在之前有篇文章中,和大家探讨了在MySOL数据库中,一个表的自增id用完,再插入数据有什么问题?评论处有大佬建议我另开一篇再说一下表的自增id在用完的情况下,用replace into、insert ignore以及insert... on duplicate会发生什么,当时不假思索就回复了安排,结果这一拖就快一个月了。
海岳尚可倾,吐诺终不移。今天想到这件事,就立马先把标题写出来了,这样就能督促自己把这篇文章完成,你以为我是不想失信于尤慕大佬吗?是的,我不想!但同时,我更不想失信于自己!
言归正传,开始我们今天的主题,当Mysql的一张表自增id用完了,此时再以各种姿势向表里插入数据会发生些什么呢?上一篇文章觉得说的不太好,有一些我想介绍的知识点没有讲到,所以通过这篇跟大家一起通过实践详细的探讨一番。
先创建一个简单的表,只包含一个自增字段id,像这样,勾选上自动递增和无符号
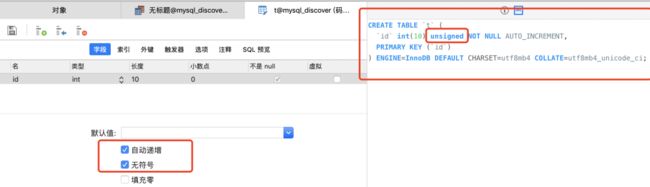
此时我们可以看到右边的建表语句,注意一点,类型int(10)后面多了一个unsigned关键字,不知道你们是否都知道unsigned是什么意思,又是怎么出来的,如果不知道,就要好好看下去了,这是一个很重要的知识点。
unsigned
首先,勾选上左侧的无符号才会出现unsigned类型。那unsigned是什么意思呢?整型的每一种都有无符号(unsigned)和有符号(signed)两种类型,在默认情况下声明的整型变量都是有符号的类型(char有点特别)。由于在计算机中,整数是以补码形式存放的。根据最高位的不同,如果是1,有符号数的话就是负数;如果是无符号数,则都解释为正数。同时在相同位数的情况下,所能表达的整数范围变大。另外,unsigned若省略后一个关键字,大多数编译器都会认为是unsigned int。有没有不知所云或者不明觉厉,简单点解释就是,在mysql中创建表时,如果整型使用了unsigned类型,那么该数据项就永远是正整数,每种数值类型的名称和取值范围如下表所示:

下面通过sql实例演示一下,我们先去掉勾选无符号,建表语句变成
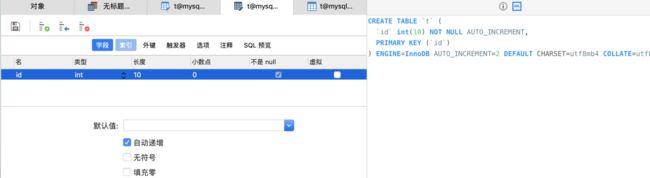
这时候已经没有unsigned了,我们向表里插入两条数据,一条正数一条负数:
INSERT INTO t VALUES (1);
结果显示插入成功

表里也有数据:

接下来我们修改表结构,勾选上无符号使用unsigned类型,像最初那样
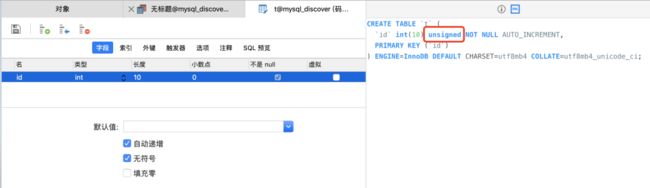
这时候我们再向表里插入两条数据,一条正数一条负数:
INSERT INTO t VALUES (1);
看看执行结果:

发现-1不能插入表中,报错超出了范围值,因为使用了unsigned之后,int类型的值范围变成了0到4294967295(0 到232 - 1)4个字节,参考上面的表格:

介绍了unsigned无符号类型之后,那大家应该都知道了使用了int unsigned类型字段数据理论上最大为4294967295,那么接下来我们就挑战极限,看看当一张表自增id用完了,此时再以各种姿势向表里插入数据会发生些什么?
姿势一:insert into
我们先直接暴力输出,在创建表的时候,直接将AUTO_INCREMENT的初始值声明为4294967295,sql如下:
CREATE TABLE `t` (
然后我们友好的向表中插一条数据:
INSERT INTO t VALUES (NULL);
你们猜一猜会发生什么,能插入成功吗?成功后表里长什么样子?先看一下执行结果:

咦,成功了,什么情况,我们打开表看看:

这是什么鬼?我不是插入的null吗?
先解释第一个疑问,废话,当然能插进去了,因为AUTO_INCREMENT=4294967295是从这个开始,当然还能插进去,为什么插入null变成了4294967295,因为只有一个字段,插入的null又不是id的值,id是自增主键啊,现在明白了吧,有可能有人觉得我这两个问题好无聊,但是我真的见过有不少人不知道,不信你以后面试时可以随机问问。
高潮来了,我们这时候再插入一条数据呢,还能插进去吗?走起:
INSERT INTO t VALUES (NULL);
看结果,oh no,报主键冲突了:

这是为什么呢?上面我故意只截图了一半,我们看看第一次插入null成功,我们打开表后看看表的DDL语句:

可以看到,当再次插入时,使用的自增ID还是 4294967295,这时候就会报主键冲突的错误。其实4294967295这个数字已经可以满足大部分的应用场景了,如果你的服务会经常性的插入和删除数据的话,还是存在用完的风险,建议采用bigint unsigned,这个数字就大了。
姿势二:replace insert
如果表的自增id用完时,我们使用replace into继续插数据时,会发生什么呢?我们先直接执行:
REPLACE INTO t VALUES (NULL);
可以发现和之前报一样的错,都是主键冲突。
那么,是不是insert into和replace into这两条sql在自增id用完这种情况下,继续插入数据时发生了一样的遭遇呢?
我们下来看一下自增id未满的情况下,这两条sql是怎样执行的。
1、新建一张表,自增id就从1开始(默认也是从1)
DROP TABLE IF EXISTS t1;
2、先使用insert into插入一条数据:
INSERT INTO t1 VALUES (1,1);
查看结果:
看一下表结果:
3、再使用replace into:
REPLACE INTO t1 VALUES (1,1);
查看结果:
看一下表结果:
4、再使用replace into:
REPLACE INTO t1 VALUES (1,2);
查看执行结果:
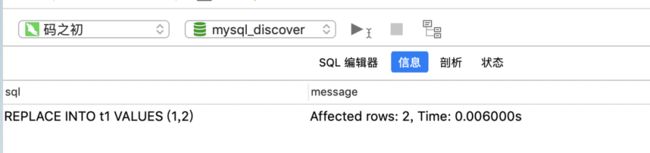
再看一下表结果:

看到这儿你有发现什么了吗?第一次insert into和replace into执行后受影响的行都是1行,第二次执行replace into后受影响的行变成了2行,为什么呢?这就是replace into和insert into的不同之处了。
划重点来了:
replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中,这时候:
如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。
否则,直接插入新数据。
所以,最后一次执行replace into时受影响的行变成了2行。知道了replace into的执行原理后,我们回到自增id最大时,replace into报错,发生了什么呢?如果发现表中已经有了最大的id,会先删除这条数据,然后重新插入,但是此时虽然删除了此条数据,自增id依然是最大值,为什么呢?这就是自增主键没有持久化的bug。究其原因,在于自增主键的分配,是由InnoDB数据字典内部一个计数器来决定的,而该计数器只在内存中维护,并不会持久化到磁盘中,所以还会报主键冲突的错误。
姿势三:insert ignore into
insert into ignore就比较简单了,我们直接运行sql看结果:
insert ignore into t VALUES (NULL);
结果显示:

可以看到受影响的行为0,这就是insert ignore 的作用:
如果发现表中已经有此行数据(根据主键或者唯一索引判断)则跳过此查询,不对数据库作任何操作;
否则没有此行数据的话,直接插入新数据。
姿势四:insert ...on duplicate
老样子,我们先通过sql实例看看自增id最大时,使用insert... on duplicate key会发生什么,sql运行起来:
INSERT INTO t VALUES (NULL) ON DUPLICATE KEY UPDATE id =id+1;
查看运行结果:

依旧是主键冲突错误。
下面我们来简单分析一下INSERT ON DUPLICATE KEY UPDATE这条sql做了什么事。我们在日常业务开发中经常有这样一个场景,首先创建一条记录,然后插入到数据库;如果数据库已经存在同一主键的记录,则执行update操作,如果不存在,则执行insert操作,这个时候INSERT ON DUPLICATE KEY UPDATE就派上用场了。在MySQL数据库中,如果在insert语句后面带上ON DUPLICATE KEY UPDATE 子句,而要插入的行与表中现有记录的惟一索引或主键中产生重复值,那么就会发生旧行的更新;如果插入的行数据与现有表中记录的唯一索引或者主键不重复,则执行新纪录插入操作。另外,ON DUPLICATE KEY UPDATE不能写where条件。
以上就是当Mysql的一张表自增id用完了,此时再以各种姿势向表里插入数据会发生什么的一些实践探讨,同时也加了其他一些知识点的讲解,希望能给看到的小伙伴有所帮助和启发。
知识拓展
如果在创建表时没有显示声明主键,会怎么办呢?如果是这种情况,InnoDB会自动帮你创建一个不可见的、长度为6字节的row_id,而且InnoDB 维护了一个全局的 dictsys.row_id,所以未定义主键的表都共享该row_id,每次插入一条数据,都把全局row_id当成主键id,然后全局row_id加1,该全局row_id在代码实现上使用的是bigint unsigned类型,但实际上只给row_id留了6字节,这种设计就会存在一个问题:如果全局row_id一直涨,一直涨,直到2的48幂次-1时,这个时候再+1,row_id的低48位都为0,结果在插入新一行数据时,拿到的row_id就为0,存在主键冲突的可能性。所以,为了避免这种隐患,每个表都需要定一个主键。
最后,留下一个问题,大家知道int(0)和int(10)有什么区别吗?