RDD编程实验
RDD编程初级实践
基于《Spark编程基础(Scala版)》
目录
- RDD编程初级实践
- 前言
- 一、实验目的
- 二、实验内容和要求
- 三、实验步骤
-
- 1.spark-shell交互式编程
-
-
- (1)该系总共有多少学生;
- (2)该系共开设了多少门课程;
- (3)Tom同学的总成绩平均分是多少;
- (4)求每名同学的选修的课程门数;
- (5)该系DataBase课程共有多少人选修;
- (6)各门课程的平均分是多少;
- (7)使用累加器计算共有多少人选了DataBase这门课。
-
- 2.编写独立应用程序实现数据去重
-
- 下载IDEA
- 进行环境配置
-
- 1.安装scala插件
- 2.创建maven工程
- 根据题目编写程序
- 打包scala程序
-
- 配置pom.xml
- 自动打包提交集群代码
- 开始运行
- 四、实验中遇到的问题及解决
- 五、实验心得
前言
前面已经基于docker搭建好spark集群,集群为一台master和两台slave,主机为windows系统,集群搭建在linux下。
一、实验目的
1.熟悉Spark的RDD基本操作及键值对操作;
2.熟悉使用RDD编程解决实际具体问题的方法。
二、实验内容和要求
1.spark-shell交互式编程
2.编写独立应用程序实现数据去重
3.编写独立应用程序实现求平均值问题
三、实验步骤
1.spark-shell交互式编程
数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
根据给定的实验数据,在spark-shell中通过编程来计算以下内容:
(1)该系总共有多少学生;
登陆spark并打开spark-shell:
./bin/spark-shell
执行以下代码:
val lines=sc.textFile("/test/Data1.txt")//打开文件
val par=lines.map(row=>row.split(",")(0))//切分取第一数值
val distinct_par=par.distinct()//去重
distinct_par.count//输出
输出结果如下:
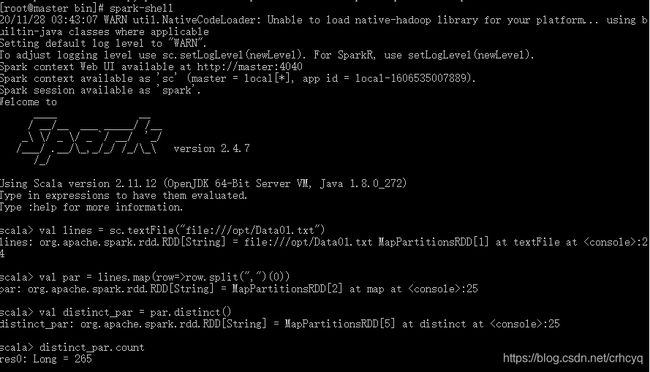
答:该系总共有265名学生。
(2)该系共开设了多少门课程;
执行如下代码:
val par=rdd.map( row=>row.split(",")(0))
var count=par.distinct()
println("学生总人数:"+count.count())
结果如下:

答:该系共开设了8门课程。
(3)Tom同学的总成绩平均分是多少;
执行如下代码:
val Tom=input.filter(t => t.split(",")(0) == "Tom")//找到tom
val Tom_1=Tom.map(t => (t.split(",")(0), (t.split(",")(2).toInt,1)))//构造一种数据结构(Tom,(成绩,1)),这样的话我们就可以得到Tom的总课程成绩以及总课程门数
val Tom_2=Tom_1.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))//将上面得到的(成绩,1)全部加起来
Tom_2.mapValues(a=>a._1/a._2).first()//将总成绩除以总课程数
结果如下:
![]()
答:平局分是30。
(4)求每名同学的选修的课程门数;
代码如下:
scala> input.map(t=>(t.split(",")(0), (t.split(",")(1),1))).reduceByKey((a,b)=>(a._1,a._2+b._2)).mapValues(a=>a._2).foreach(println)
(Bartholomew,5)
结果如下:
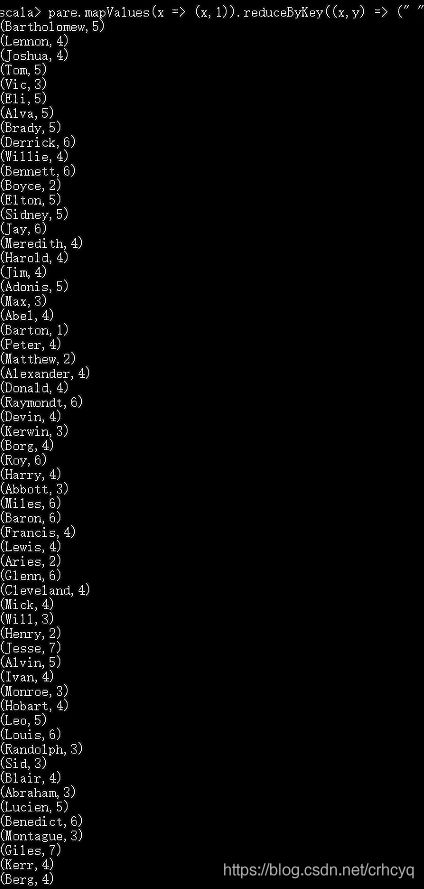
(5)该系DataBase课程共有多少人选修;
代码:
scala> input.filter(t => t.split(",")(1)=="DataBase").count()
结果如下:

答:共有126人选修。
(6)各门课程的平均分是多少;
代码如下:
input.map(t=>(t.split(",")(1), (t.split(",")(2).toInt,1))).reduceByKey((a,b)=>(a._1+b._1,a._2+b._2)).mapValues(a=>a._1/a._2).foreach(println)
结果:
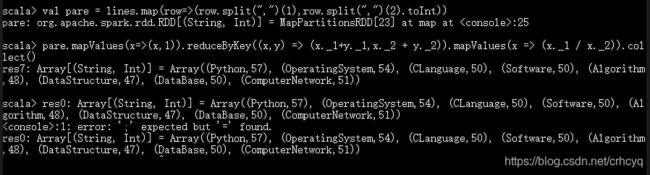
(7)使用累加器计算共有多少人选了DataBase这门课。
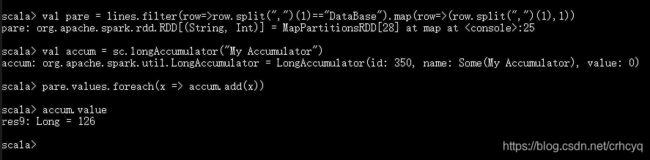
代码如下:
val database=input.filter(t=>t.split(",")(1)=="DataBase").map(t=>(t.split(",")(1),1))//过滤出Database
val counter=sc.longAccumulator("database_counter")//构造累加器
database.values.foreach(a=>counter.add(a))
counter.value
结果:
该处使用的url网络请求的数据。
2.编写独立应用程序实现数据去重
下载IDEA
进入官网:http://www.jetbrains.com/idea/,下载windows版本的IntelliJ IDEA
进行环境配置
1.安装scala插件
进入settings->plugins下载scala插件
2.创建maven工程
1.选择Maven
注意这里可以选择java版本
2.填写信息
3.新建scala文件夹,并设置为源目录
4.添加scala支持

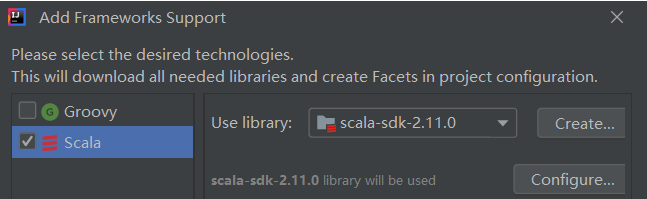
5.新建scala文件

根据题目编写程序
1.数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
输入代码如下:
val sc = new SparkContext(conf)
val dataFile ="E:\\C\\Desktop\\text1.txt,E:\\C\\Desktop\\text2.txt"
val data = sc.textFile(dataFile,2)
val da = data.distinct()
da.foreach(println)
da.saveAsTextFile("E:\\C\\Desktop\\c.txt")
println("文件合并完成!")
结果:

2.求平均值
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
代码如下:
val sc = new SparkContext(conf)
val inputfile="file:///usr/local/spark/mycode/exercise43/data.txt"
val textFile=sc.textFile(inputfile)
val qc=textFile.map(line=>(line.split(" ")(0),line.split(" ")(1).toInt)).mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).mapValues(x=>(x._1/x._2)).collect().foreach(println)
结果出错了,到现在我还没有解决,具体原因如下
![]()
一开始我以为是依赖版本问题,后来发现不是,我上网也找不到原因。。。。实在是没头绪。
打包scala程序
配置pom.xml
下面给出一些常见的Maven依赖
这里给出说明,下面依赖中的spark,scala,hadoop的版本号具体的限制没有那么严格,不一定要标准的使用自己的版本号,在第一次将依赖写入的时候,会下载比较长的时间,当代码里面没有语句标红之后证明依赖全部导入。
可能有些人在写入自己的版本号之后,会发现有些语句会一直标红,这证明没有你输入版本号组合的相应的依赖包,这个时候需要适当调整版本号,下面给出的版本号的组合是可以使用的,如果改成你自己的版本号无法使用,可以尝试下面给出的版本号组合
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>sparkgroupId>
<artifactId>testartifactId>
<version>1.0-SNAPSHOTversion>
<inceptionYear>2008inceptionYear>
<properties>
<scala.version>2.11scala.version>
properties>
<repositories>
<repository>
<id>scala-tools.orgid>
<name>Scala-Tools Maven2 Repositoryname>
<url>http://scala-tools.org/repo-releasesurl>
repository>
repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.orgid>
<name>Scala-Tools Maven2 Repositoryname>
<url>http://scala-tools.org/repo-releasesurl>
pluginRepository>
pluginRepositories>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
<dependency>
<groupId>org.specsgroupId>
<artifactId>specsartifactId>
<version>3.0.0version>
<scope>testscope>
dependency>
<dependency>
<groupId>commons-logginggroupId>
<artifactId>commons-loggingartifactId>
<version>1.1.3version>
<type>jartype>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.1version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.9version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.10artifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.10artifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.6.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.10artifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.10artifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.10artifactId>
<version>1.5.2version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>2.10.6version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
<configuration>
<scalaVersion>${scala.version}scalaVersion>
<args>
<arg>-target:jvm-1.5arg>
args>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-eclipse-pluginartifactId>
<configuration>
<downloadSources>truedownloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilderbuildcommand>
buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanatureprojectnature>
additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINERclasspathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINERclasspathContainer>
classpathContainers>
configuration>
plugin>
plugins>
build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<configuration>
<scalaVersion>${scala.version}scalaVersion>
configuration>
plugin>
plugins>
reporting>
project>
自动打包提交集群代码
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi").set("spark.executor.memory", "512m")
.set("spark.driver.host","10.0.75.1")//这个ip很重要,我因为这个ip没有设置正确卡了好长时间,我使用的是docker,这个ip就要设置为本机在docker分配的虚拟网卡中的ip地址,如果设置成其他网卡的ip会被主机拒绝访问
.set("spark.driver.cores","1")
.setMaster("spark://192.168.43.50:7077") //这里应设为master的ip加上配置spark时设置的端口,一般都为7077,因为我使用的是docker所以将master的端口映射到本地了,所以直接用127.0.0.1来访问
.setJars(List("F:\\崔玉齐的资料\\大数据计算\\shiyan1\\out\\artifacts\\shiyan1_jar\\shiyan1.jar"))
开始运行
四、实验中遇到的问题及解决
1.环境配置时,我遇到了内存不够报错的情况,原来是在配置worker节点时没有配置足够内存。
2.在运行程序时,发现总是报错,原因是因为修改过代码后必须手动重新rebuild一下才能正常运行。
3.maven中的hadoop、spark依赖版本必须和自己的相适应。
五、实验心得
1.必须有耐心,必须有耐心,必须有耐心。有耐心才能在一次次的失败中找到成功的路。
2.搭环境时得细心,中英文符号得看请。
3.主机 ip 和 masterip 的映射关系要搞清楚。