作者:数据分析不是个事儿
链接:https://www.jianshu.com/p/fa5e96eb2476
来源:
一个完整的数据分析都需要经历这样几个步骤:
1、数据获取——这里我已经用Python爬好了;
2、明确分析目的——你拿这数据要得到什么信息,解决什么问题;
3、观察数据——各个数据字段的含义,中英文释义;
4、数据清洗——无效值、缺失值、重复值处理,数据结构是否一致等;
5、分析过程——围绕目的展开分析;
6、制作可视化——做图表做可视化报告。
一、明确目的
数据分析的大忌是不知道分析的方向和目的,拿着一堆数据不知所措。数据用来解决什么问题?
是进行汇总统计制作成报表?
是进行数据可视化,作为一张信息图?
是验证某一类业务假设?
是希望提高某一个指标的KPI?
要知道一切数据分析都是以业务为核心目的,所以要找到业务问题的思考点。关于找到问题的切入点,之前数据分析思维篇讲过。永远不要妄图在一堆数据中找结论,目标在前,数据在后,哪怕是把数据做个平均值比较,也比没有方向好。每一步尝试都会引发进一步思考,比如为什么这个值这么低,原因在哪里,这个差异波动有何规律……
假设我是一个BI工程师,我想知道:
目前BI工程师的平均薪资水平如何,薪资的区间分布如何
各地区对BI工程师的需求量是多少,哪些地区设岗最多。
不同年限的BI工程师薪资差异如何,3年后我差不多是什么样的价位?
薪水较高的公司有哪些?
带着这样的问题,那我们的分析就有了方向,后续则是将目标拆解为实际分析展示的过程。
二、了解数据概况
拿到数据肯定是要先看一下的,你想要的数据全不全,拿到的数据有哪些可分析之处。主要就是看数据字段,要了解数据字段的含义:
JobName——岗位名称
Company——公司名
Salary——薪水
City——城市
Jobtype——岗位领域
Edulevel——学历要求
WorkingExp——工作年限要求
三、数据清洗
接下来进行数据清洗。数据清洗一般包括无效值、缺失值、重复值处理;数据是否有乱码,错位现象;数据口径问题,两张表的关联ID名是否一致;还有是否有统一的标准或命名,如公司名全写或缩写的区分。数据转换则是将数据规整为统一格式处理。因为这是只是Excel级别的数据分析,且就一张简单的数据表,不会有太多复杂的操作。这里简单总结下。
1、有无缺失值
数据的缺失会很大程度影响分析结果。数据缺失的原因很多,比如数据采集的时候,因为技术的原因,爬虫没有完全抓去。但工作上更多的原因是数据入库的时候就没有收集全,有没填有遗漏,这又是数据规范数据治理的话题了。一般来说,如果某一字段数据缺失超过40%~50%,就没有分析意义了,考虑删除或作其他措施。
看数据有没有缺失,只要在Excel中选中该列看计数。
2、脏数据处理
发现jobName列里面有一些类似BIM工程师的岗位信息,这些应该都是土木行业的工程师,爬去时没做过滤,还有包含“bim”“BIOS””BIW”等字段。
因为包含多重过滤,这里我建立辅助列,设立判断条件,然后进行筛选过滤。
3、重复数据
重复数据一般对唯一标识字段来处理,比如用户ID,订单ID,公司ID这些,这些字段都代表这一行数据是唯一存在的。严格来讲,这里的表应该存在公司ID这一字段,爬取数据的问题,我这就懒得再重爬了,就对Company字段做重复值处理。
这里有一个快速窍门,使用Excel的删除重复项功能,快速定位是否有重复数据。对company列进行重复项删除操作:
。只剩下562个值了。到此,一些脏数据基本清理的差不多了。
最后,salary有一些数据是“薪资面议”,“校招”的,这里也一并过滤掉。Jobtype过滤掉汽车、电子等行业,只留包含IT互联网行业,最后剩下不到500条数据。
4、数据再加工
一者是salary薪水用了几K表示,这是文本,不能直接用于计算。而且还是一个范围,后续得按照最高薪水和最低薪水拆成两列。
二者由于城市字段存储有的数据为“城市-区域”格式,例如“上海-徐汇区”,为了方便分析每个城市的数据,最后新增列“城市”,截取“-”前面的真实城市数据。
为了方便整理,和原数据区分,也防止原数据丢失,这里把之前处理的数据复制粘贴到另一张表里。
① 薪水处理
将salary拆成最高薪水和最低薪水有三种办法。
一是直接分列,以"-"为拆分符,得到两列数据,然后利用替换功能删除 k这个字符串。得到结果。
二是自动填充功能,填写已填写的内容自动计算填充所有列。
三是利用文本查找,重点讲一下这个。
写公式的思路是,先查找第一个K出现的位置,然后再-1,去除掉K。所以公式是:
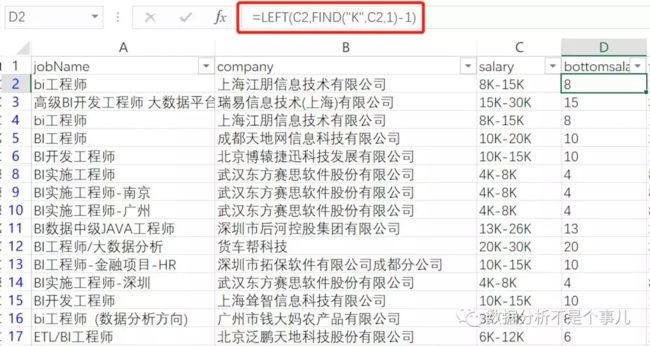
同样的思路,最高薪水需要利用find查找"-"位置,然后截取 从"-" 到最后第二个位置的字符串。
=MID(C2,FIND("-",C2,1)+1,LEN(C2)-FIND("-",C2,1)-1)
这里,在新增数据列,平均薪水,来近似代表实际的准确薪资。平均薪水=(薪水下限+薪水上限)/2,即可得到每个岗位的平均薪水。
②真实城市截取
由于城市字段存储有的数据为“城市-区域”格式,例如“上海-徐汇区”,为了方便分析每个城市的数据,最后新增列“城市”,截取“-”前面的真实城市数据。
=IF(COUNTIF(G2,"*-*")=0,G2,LEFT(G2,FIND("-",G2,1)-1))
至此,所有数据清洗加工完毕,食材已经全部准备好,下面可以正式开始数据可视化的美食下锅烹饪了。
四、分析过程
分析过程有很多玩法,因为这里主要数据均是文本格式,数据又很简单,所以偏向汇总统计的计算。如果数值型的数据比较多,就会涉及到统计、比例等概念。如果有时间类数据,那么还会有趋势、变化的概念。
整体分析使用数据透视表完成,先利用数据透视表获得汇总型统计。

北上广深的BI工程师岗位远多于其他城市,成都杭州武汉梯队次之。1~3年以及3~5年经验的缺口相当大。
2、BI工程薪资情况分析
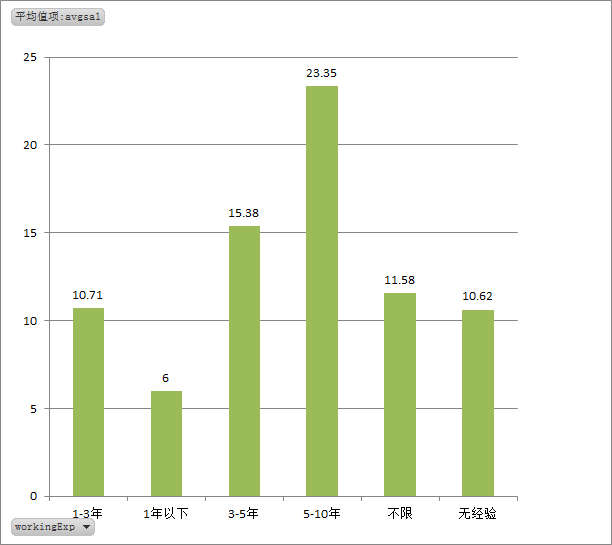
各经验年龄的平均薪资状况,差距梯度还是很明显的