科研中,大多数论文其实还是看精度和效果的,对于速度其实没有那么高的追求,很多人用速度评价自己算法的复杂度很低,但实际上这是不准确的,当然在精度占优的情况下,能够提高速度,给自己的实验结果增彩。

关于算法程序的加速,在动手前先要按照如下流程进行思考,以决定从哪里入手加速。
- 算法优化,指降低算法计算复杂度,设计新算法快速求解,比如Hungarian匹配算法。或牺牲一些内存,预计算一些重复计算的过程,减少程序层面的复杂度。
- 语言更换,指将自己算法迁移到更加底层的算法,越是低级的算法,执行速度越快。常见地,将Matlab、Python等解释性代码移植到C++平台,往往有5-20倍的加速效果。
- 算法并行,指将自己算法的独立计算部分,分成几块,利用CPU指令集、多核或GPU的特性实现加速。多核并行和CUDA并行最为常见。
- 汇编加速,将自己的一片代码指定为自己设计的汇编语言。多种C++编译器实际上也是将语言转换为汇编代码,对汇编进行加速在嵌入式中常见。(该方法对平台有需求,并不常见)
- 硬件加速,利用特殊硬件处理特殊算法,降低CPU架构的复杂度。常见的就是FPGA。
- 光学加速,利用参数制作特定的光散射模型,输入目标光源直接得到输出结果。(离谱的加速方式,目前停留在概念)

强烈注意:
所有的优化,都是在自己算法流程不变的前提下进行优化,因为优化后的程序,高度面向过程,如果算法某个流程要换以达到更高精度,则改动工作量较大。

下面我对每种加速方法进行详细的说明(本文只列举加速方法,并给出几种参考示例,并不会详细讲解如何使用,仅介绍思想)。
加速方法详解
- 1 算法优化
- 2 语言更换
- 3 算法并行
-
- 3.1 指令集加速
- 3.2 CPU 多核编程
- 3.3 CUDA 编程加速
- 3.4 TensorRT 加速深度学习
- 4 汇编加速
- 5 硬件加速
- 6 光学加速
- 7 总结
1 算法优化
算法优化分为两种类型:① 降低算法复杂度;② 减少重复计算过程。
- 降低算法复杂度。在求解最优值时候,我们最容易想到的就是暴力求解。当数据量特别大的时候,这种方法耗时就异常高。在查找、最有匹配中,有大量的优化算法解决这类问题(图论、数据结构、算法导论介绍了很多方法)。 \newline 例如,匈牙利算法(Hungarian Algorithm)与KM算法(Kuhn-Munkres Algorithm)是在多目标跟踪的论文中见到的两种算法。他们都是用来解决多目标跟踪中的数据关联问题。匈牙利算法与KM算法都是为了求解二分图的最大匹配问题。下图就是其中的二分图,二分图呢就是能分成两组,U,V。其中,U上的点不能相互连通,只能连去V中的点,同理,V中的点不能相互连通,只能连去U中的点。这样,就叫做二分图。在图像中,可以把二分图理解为视频中连续两帧中的所有检测框,第一帧所有检测框的集合称为U,第二帧所有检测框的集合称为V。同一帧的不同检测框不会为同一个目标,所以不需要互相关联,相邻两帧的检测框需要相互联通,最终将相邻两帧的检测框尽量完美地两两匹配起来。而求解这个问题的最优解就要用到匈牙利算法或者KM算法。

- 减少重复计算过程。这个一般来说具体算法具体分析,一般要么是记录共用的中间变量,要么就是把与输入无关的数据,在初始化变量时候计算好。简单来说,拟合参数时候,我们经常会用到公式 A x = b Ax=b Ax=b的形式,即 x = ( A ′ A ) − 1 A ′ b x=(A'A)^{-1}A'b x=(A′A)−1A′b,这时候,定义 A = ( a 1 , a 2 , . . . , a n ) ′ A=(a_1,a_2,...,a_n)' A=(a1,a2,...,an)′,那么 A ′ A = ∑ i = 1 n a 1 T a 1 A'A=\sum_{i=1}^na_1^Ta_1 A′A=∑i=1na1Ta1的形式,如果能预计算 a 1 T a 1 a_1^Ta_1 a1Ta1的话,每次获得这个矩阵经过有限次加法即可。
2 语言更换
越是高级的语言,开发效率越高,执行速度越慢。
- 尽量用当前语言的官方库,官方库往往对算法做了足够的加速。
- 将部分简单函数编译成C++进行调用,比如Python调用C++,或Matlab调用C++。
- 对并行性较强的,且用了少量STL库的算法使用CUDA加速。
- 大矩阵运算考虑Eigen,cublas等专用库。
- 对并行性较强,且用了大量STL库的算法使用多核并行加速。
- 将高级代码转换为C++项目,这也是最简单的转换方法了,这样开发出的算法非常容易落地。
3 算法并行
并行思想从小到大可以总结为:指令集开发→多核并行→CUDA并行,在深度学习中,TensorRT是一种更高级的CNN网络加速方法。
3.1 指令集加速
指令集加速,一般是针对CPU架构进行的底层优化,常见于OpenCV和Tensorflow的CPU版本。之所以OpenCV是个经典的开源图像框架,很大原因是因为其在多个平台上执行效率很高,其中底层的优化,比如指令集优化,起到了关键作用。
数据并行的两种实现在计算机体系中,数据并行有两种实现路径:
- MIMD(Multiple Instruction Multiple Data,多指令流多数据流)。MIMD的表现形式主要有多发射、多线程、多核心,在当代设计的以处理能力为目标驱动的处理器中,均能看到它们的身影。
- SIMD(Single Instruction Multiple Data,单指令流多数据流)。随着多媒体、大数据、人工智能等应用的兴起,为处理器赋予SIMD处理能力变得愈发重要,因为这些应用存在大量细粒度、同质、独立的数据操作,而SIMD天生就适合处理这些操作。SIMD本身并不是一种指令集,而是一种处理思想,现在的一些指令集都支持SIMD。(简单来说,计算1000维向量的点积,乘法是独立的,多核心不值得,这时候就可以利用指令集一次性计算4次或8次乘法,同样的,之后的加法也同样可以用指令集计算)
CPU指令集的发展(针对Intel的x86指令集系列):
- MMX指令集 (Multi Media eXtension, 多媒体扩展指令集)。MMX指令集率先在Pentium处理器中使用,MMX指令集支持算数、比较、移位等运算,MMX指令集的向量寄存器是64bit。
- SSE指令集(Streaming SIMD Extensions,单指令多数据流扩展),所有的SSE系列指令的向量寄存器都是128bit,也就是一次性可以计算4个int。SSE最早出现在1999年,在之后的近10年内,推出了SSE,SSE2,SSE3,SSE4.1,SSE4.2。
- AVX指令集(Advanced Vector Extensions,高级向量扩展)。AVX指令集是在之前的SSE128位扩展到和256位的单指令多数据流。AVX出现在2008年,之后出了AVX2,2014年,AVX-512将数据bit由256bit扩展到了512bit。AVX是目前比较常用的指令集,256位的类型可以一次计算4个double,有效的提升性能。
利用CPU-Z软件可以查看电脑的CPU信息,

关于指令集的使用,在博客《论文阅读——椭圆检测 2020:Arc Adjacency Matrix-Based Fast Ellipse Detection》给出的源码中,使用了AVX指令集对代码进行处理,为了方便理解使用,我们以计算椭圆的采样点为例,其中 x o , y o , R , r , θ x_o,y_o,R,r,\theta xo,yo,R,r,θ分别为椭圆的中心点、长短轴及旋转角。 c o s t , s i n t cost,sint cost,sint表示椭圆参数方程用于采样。指令集的文档参考Intel® C++ Compiler XE 12.1 User and Reference Guides 。
{ x = R c o s θ c o s t − r s i n θ s i n t + x o y = R s i n θ c o s t + r c o s θ s i n t + y o \left\{\begin{array}{l}x = Rcos\theta cost-rsin\theta sint + x_o\\y = Rsin\theta cost + r cos\theta sint + y_o\end{array}\right. { x=Rcosθcost−rsinθsint+xoy=Rsinθcost+rcosθsint+yo
则利用指令集计算采样点的方法如下所示,显然原来需要计算VALIDATION_NUMBER次采样点的过程,现在仅需要VALIDATION_NUMBER/8次(sizeof(__m256) / sizeof(float)=8)。
// 初始化旋转变换矩阵,这里angleRot = \theta
const float _ROT_TRANS[4] = {
R * cos(angleRot), -r * sin(angleRot),
R * sin(angleRot), r * cos(angleRot) };
// Estimate the sampling points number N. Note: N = RoundEllipseCircum;
// Use SSE to faster the step of ellipse validation.
// 考虑到指令集实际上一次性计算8个数据,
// 则_mm256_set1_ps的目的是用一个float初始化一个__m256
// 举个例子:假如需要初始化的float为k,则调用_mm256_set1_ps之后得到
// [k,k,k,k,k,k,k,k]
__m256 _rot_trans_0 = _mm256_set1_ps(_ROT_TRANS[0]),
_rot_trans_1 = _mm256_set1_ps(_ROT_TRANS[1]),
_rot_trans_2 = _mm256_set1_ps(_ROT_TRANS[2]),
_rot_trans_3 = _mm256_set1_ps(_ROT_TRANS[3]);
__m256 x_center = _mm256_set1_ps(xyCenter[0]),
y_center = _mm256_set1_ps(xyCenter[1]);
__m256 tmp_x, tmp_y, tmp_wx, tmp_wy, tmp_w;
for (int i = 0; i < VALIDATION_NUMBER; i += sizeof(__m256) / sizeof(float))
{
// 一次性读取256位数据,实际上就是加载8个float到base_x,base_y
// 这里的base_x = cost, base_y = sint
__m256 base_x = _mm256_load_ps(vldBaseDataX + i);
__m256 base_y = _mm256_load_ps(vldBaseDataY + i);
// calculate location x
// _mm256_mul_ps 计算乘法:计算每个float的乘法,_mm256_add_ps
// 举个例子:两个__m256数据为[k1,k2,...,k8], [p1,p2,...,p8]
// 调用_mm256_mul_ps之后,得到[k1p1,k2p2,...,k8p8]
// 调用_mm256_add_ps之后,得到[k1+p1,k2+p2,...,k8+p8]
tmp_x = _mm256_add_ps(
_mm256_mul_ps(_rot_trans_0, base_x),
_mm256_mul_ps(_rot_trans_1, base_y));
tmp_x = _mm256_add_ps(tmp_x, x_center);
// calculate location y
tmp_y = _mm256_add_ps(
_mm256_mul_ps(_rot_trans_2, base_x),
_mm256_mul_ps(_rot_trans_3, base_y));
tmp_y = _mm256_add_ps(tmp_y, y_center);
// Save location x, y
// _mm256_storeu_ps的目的是将计算后的8个float存入float矩阵中
_mm256_storeu_ps(sample_x + i, tmp_x);
_mm256_storeu_ps(sample_y + i, tmp_y);
}
其实后期测试速度发现,实际加速效果没有特别明显,毕竟用了大量中间变量,且函数的调用传递了参数,指令集实际上在汇编中用的多,如果在代码中内嵌指令集可能效果会更好。
参考资料:
1 C/C++指令集介绍以及优化(主要针对SSE优化)
3.2 CPU 多核编程
多核编程可以理解为就是多线程编程,总体上可以分为三个部分:OpenMP并行,opencv并行和多线程并行。在设计相关代码时候,切记变量可以被多个线程访问,但同一时间只能被一个线程修改,如果多个线程想修改同一个变量,可使用原子操作或加锁。 当然,多核编程不止这些,还有tbb,mkl等等。
- OpenMP 并行。这种并行办法是最简单的一种并行方法,直接在for循环前面添加
#pragma omp parallel for即可,程序会自动将for循环分解。值得注意的是,该方法是在for循环前开始创建线程,结束后并销毁,这个过程会产生一些时间消耗,大约在3-5ms之间,做实时性应用开发的时候需要注意这个问题。下面给出了一个并行示例。当然openmp有多种操作函数,感兴趣去找对应的开发教程即可。
#include - OpenCV 并行。 OpenCV提供了一种并行计算函数
parallel_for_,内部集成多种并行框架。在c++11中,可以不必定一个类去继承并行计算循环体类ParallelLoopBody,可以直接使用。
#include - 多线程并行。上述的两种方法是针对一个for循环来解决的,但是整个算法不可能就由一个for循环构成,如果每个for循环都这么做的话,创建线程的开销巨大,因此,多线程并行主要就是解决这类问题的。初始化时候创建好线程,之后主线程串联算法,子线程解决for循环问题,线程可能会使用同步,加锁等手段逐步执行,最终获得输出结果。创建多线程时候,系统本身就会将不同线程分到不同核心上,有自己的调度手段,所以该方法加速效果很明显,就是过于面向过程,不方便后续的改进。
参考资料:
1 opencv 并行计算函数 parallel_for_的使用
3.3 CUDA 编程加速
CUDA加速其实是最好的加速手段,CUDA最大的特性就是核心数特别多,一般是几千个,相比于CPU,加速倍数高达20-200倍之间。特别是推出的Jetson NX系列嵌入式卡,核心数在128-512之间,推进了更多算法的落地应用。

如果想学习CUDA,我非常推荐下真本书,基础的都涵盖了,看完之后基本就能动手写程序了。

CUDA开发主要还是有C语言风格,C++用的很少,切记一点避免在CUDA中动态分配内存,最好通过参数传递内存指针。
下面给出一个向量加法示例,来简单说明CUDA的用法。
#define N (33*1024)
// 核函数就是表示每个CUDA核心执行的函数,用关键字__global__ 表示
__global__ void add(int *a,int *b,int *c)
{
int tid = threadIdx.x + blockIdx.x*blockDim.x;
while(tid < N){
c[tid] = a[tid] + b[tid];
tid += blockDim.x*gridDim.x;
}
}
int main(void)
{
int a[N],b[N],c[N];
int *dev_a,*dev_b,*dev_c;
//在GPU上分配内存
cudaMalloc((void**)&dev_a,N*sizeof(int));
cudaMalloc((void**)&dev_b,N*sizeof(int));
cudaMalloc((void**)&dev_c,N*sizeof(int));
//在CPU上为数组'a'和数组'b'赋值
for(int i=0;i<N;i++){
a[i] = i;
b[i] = i*i;
}
//将数组‘a’和数组‘b’复制到GPU内存中
cudaMemcpy(dev_a,a,N*sizeof(int),cudaMemcpyHostToDevice);
cudaMemcpy(dev_b,b,N*sizeof(int),cudaMemcpyHostToDevice);
add<<<128,128>>>(dev_a,dev_b,dev_c);
//将数组‘C’从GPU复制到CPU中
cudaMemcpy(c,dev_c,N*sizeof(int),cudaMemcpyDeviceToHost);
//验证GPU计算结果
for(int i=0;i<N;i++){
if(a[i]+b[i] != c[i]){
printf("error:%d+%d=%d\n",a[i],b[i],c[i]);
}
}
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
我曾经加速过经典导向滤波程序WGIF算法,导向滤波核心是以每个像素为核心,根据周围像素做滤波处理,在原始Matlab上的运算速度大约是20s左右,经过CUDA加速后,仅需要80ms即可跑完一张图片。

在CPU上多线程开发遇到的一些同步、线程通信问题CUDA下都有。
对于一些常数内存,也就是不需要被修改的内存,CUDA给了很多种形式用于快速访问:
- 常量内存,限制为64kb
- 纹理内存,多数应用于二维矩阵的访问。
当然,更加详细的用法,去看书即可,这里只是简单介绍。
3.4 TensorRT 加速深度学习
TensorRT早期叫法叫GIE (GPU Inference Engine, GPU推理引擎),从名字上就知道这个东西用于推理(也就是测试过程),Tensor可以理解为高维数组。在TensorRT中,所有的数据都被组成最高四维的数组,如果对应到CNN中其实就是 { N , C , H , W } \{N, C, H, W\} { N,C,H,W},N表示batch size,即多少张图片或者多少个推断(Inference)的实例;C表示channel数目;H和W表示图像或feature maps的高度和宽度。RT表示的是Runtime。
在深度学习的落地应用中,主要就是输入图片,推断结果,模型如果做得不好,没有做优化,可能需要500多ms才推断完一张图片,延迟较高,导致系统灵活性变弱。下图红色部分指的就是TensorRT要干的事。

推断的几种特性:
- 网络权值已经固定下来,无后向传播过程,因此可以:
- 模型固定,可以对计算图进行优化
- 输入输出大小固定,可以做memory优化
- batch size要小一些,GPU利用率可能低些。
- 可使用低精度技术推断,深度学习网络参数一般为
float32类型,这也是最小的浮点类型。很多研究表明可以用低精度,如半长(16)的float类型FP16,也可以用8位的整型(INT8)来做推断,研究结果表明没有特别大的精度损失,尤其对CNN。二值权值目前也在研究中。只不过FP16和INT8的研究使用相对来说比较成熟。低精度推断的优点很明显:速度快、内存低。
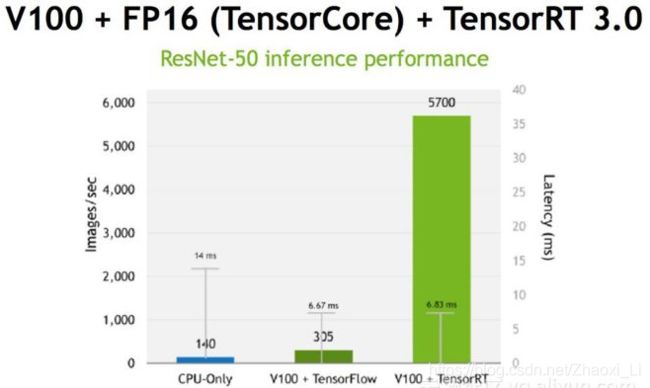
而TensorRT所做的优化,主要有以下几点:
- 合并了一些固定顺序层,比如合并了卷积层、batchnorm层和激活层,取名为CBR层。
- 取消无用层,比如concat层,实际上就是拼接特征,这里做了优化。
- TensorRT在多种嵌入式设备都提供了驱动支持。
下面给出的一种网络,就非常适合用TensorRT优化。

总的来说,尽管TensorRT做了很多优化,但加速效果普遍在20%左右,做好剪枝或改变数据类型可以提升2-3倍的性能。TensorRT只是在计算上优化了,想变得更快还是得想办法设计出一个更加轻量的网络。
参考资料:
1 高性能深度学习支持引擎实战——TensorRT
4 汇编加速
用汇编加速的方法往往指的是C/C++与汇编混合编程,尽管多种编译器均有优化等级选项,但是越是高级的语言,时间损耗越多。
什么时候使用汇编加速呢? 一般有两种情况需要嵌入汇编代码:
- ① 升级项目,项目原始版本是汇编代码,现在需要用C++开发,重写汇编代码注定耗时,直接调用汇编是个很好的解决方案。
- ② 不同的语言对算法一半都有特定的处理方法,比如Matlab之类尽量使用矩阵运算,C++尽量使用指针访问等,如果有个频繁调用的算法,在汇编上有独特的计算方法,那么直接在C++调用这个汇编函数,可以达到加速效果。
如何嵌入汇编代码呢? 方法很简单,使用关键字__asm来加入一段汇编语言的程序,C++下具体的格式为:__asm{ 指令 [;指令] /* comments */ ... 指令}
在C语言下,格式为:
asm [ volatile ] (
assembler template
[ : output operands ] /* optional /
[ : input operands ] / optional /
[ : list of clobbered registers ] / optional */
);
下面给一个示例(VS x64似乎不支持汇编扩展,我仅仅是见别人的算法中用过,自己没开发过)。
#include 5 硬件加速
前面介绍了各种通过编程加速的方法,核心是将算法进行并行化处理,总的来说
- 多核并行,启动并行时需要开多线程,需要少量的时间(<10ms),因此仅适用耗时较长的算法(>100ms)的并行。
- CUDA并行,算法不可避免串行过程,因此许多时间在内存和显存之间的拷贝。
- CPU指定集,小规模加速,但仅限于各种基本运算操作(加减乘除、位运算等)。
如今,FPGA是日趋热门的一种加速方法,与软件加速不同,该方法是直接将算法设计在电路上,变成专有模块进行并行。

FPGA是目前新的一种低功耗加速设备,虽然通用的CPU主频很高,但做某个特定运算(如图像处理中的Sobel)可能需要很多个时钟周期;而FPGA可以通过编程重组电路,直接生成专用电路,加上电路并行性,可能做这个特定运算只需要一个时钟周期。举例来说,CPU主频3GHz,FPGA主频500MHz,若做某个特定运算CPU需要15个时钟周期,FPGA只需一个,则耗时情况: CPU:15/3GHz =5ns; FPGA:1/500MHz =2ns。可以看到,FPGA做这个特定运算速度比CPU块,能帮助加速。
以图像处理中常见的Sobel算法来说,在FPGA上的实现可以参考A FPGA based implementation of Sobel edge detection,达到这个速度已经可以与opencv的sobel速度媲美了。

在一些经典算法中,比如椭圆检测,也是可以利用FPGA的,比如论文《Effective ellipse detection method in limited-performance embedded system》,就是FPGA和DSP的一种结合,利用FPGA进行预处理,利用DSP处理串行操作,以实现实时处理。

6 光学加速
目前来说,显卡的性能受制于能耗和物理极限,每次更新换代,感觉并没有那么高的性能提升,多卡缓解这类问题,但是功耗实在太大。
而光衍射深度神经网络,提出了一种非常新奇的思想。Science发表了加州大学洛杉矶分校(UCLA)研究人员的最新研究:All-optical machine learning using diffractive deep neural networks,他们使用 3D 打印打造了一套 “全光学” 人工神经网络,可以分析大量数据并以光速识别目标。它使用来自物体的光散射来识别目标。研究团队先用计算机进行模拟,然后用 3D 打印机打造出 8 平方厘米的聚合物层。每个晶圆表面都是不平整的,目的是为了衍射来自目标的光线。
以手写数字识别为例,设计了一个五层的DNN,训练之后测试,实现了91.75%的分类精度。根据这些数值结果,我们将这个5层的DNN 设计3D打印出来,每一层的面积为8cm×8cm,然后在衍射网络的输出平面定义10个检测器区域。

光学电路深度学习是一项重大突破,光的延迟非常低,所需的功耗也是极低,如果未来的加工工艺更加成熟,未来将是一个非常帮的突破。
参考资料:
1 Science重磅!用光速实现深度学习,跟GPU说再见
7 总结
我认为作为科研工作者,应该掌握一些基本的加速方法,比如多线程、CUDA之类。很多专业,跑一些算法,用Matlab跑好几分钟甚至好几个小时才能出结果,大大降低了科研效率。这些开发语言完全可以套上C++的外壳进行加速。
在工业机械领域,很看重实时性,如果自己设计出的算法效果又好,又能落地,那多完美。
当然,大多数的加速方法破坏了面向对象这个性质,高度过程化。所以,一般是当自己的程序确定不改了,实验做完了,再去考虑加速,让你的效果更上一层楼。