| 章节号 | 内容 |
|---|---|
| 1图片格式(png) | 宽度大于620px,保持高宽比减低为620px |
| 1-1 | 应用 |
| 1-1-1 | 方法 |
参考书目:
《Fonts & Encodings》
《The Unicode® Standard》
unicode-table
Lu = Letter, uppercase
Ll = Letter, lowercase
Lt = Letter, titlecase
Lm = Letter, modifier
Lo = Letter, other
Mn = Mark, nonspacing
Mc = Mark, spacing combining
Me = Mark, enclosing
Nd = Number, decimal digit
Nl = Number, letter
No = Number, other
Pc = Punctuation, connector
Pd = Punctuation, dash
Ps = Punctuation, open
Pe = Punctuation, close
Pi = Punctuation, initial quote (may behave like Ps or Pe depending on usage)
Pf = Punctuation, final quote (may behave like Ps or Pe depending on usage)
Po = Punctuation, other
Sm = Symbol, math
Sc = Symbol, currency
Sk = Symbol, modifier
So = Symbol, other
Zs = Separator, space
Zl = Separator, line
Zp = Separator, paragraph
Cc = Other, control
Cf = Other, format
Cs = Other, surrogate
Co = Other, private use
Cn = Other, not assigned (including noncharacters
第1章节 稍加粉饰类
-
➊ str.capitalize()
Return a copy of the string with its first character capitalized and the rest lowercased.
返回字符串的副本,其中第一个字符大写,其余字符小写
In [2]: a="a copy of the string with its first character"
In [4]: a.capitalize()
Out[4]: 'A copy of the string with its first character'
In [5]: a="a copy of the striNg with its First Character"
In [6]: a.capitalize()
Out[6]: 'A copy of the string with its first character'
In [7]: a="A COPY OF THE STRING WITH ITS FIRST CHARACTER"
In [8]: a.capitalize()
Out[8]: 'A copy of the string with its first character'
↑全小写的、全大写的、部分字母大写的字符串均可以正确转换。
-
➋ str.casefold()
使用在非英语字符语系中的不规律的大小写字符对应关系下。
www.unicode.org/Public/UCD/latest/ucd/CaseFolding.txt
uppercase:大写字母(的)
lowercase:小写字母(的)
Case_folding
One of the most common things that software developers do is "normalize" text for the purposes of comparison.
软件开发人员所做的最常见的事情之一是为了进行比较而“规范化”文本。
And one of the most basic ways that developers are taught to normalize text for comparison is to compare it in a "case insensitive" fashion. “不区分大小写”的方式进行比较。
In other cases, developers want to compare strings in a case sensitive manner. Unicode defines upper, lower, and title case properties for characters, plus special cases that impact specific language's use of text.
Many developers believe that that a case-insensitive comparison is achieved by mapping both strings being compared to either upper- or lowercase and then comparing the resulting bytes.
许多开发人员认为,不区分大小写的比较是通过将两个字符串映射为大写或小写,然后比较结果字节来实现的。
The existence of functions such as 'strcasecmp' in some C libraries, for example, or common examples in programming books reinforces this belief:
if (strcmp(toupper(foo),toupper(bar))==0)
{ // a typical caseless comparison
#toupper() C库函数
Alas, this model of case insensitive comparison breaks down with some languages. It also fails to consider other textual differences that can affect text. For example, [Unicode Normalization] could be needed to even out differences in e.g. non-Latin texts.
This document introduces case-folding and case insensitivity; provides some examples of how it is implemented in Unicode; and gives a few guidelines for spec writers and others who with to reference comparison using case folding.
Return a casefolded copy of the string. Casefolded strings may be used for caseless matching.
Casefolding is similar to lowercasing but more aggressive because it is intended to remove all case distinctions in a string. For example, the German lowercase letter 'ß' is equivalent to "ss". Since it is already lowercase, lower() would do nothing to 'ß'; casefold() converts it to "ss".
The casefolding algorithm is described in section 3.13 of the Unicode Standard.
In [3]: ?a.casefold
Docstring:
S.casefold() -> str
Return a version of S suitable for caseless comparisons.
#返回一个适用于
Type: builtin_function_or_method
In [8]: a="groß"
In [9]: a.casefold()
Out[9]: 'gross'
-
1- str.center(width [ , fillchar ] )
添加字符的顺序为:原字符为偶数:先左;原字符为奇数:先右。
Return centered in a string of length width. Padding is done using the specified fillchar (default is an ASCII space).
The original string is returned if width is less than or equal to len(s).
In [31]: ?a.center
Docstring:
S.center(width[, fillchar]) -> str
Return S centered in a string of length width. Padding is
done using the specified fill character (default is a space)
Type: builtin_function_or_method
In [13]: a="a"
In [14]: a.center(2,"-")
Out[14]: 'a-'
In [15]: a="ab"
In [16]: a.center(3,"-")
Out[16]: '-ab'
In [17]: a="abc"
In [18]: a.center(4,"-")
Out[18]: 'abc-'
In [19]: a="abcd"
In [20]: a.center(5,"-")
Out[20]: '-abcd'
-
1- str.ljust(width [ , fillchar ] )
Return the string left justified in a string of length width.
返回一个左对齐的字符串。右侧添加字符
Padding is done using the specified fillchar (default is an ASCII space)
使用fillchar来进行填充。
The original string is returned if width is less than or equal to len(s).
In [27]: a="abc"
In [30]: a.ljust(6,'-')
Out[30]: 'abc---'
-
1- str.rjust(width [ , fillchar ] )
返回一个右侧对齐的字符串。左侧添加字符
Return the string right justified in a string of length width. Padding is done using the specified fillchar (default is an ASCII space). The original string is returned if width is less than or equal to len(s).
In [48]: a="abc"
In [49]: a.rjust(6,'-')
Out[49]: '---abc'
-
1- str.count(sub [ , start [ , end ]] )
Return the number of non-overlapping occurrences of substring sub in the range [start, end]. Optional arguments start and end are interpreted as in slice notation.
关键词:non-overlapping occurrences
In [32]: ?a.count
Docstring:
S.count(sub[, start[, end]]) -> int
Return the number of non-overlapping occurrences of substring sub in
string S[start:end]. Optional arguments start and end are
interpreted as in slice notation.
Type: builtin_function_or_method
In [22]: a="aaabb"
In [23]: a.count("aa")
Out[23]: 1
In [24]: a="aaabbaa"
In [25]: a.count("aa")
Out[25]: 2
In [26]: a="aaabbaaa"
In [28]: a.count("aa")
Out[28]: 2
In [29]: a="aaabbaaaa"
In [30]: a.count("aa")
Out[30]: 3
个人理解:非重叠,意味着“aaa”只能被“aa”判定为出现一次。
-
1- str.encode(encoding=”utf-8”, errors=”strict”)
Return an encoded version of the string as a bytes object. Default encoding is 'utf-8'. errors may be given to set a different error handling scheme. The default for errors is 'strict', meaning that encoding errors raise a UnicodeError. Other possible values are 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' and any other name registered via codecs.register_error(), see section Er- ror Handlers. For a list of possible encodings, see section Standard Encodings.
In [48]: ?a.encode
Docstring:
S.encode(encoding='utf-8', errors='strict') -> bytes
Encode S using the codec registered for encoding. Default encoding
is 'utf-8'. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
'xmlcharrefreplace' as well as any other name registered with
codecs.register_error that can handle UnicodeEncodeErrors.
Type: builtin_function_or_method
-
1- str.endswith(suffix [ , start [ , end ]] )
Return True if the string ends with the specified suffix, otherwise return False. suffix can also be a tuple of suffixes to look for. With optional start, test beginning at that position. With optional end, stop comparing at that position.
In [52]: ?a.endswith
Docstring:
S.endswith(suffix[, start[, end]]) -> bool
Return True if S ends with the specified suffix, False otherwise.
With optional start, test S beginning at that position.
With optional end, stop comparing S at that position.
suffix can also be a tuple of strings to try.
Type: builtin_function_or_method
In [53]: a
Out[53]: 'aaabbaaaa'
In [54]: a.endswith("a")
Out[54]: True
In [55]: a.endswith("a",0,3)
Out[55]: True
#a[a:b],不含b
In [57]: a[0:3]
Out[57]: 'aaa'
In [53]: a
Out[53]: 'aaabbaaaa'
In [64]: a.endswith(('a','ba'))
Out[64]: True
In [65]: a.endswith(('a','ba','ab'))
Out[65]: True
↑可以传入一个元组形式的后缀合集,只要满足其中一个都返回True。
-
1- str.expandtabs(tabsize=8)
使用空格来扩展原字符串中的tab符。扩展比例由tabsize参数来控制。tabsize等于几,一个tab就会被扩展成为几个空格。
Return a copy of the string where all tab characters are replaced by one or more spaces, depending on the current column and the given tab size.
Tab positions occur every tabsize characters (default is 8, giving tab positions at columns 0, 8, 16 and so on). To expand the string, the current column is set to zero and the string is examined character by character. If the character is a tab (\t), one or more space characters are inserted in the result until the current column is equal to the next tab position. (The tab character itself is not copied.) If the character is a newline (\n) or return (\r), it is copied and the current column is reset to zero. Any other character is copied unchanged and the current column is incremented by one regardless of how the character is represented when printed.
In [66]: ?a.expandtabs
Docstring:
S.expandtabs(tabsize=8) -> str
#返回使用空格扩展所有制表符的s的副本。为什么不用?替换Replacement?这个词语?
Return a copy of S where all tab characters are expanded using spaces.
If tabsize is not given, a tab size of 8 characters is assumed.
Type: builtin_function_or_method
In [67]: a="1\t2\t3\t"
In [68]: a
Out[68]: '1\t2\t3\t'
In [69]: print(a)
1 2 3
In [70]: a.expandtabs(1)
Out[70]: '1 2 3 '
In [72]: print(a.expandtabs(1))
1 2 3
-
1- str.find(sub [ , start [ , end ]] )
如果找到,返回(从左侧起)第一个匹配到的字符串的下标 。
Return the lowest index in the string where substring sub is found within the slice s[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 if sub is not found.
The find() method should be used only if you need to know the position of sub. To check if sub is a substring or not, use the in operator:
In [74]: a
Out[74]: '1\t2\t3\t'
In [75]: '1' in a
Out[75]: True
In [73]: ?a.find
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: builtin_function_or_method
-
1- str.rfind(sub [ , start [ , end ]] )
如果找到,返回(从右侧起)第一个匹配到的字符串的下标 。
Return the highest index in the string where substring sub is found, such that sub is contained within s[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure.
In [45]: a.rfind('a')
Out[45]: 7
In [46]: a
Out[46]: 'i am a a worker'
-
1-2 str.format(*args, **kwargs)
Perform a string formatting operation.
The string on which this method is called can contain literal text or re-placement fields delimited by braces {}. Each replacement field contains either the numeric index of a positional argument, or the name of a keyword argument. Returns a copy of the string where each replacement field is replaced
with the string value of the corresponding argument.
In [2]: ?a.format
Docstring:
S.format(*args, **kwargs) -> str
Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}').
Type: builtin_function_or_method
-
1-2 str.format_map(mapping)
Similar to str.format(**mapping), except that mapping is used directly and not copied to a dict. This is useful if for example mapping is a dict subclass:
>>> class Default(dict):
...
def __missing__(self, key):
...
return key
...
>>> '{name} was born in {country}'.format_map(Default(name='Guido'))
'Guido was born in country'
In [76]: ?a.format_map
Docstring:
S.format_map(mapping) -> str
Return a formatted version of S, using substitutions from mapping.
The substitutions are identified by braces ('{' and '}').
Type: builtin_function_or_method
-
1- str.index(sub [ , start [ , end ]] )
Like find(), but raise ValueError when the substring is not found.
In [77]: ?a.index
Docstring:
S.index(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Raises ValueError when the substring is not found.
Type: builtin_function_or_method
In [78]: a
Out[78]: '1\t2\t3\t'
In [79]: a.index("a")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in ()
----> 1 a.index("a")
ValueError: substring not found
In [80]: a.find("a")
Out[80]: -1
-
1- str.rindex(sub [ , start [ , end ]] )
Like rfind() but raises ValueError when the substring sub is not found.
In [46]: a
Out[46]: 'i am a a worker'
In [47]: a.rindex('a')
Out[47]: 7
-
1- str.isalnum()
判断是否都是字母数字。
Return true if all characters in the string are alphanumeric and there is at least one character, false otherwise.A character c is alphanumeric if one of the following returns True: c.isalpha(), c.isdecimal(), c.isdigit(), or c.isnumeric().
In [81]: a
Out[81]: '1\t2\t3\t'
In [82]: a.isalnum()
Out[82]: False
In [83]: a='123'
In [84]: a.isalnum()
Out[84]: True
-
1- str.isalpha()
判断是否都是字母。
Return true if all characters in the string are alphabetic and there is at least one character, false otherwise. Alpha-betic characters are those characters defined in the Unicode character database as “Letter”, i.e., those with general category property being one of “Lm”, “Lt”, “Lu”, “Ll”, or “Lo”. Note that this is different from the “Alphabetic” property defined in the Unicode Standard.
⛊Lu(letter, uppercase). The name of the primary category of “letter” should be con-strued in a very broad sense, as it can apply equally to a letter of an alphabet, a signbelonging to a syllabary, or an ideograph.This particular subcategory refers to an “uppercase” letter; therefore, we can tell thatthe category applies to scripts that distinguish uppercase from lowercase letters. Veryfew scripts have this property: Latin, Greek, Coptic, Cyrillic, Armenian, liturgicalGeorgian, and Deseret.
⛊Ll(letter, lowercase). This category is the mirror image of the previous one. Here weare dealing with a letter from one of the multicameral alphabets (i.e., those that havemore than one case) listed above, and that letter will be lowercase.
⛊Lt(letter, titlecase). There are two very different types of characters that have beenclassifiedLt: the Croatian digraphs ‘Dž’, ‘Lj’, ‘Nj’ and the capital Greek vowels withiota adscript.In the first instance, we see a compromise that was made to facilitate transcriptionbetween the Cyrillic and Latin alphabets: it was necessary to transcribe the Cyrillicletters ‘r’, ‘y’, a n d ‘z’, and no better solution was found than the use of digraphs. Butunlike ligatures such as ‘œ’, ‘ij’, and ‘æ’, whose two elements both change case (‘Œ’,‘IJ’, ‘Æ’), here we may just as easily have ‘DŽ’ (in a word in which all the letters areuppercase) as ‘Dž’ (in a word in which only the first letter is supposed to be upper-case). This is so for all digraphs: the Spanish and German ‘ch’, the Breton ‘c’h’, etc.Unicode is not in the habit of encoding digraphs, but in this instance compatibilitywith old encodings forced Unicode to turn these digraphs into characters. Thus weconsider ‘dž’ to be the lowercase version, ‘DŽ’ the uppercase version, and ‘Dž’ the“titlecase” version of the character.The second instance is the result of a typographical misunderstanding. In Greekthere is a diacritical mark, “iotasubscript”, that is written beneath the vowelsalpha,eta,andomega:“?,@,A”. Typographers have found various ways to represent thesecharacters in uppercase. The most common practice, in Greece, is to place the samediacritical mark underneath the uppercase letter: “B,C,D”. In the English-speakingcountries another solution is used, which involves placing a capital or small-capitaliotaafter the letter. The latter is callediota adscript. Unicode incorrectly considersadscript the only possibly way to write this mark and thus has applied the categoryLtto uppercase letters with iota adscript.
⛊Lm(letter, modifier). This is a rather small category for letters that are never used aloneand that serve only to modify the sound of the letter that comes before them. Mostof these characters appear in the block of “modifier letters” (0x02B0-0x02FF). Thereare a few rare examples of characters in other blocks: theiota subscriptthat we justmentioned is one; the strokekashidathat joins Arabic letters is another. Intuitivelywe could say that a modifier letter is something that plays the same rôle as a diacriti-cal mark but that does not have the same graphical behavior, since its glyph will notcombine with the one of the previous character but will rather follow it
⛊Lo(letter, other). There is no denying it: Unicode is Eurocentric. Proof: Usually,when we create a classification, we begin with the most important cases and adda “catchall” case at the very end to cover any exceptions and omissions. Here thesubcategory namedletter, othercovers all the scripts in the world that have no notionof case, which is to say practically the entire world! The Semitic, Indian, SoutheastAsian, and ideographic scripts—all are lumped together indiscriminately asLo...
-
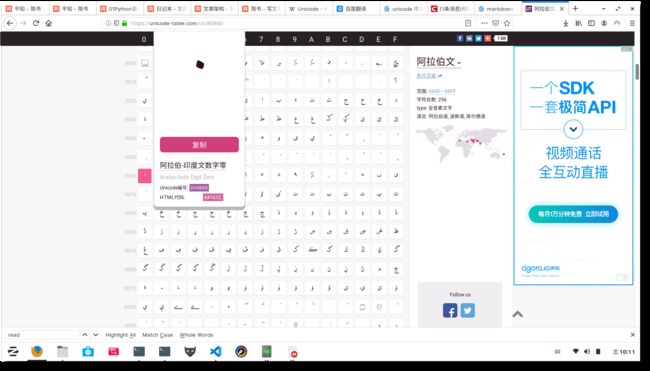
1- str.isdecimal()
unicode-table,点我
判断是否都是decimal characters。
Return true if all characters in the string are decimal characters and there is at least one character, false otherwise.Decimal characters are those that can be used to form numbers in base 10, e.g. U+0660, ARABIC-INDIC DIGITZERO. Formally a decimal character is a character in the Unicode General Category “Nd”.
⛊Nd(number, decimal digit). After the letters and the diacritical marks come the num-bers. Various writing systems have their own systems of decimal digits: we in the Westhave our “Arabic numberals”; the Arab countries of the Mashreq have their “Indiannumerals”; each of the languages of India and Southeast Asia has its own set of digitsbetween 0 and 9; etc. These are the digits that we find in categoryNd.Butbeware:ifone of these scripts should have the poor taste to continue the series of numeralsby introducing, for example, a symbol for the number 10 (as is the case in Tamiland Amharic) or a sign for one half (as in Tibetan), these new characters would notbe admissible to theNdcategory; they would be too far removed from our Westernpractices! They would instead go into the catchallNo, which we shall see in just amoment
⛊Nl(number, letter). An especially nasty problem: in many writing systems, letters areused to count (in which case we call them “numerals”). In Greek, for instance, 2006is written�κ��. But if the letters employed are also used in running text, they cannotbelong to two categories at the same time. And Unicode cannot double the size ofthe blocks for these scripts simply because someone might wish to use their letters asnumerals. What, then, is a “number-letter”, if not a letter that appears in text? Thereare very few such characters: the Roman numerals that were encoded separately inUnicode, the “Suzhou numerals” that are special characters used by Chinese mer-chants, a Gothic letter here, a runic letter there. Note that the Greek letterskoppa‘E’and ‘sampiF’, which represent the numbers 90 and 900, do not count as “number-letters” although they should, since their only use is to represent numbers.. .
⛊No(number, other). The catchall into which we place the various characters inher-ited from other encodings: superscript and subscript numerals, fractions, encirclednumbers. Also in this category are the numbers from various systems of numerationwhose numerical value is not an integer between 0 and 9: the 10, 100, and 1,000of Tamil; the numbers between 10 and 10,000 of Amharic; etc. Note: although wecannot classify the ideographs一‘one’,二‘two’,三‘three’,四‘four’, etc., as “letters”and “numbers” at the same time, we can so classify ideographs in parentheses:(一),(二),(三),(四), etc., are Unicode characters in their own right and are classified asNo.
In [85]: a="0b1010"
In [86]: a.isdecimal()
Out[86]: False
In [87]: a="123"
In [88]: a.isdecimal()
Out[88]: True
In [89]: a="123a"
In [90]: a.isdecimal()
Out[90]: False
-
1- str.isdigit()
判断是否都是digits。
Return true if all characters in the string are digits and there is at least one character, false otherwise. Digits include decimal characters and digits that need special handling, such as the compatibility superscript digits. This coversdigits which cannot be used to form numbers in base 10, like the Kharosthi numbers. Formally, a digit is a characterthat has the property value Numeric_Type=Digit or Numeric_Type=Decimal.
In [103]: ?a.isdigit
Docstring:
S.isdigit() -> bool
Return True if all characters in S are digits
and there is at least one character in S, False otherwise.
Type: builtin_function_or_method
-
1- str.isidentifier()
判断是不是一个合法的标识符(例如:不能有空格、不能以数字开头、等等。不判断是不是关键字)。
Return true if the string is a valid identifier according to the language definition, section identifiers. Use keyword.iskeyword() to test for reserved identifiers such as def and class.
In [129]: a.isidentifier()
Out[129]: False
In [130]: a='1b'
In [131]: a.isidentifier()
Out[131]: False
In [136]: a='class'
In [137]: a.isidentifier()
Out[137]: True
↓判断是否是关键字,做到了双重的验证。
In [138]: import keyword
In [139]: keyword.iskeyword(a)
Out[139]: True
In [140]: a='cla'
In [141]: keyword.iskeyword(a)
Out[141]: False
-
1- str.islower()
判断字符串是不是全小写。
Return true if all cased characters 4 in the string are lowercase and there is at least one cased character, false otherwise.
In [140]: a='cla'
In [142]: a.islower()
Out[142]: True
In [143]: a='cla9'
In [144]: a.islower()
Out[144]: True
In [145]: a='cla*'
In [146]: a.islower()
Out[146]: True
In [147]: a='clA*'
In [148]: a.islower()
Out[148]: False
-
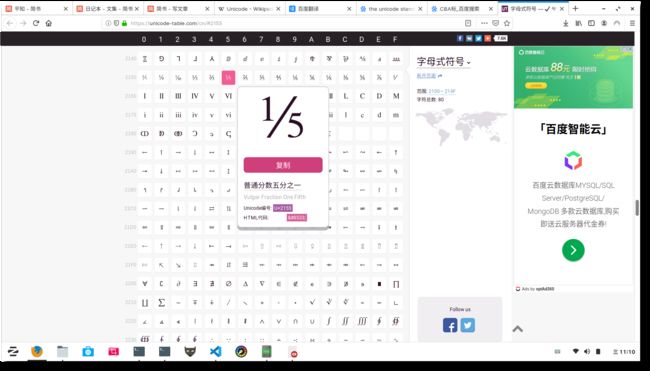
1- str.isnumeric()
判断字符串是不是全numeric characters。
Return true if all characters in the string are numeric characters, and there is at least one character, false otherwise. Numeric characters include digit characters, and all characters that have the Unicode numeric value property, e.g. U+2155, VULGAR FRACTION ONE FIFTH. Formally, numeric characters are those with the property value Numeric_Type=Digit, Numeric_Type=Decimal or Numeric_Type=Numeric.
-
1- str.isprintable()
判断字符串是不是打印字符。
Return true if all characters in the string are printable or the string is empty, false otherwise. Nonprintable characters are those characters defined in the Unicode character database as “Other” or “Separator”, excepting the ASCIIspace (0x20) which is considered printable. (Note that printable characters in this context are those which should not be escaped when repr() is invoked on a string. It has no bearing on the handling of strings written to sys.stdout or sys.stderr.)
-
1- str.isspace()
判断字符串是不是whitespace characters。
Return true if there are only whitespace characters in the string and there is at least one character, false otherwise.
Whitespace characters are those characters defined in the Unicode character database as “Other” or “Separator” and those with bidirectional property being one of “WS”, “B”, or “S”.
In [149]: a=" "
In [150]: a.isspace()
Out[150]: True
In [151]: a=" \t\n"
In [152]: a.isspace()
Out[152]: True
In [153]: a=" \t\n\r"
In [154]: a.isspace()
Out[154]: True
-
1- str.istitle()
判断字符串是不是titlecased 。
Return true if the string is a titlecased string and there is at least one character, for example uppercase characters may only follow uncased characters and lowercase characters only cased ones. Return false otherwise.
In [5]: a="AaaaaaA Aa A"
In [6]: a.istitle()
Out[6]: False
In [7]: a="123456A Aa A"
In [8]: a.istitle()
Out[8]: True
In [9]: a="1 \t\nA Aa A"
In [10]: a
Out[10]: '1 \t\nA Aa A'
In [11]: a.istitle()
Out[11]: True
-
1- str.isupper()
判断字符串是否都是大写all cased characters are uppercase 。
Return true if all cased characters in the string are uppercase and there is at least one cased character, false otherwise.
Cased characters are those with general category property being one of “Lu” (Letter, uppercase), “Ll” (Letter, lowercase), or “Lt” (Letter, titlecase).
In [13]: a="ADCS"
In [14]: a.isupper()
Out[14]: True
In [15]: a="ADCSc"
In [16]: a.isupper()
Out[16]: False
In [17]: a="AD CS \t 7987897$"
In [18]: a.isupper()
Out[18]: True
-
1- str.join(iterable)
Return a string which is the concatenation of the strings in iterable.
返回一个字符串,它是iterable中字符串与str的串联。
A TypeError will be raised if there are any non-string values in iterable, including bytes objects.
The separator between elements is the string providing this method.
分隔符位置就是str插入(用str来替换掉可迭代对象的分隔符)的位置。
In [20]: a=["123123","13123123","gasgasdfasd"]
In [21]: a
Out[21]: ['123123', '13123123', 'gasgasdfasd']
In [25]: b="---"
In [26]: b.join(a)
Out[26]: '123123---13123123---gasgasdfasd'
-
1- str.lower()
返回一个全小写的字符串。
Return a copy of the string with all the cased characters converted to lowercase.
The lowercasing algorithm used is described in section 3.13 of the Unicode Standard.
Cased characters are those with general category property being one of “Lu” (Letter, uppercase), “Ll” (Letter, lowercase), or “Lt” (Letter, titlecase).
In [31]: a='ABCdE'
In [32]: a.lower()
Out[32]: 'abcde'
-
1- str.partition(sep)
从左侧开始查找。从sep处斩断str,分为三部分:sep前一部分,sep为一部分,sep后为一部分。返回一个包含这三部分的元组。
Split the string at the first occurrence of sep, and return a 3-tuple containing the part before the separator, the separator itself, and the part after the separator. If the separator is not found, return a 3-tuple containing the string itself, followed by two empty strings.
In [33]: a="www.img"
In [34]: a.partition(".")
Out[34]: ('www', '.', 'img')
-
1- str.rpartition(sep)
从右侧开始查找。从sep处斩断str,分为三部分:sep前一部分,sep为一部分,sep后为一部分。返回一个包含这三部分的元组。
Split the string at the last occurrence of sep, and return a 3-tuple containing the part before the separator, the separator itself, and the part after the separator. If the separator is not found, return a 3-tuple containing two empty strings, followed by the string itself.
In [50]: a='www.img.com'
In [51]: a.rpartition('.')
Out[51]: ('www.img', '.', 'com')
-
1- str.replace(old, new [ , count ] )
count为替换几个,count为1则替换首个出现的old,以此类推。
Return a copy of the string with all occurrences of substring old replaced by new. If the optional argument count is given, only the first count occurrences are replaced.
In [36]: ?a.replace
Docstring:
S.replace(old, new[, count]) -> str
Return a copy of S with all occurrences of substring
old replaced by new. If the optional argument count is
given, only the first count occurrences are replaced.
Type: builtin_function_or_method
In [37]: a="i am a a worker"
In [38]: a.replace('a','b')
Out[38]: 'i bm b b worker'
In [39]: a.replace('a','b',0)
Out[39]: 'i am a a worker'
In [40]: a.replace('a','b',1)
Out[40]: 'i bm a a worker'
In [41]: a.replace('a','b',2)
Out[41]: 'i bm b a worker'
In [42]: a.replace('a','b',3)
Out[42]: 'i bm b b worker'
In [43]: a.count('a')
Out[43]: 3
-
1- str.split(sep=None, maxsplit=-1)
使用sep来分割一个字符串,并返回一个包含分割后的words的列表。默认的sep为空格。
Return a list of the words in the string, using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done (thus, the list will have at most maxsplit+1 elements). If maxsplit is not specified or -1, then there is no limit on the number of splits (all possible splits are made).
If sep is given, consecutive delimiters are not grouped together and are deemed to delimit empty strings (for example, '1,,2'.split(',') returns ['1', '', '2']). The sep argument may consist of multiple characters (for example, '1<>2<>3'.split('<>') returns ['1', '2', '3']). Splitting an empty string with a specified separator returns [''].
In [52]: a="abcdef"
In [53]: a.split()
Out[53]: ['abcdef']
In [54]: a="a,b,c,d,e,f"
In [55]: a.split()
Out[55]: ['a,b,c,d,e,f']
In [56]: a.split(",")
Out[56]: ['a', 'b', 'c', 'd', 'e', 'f']
#maxsplit是n,则整个字符串就分割为n+1份
In [57]: a.split(",",3)
Out[57]: ['a', 'b', 'c', 'd,e,f']
#默认以空格为sep
In [58]: a='a b c d e'
In [59]: a.split()
Out[59]: ['a', 'b', 'c', 'd', 'e']
#多个空格视为一个sep
In [60]: a='a b c d e'
In [61]: a.split()
Out[61]: ['a', 'b', 'c', 'd', 'e']
#前后有空格都直接删掉
In [62]: a=' a b c d e '
In [63]: a.split()
Out[63]: ['a', 'b', 'c', 'd', 'e']
-
1- str.splitlines( [ keepends ] )
Return a list of the lines in the string, breaking at line boundaries. Line breaks are not included in the resulting list unless keepends is given and true.
This method splits on the following line boundaries. In particular, the boundaries are a superset of universal new-lines.

-
1- str.rsplit(sep=None, maxsplit=-1)
Return a list of the words in the string, using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done, the rightmost ones. If sep is not specified or None, any whitespace string is a separator. Except for splitting from the right, rsplit() behaves like split() which is described in detail below.
import unicodedata
count=1
digitcount=0
decimalcount=0
print("#","Integer","Unicode Name".center(40),"Character","HTML",sep="\t")
for i in range(1,1114111):
if chr(i).isdigit() and not chr(i).isdecimal():
try:
print(count,i,unicodedata.name(chr(i)).center(40),chr(i).center(10), "&#" + str(i) + ";",sep="\t")
except:
print("??", "&#" + str(i) + ";",sep="\t")
count=count+1
if chr(i).isdigit():
digitcount=digitcount+1
if chr(i).isdecimal():
decimalcount=decimalcount+1
print("digit count:",digitcount)
print("decimal count:",decimalcount)
# Integer Unicode Name Character HTML
1 178 SUPERSCRIPT TWO ² ²
2 179 SUPERSCRIPT THREE ³ ³
3 185 SUPERSCRIPT ONE ¹ ¹
4 4969 ETHIOPIC DIGIT ONE ፩ ፩
5 4970 ETHIOPIC DIGIT TWO ፪ ፪
6 4971 ETHIOPIC DIGIT THREE ፫ ፫
7 4972 ETHIOPIC DIGIT FOUR ፬ ፬
8 4973 ETHIOPIC DIGIT FIVE ፭ ፭
9 4974 ETHIOPIC DIGIT SIX ፮ ፮
10 4975 ETHIOPIC DIGIT SEVEN ፯ ፯
11 4976 ETHIOPIC DIGIT EIGHT ፰ ፰
12 4977 ETHIOPIC DIGIT NINE ፱ ፱
13 6618 NEW TAI LUE THAM DIGIT ONE ᧚ ᧚
14 8304 SUPERSCRIPT ZERO ⁰ ⁰
15 8308 SUPERSCRIPT FOUR ⁴ ⁴
16 8309 SUPERSCRIPT FIVE ⁵ ⁵
17 8310 SUPERSCRIPT SIX ⁶ ⁶
18 8311 SUPERSCRIPT SEVEN ⁷ ⁷
19 8312 SUPERSCRIPT EIGHT ⁸ ⁸
20 8313 SUPERSCRIPT NINE ⁹ ⁹
21 8320 SUBSCRIPT ZERO ₀ ₀
22 8321 SUBSCRIPT ONE ₁ ₁
23 8322 SUBSCRIPT TWO ₂ ₂
24 8323 SUBSCRIPT THREE ₃ ₃
25 8324 SUBSCRIPT FOUR ₄ ₄
26 8325 SUBSCRIPT FIVE ₅ ₅
27 8326 SUBSCRIPT SIX ₆ ₆
28 8327 SUBSCRIPT SEVEN ₇ ₇
29 8328 SUBSCRIPT EIGHT ₈ ₈
30 8329 SUBSCRIPT NINE ₉ ₉
31 9312 CIRCLED DIGIT ONE ① ①
32 9313 CIRCLED DIGIT TWO ② ②
33 9314 CIRCLED DIGIT THREE ③ ③
34 9315 CIRCLED DIGIT FOUR ④ ④
35 9316 CIRCLED DIGIT FIVE ⑤ ⑤
36 9317 CIRCLED DIGIT SIX ⑥ ⑥
37 9318 CIRCLED DIGIT SEVEN ⑦ ⑦
38 9319 CIRCLED DIGIT EIGHT ⑧ ⑧
39 9320 CIRCLED DIGIT NINE ⑨ ⑨
40 9332 PARENTHESIZED DIGIT ONE ⑴ ⑴
41 9333 PARENTHESIZED DIGIT TWO ⑵ ⑵
42 9334 PARENTHESIZED DIGIT THREE ⑶ ⑶
43 9335 PARENTHESIZED DIGIT FOUR ⑷ ⑷
44 9336 PARENTHESIZED DIGIT FIVE ⑸ ⑸
45 9337 PARENTHESIZED DIGIT SIX ⑹ ⑹
46 9338 PARENTHESIZED DIGIT SEVEN ⑺ ⑺
47 9339 PARENTHESIZED DIGIT EIGHT ⑻ ⑻
48 9340 PARENTHESIZED DIGIT NINE ⑼ ⑼
49 9352 DIGIT ONE FULL STOP ⒈ ⒈
50 9353 DIGIT TWO FULL STOP ⒉ ⒉
51 9354 DIGIT THREE FULL STOP ⒊ ⒊
52 9355 DIGIT FOUR FULL STOP ⒋ ⒋
53 9356 DIGIT FIVE FULL STOP ⒌ ⒌
54 9357 DIGIT SIX FULL STOP ⒍ ⒍
55 9358 DIGIT SEVEN FULL STOP ⒎ ⒎
56 9359 DIGIT EIGHT FULL STOP ⒏ ⒏
57 9360 DIGIT NINE FULL STOP ⒐ ⒐
58 9450 CIRCLED DIGIT ZERO ⓪ ⓪
59 9461 DOUBLE CIRCLED DIGIT ONE ⓵ ⓵
60 9462 DOUBLE CIRCLED DIGIT TWO ⓶ ⓶
61 9463 DOUBLE CIRCLED DIGIT THREE ⓷ ⓷
62 9464 DOUBLE CIRCLED DIGIT FOUR ⓸ ⓸
63 9465 DOUBLE CIRCLED DIGIT FIVE ⓹ ⓹
64 9466 DOUBLE CIRCLED DIGIT SIX ⓺ ⓺
65 9467 DOUBLE CIRCLED DIGIT SEVEN ⓻ ⓻
66 9468 DOUBLE CIRCLED DIGIT EIGHT ⓼ ⓼
67 9469 DOUBLE CIRCLED DIGIT NINE ⓽ ⓽
68 9471 NEGATIVE CIRCLED DIGIT ZERO ⓿ ⓿
69 10102 DINGBAT NEGATIVE CIRCLED DIGIT ONE ❶ ❶
70 10103 DINGBAT NEGATIVE CIRCLED DIGIT TWO ❷ ❷
71 10104 DINGBAT NEGATIVE CIRCLED DIGIT THREE ❸ ❸
72 10105 DINGBAT NEGATIVE CIRCLED DIGIT FOUR ❹ ❹
73 10106 DINGBAT NEGATIVE CIRCLED DIGIT FIVE ❺ ❺
74 10107 DINGBAT NEGATIVE CIRCLED DIGIT SIX ❻ ❻
75 10108 DINGBAT NEGATIVE CIRCLED DIGIT SEVEN ❼ ❼
76 10109 DINGBAT NEGATIVE CIRCLED DIGIT EIGHT ❽ ❽
77 10110 DINGBAT NEGATIVE CIRCLED DIGIT NINE ❾ ❾
78 10112 DINGBAT CIRCLED SANS-SERIF DIGIT ONE ➀ ➀
79 10113 DINGBAT CIRCLED SANS-SERIF DIGIT TWO ➁ ➁
80 10114 DINGBAT CIRCLED SANS-SERIF DIGIT THREE ➂ ➂
81 10115 DINGBAT CIRCLED SANS-SERIF DIGIT FOUR ➃ ➃
82 10116 DINGBAT CIRCLED SANS-SERIF DIGIT FIVE ➄ ➄
83 10117 DINGBAT CIRCLED SANS-SERIF DIGIT SIX ➅ ➅
84 10118 DINGBAT CIRCLED SANS-SERIF DIGIT SEVEN ➆ ➆
85 10119 DINGBAT CIRCLED SANS-SERIF DIGIT EIGHT ➇ ➇
86 10120 DINGBAT CIRCLED SANS-SERIF DIGIT NINE ➈ ➈
87 10122 DINGBAT NEGATIVE CIRCLED SANS-SERIF DIGIT ONE ➊ ➊
88 10123 DINGBAT NEGATIVE CIRCLED SANS-SERIF DIGIT TWO ➋ ➋
89 10124 DINGBAT NEGATIVE CIRCLED SANS-SERIF DIGIT THREE ➌ ➌
90 10125 DINGBAT NEGATIVE CIRCLED SANS-SERIF DIGIT FOUR ➍ ➍
91 10126 DINGBAT NEGATIVE CIRCLED SANS-SERIF DIGIT FIVE ➎ ➎
92 10127 DINGBAT NEGATIVE CIRCLED SANS-SERIF DIGIT SIX ➏ ➏
93 10128 DINGBAT NEGATIVE CIRCLED SANS-SERIF DIGIT SEVEN ➐ ➐
94 10129 DINGBAT NEGATIVE CIRCLED SANS-SERIF DIGIT EIGHT ➑ ➑
95 10130 DINGBAT NEGATIVE CIRCLED SANS-SERIF DIGIT NINE ➒ ➒
96 68160 KHAROSHTHI DIGIT ONE 𐩀
97 68161 KHAROSHTHI DIGIT TWO 𐩁
98 68162 KHAROSHTHI DIGIT THREE 𐩂
99 68163 KHAROSHTHI DIGIT FOUR 𐩃
100 69216 RUMI DIGIT ONE 𐹠
101 69217 RUMI DIGIT TWO 𐹡
102 69218 RUMI DIGIT THREE 𐹢
103 69219 RUMI DIGIT FOUR 𐹣
104 69220 RUMI DIGIT FIVE 𐹤
105 69221 RUMI DIGIT SIX 𐹥
106 69222 RUMI DIGIT SEVEN 𐹦
107 69223 RUMI DIGIT EIGHT 𐹧
108 69224 RUMI DIGIT NINE 𐹨
109 69714 BRAHMI NUMBER ONE 𑁒
110 69715 BRAHMI NUMBER TWO 𑁓
111 69716 BRAHMI NUMBER THREE 𑁔
112 69717 BRAHMI NUMBER FOUR 𑁕
113 69718 BRAHMI NUMBER FIVE 𑁖
114 69719 BRAHMI NUMBER SIX 𑁗
115 69720 BRAHMI NUMBER SEVEN 𑁘
116 69721 BRAHMI NUMBER EIGHT 𑁙
117 69722 BRAHMI NUMBER NINE 𑁚
118 127232 DIGIT ZERO FULL STOP 🄀
119 127233 DIGIT ZERO COMMA 🄁
120 127234 DIGIT ONE COMMA 🄂
121 127235 DIGIT TWO COMMA 🄃
122 127236 DIGIT THREE COMMA 🄄
123 127237 DIGIT FOUR COMMA 🄅
124 127238 DIGIT FIVE COMMA 🄆
125 127239 DIGIT SIX COMMA 🄇
126 127240 DIGIT SEVEN COMMA 🄈
127 127241 DIGIT EIGHT COMMA 🄉
128 127242 DIGIT NINE COMMA 🄊
digit count: 708
decimal count: 580
↑↓类的基本结构:
-
1-1 类的初步—定义一个类并创建对象实例
1-1-1. 导言—用户管理—用户的分类及介绍
-
1-2 类的初步—定义一个类并创建对象实例
1-2-1. 导言—用户管理—用户的分类及介绍
第2章节 判断类
-
2-1 类的初步—定义一个类并创建对象实例
2-1-1. 导言—用户管理—用户的分类及介绍
-
2-2 类的初步—定义一个类并创建对象实例
2-2-1. 导言—用户管理—用户的分类及介绍
第3章节
-
3-1 类的初步—定义一个类并创建对象实例
3-1-1. 导言—用户管理—用户的分类及介绍
-
3-2 类的初步—定义一个类并创建对象实例