本文以天天基金网为例,爬取网站上的基金排行并存储在本地记事本中和MongoDB数据库中。
网址:http://fund.eastmoney.com/data/fundranking.html#tall;c0;r;szzf;pn50
1.网址分析
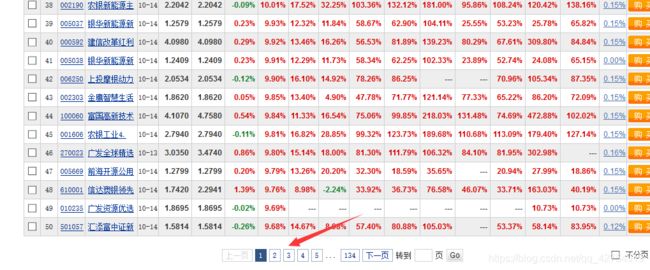
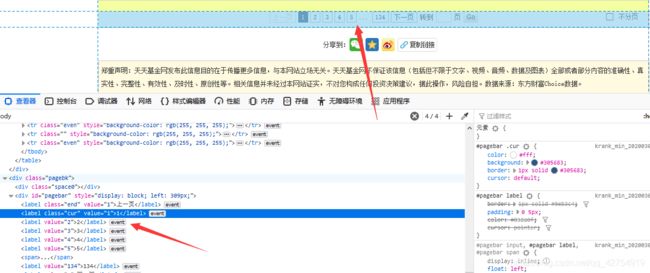
打开网页我们看到每页最多显示50个基金信息,在源代码中,我们发现其他页码没有跳转链接。但是我们选择右下角不分页,网站的URL发生变化:
从:
http://fund.eastmoney.com/data/fundranking.html#tall;c0;r;szzf;pn50
变化为:
http://fund.eastmoney.com/data/fundranking.html#tall;c0;r;szzf;pn10000
因此我们得知pn后面的参数控制每页显示数量,我们将网址改为pn100发现网站显示100条信息。
2.网页信息分析
分析完网址信息,我们对网站内容进行分析
一开始我使用如下代码获取页面信息,但是并不能提取任何信息。
defgethtml(url):headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0'}response=requests.get(url,headers=headers)ifresponse.status_code==200:# response.encoding = 'gb2312' # 转码print('**')returnresponse.textelse:returnNonedefgetinformation(html):'''doc = pq(html)
items = doc('#dbtable tbody tr ')'''html=etree.HTML(html)result=html.xpath('//body//div[7]//div[3]//table[2]//tbody//tr[1]//td[2]/text()')print(result)# dbtable tbody tr
分析网页源代码,发现每条数据后面都有事件监听器,js加载。因此我思考是不是网页的内容是js加载出来的,使用response.text无法加载网页数据。此外,网页也没有ajax加载格式。
因此尝试使用selenium加载网页,获取页面信息,事实证明,这是对的。

3.代码
我们将获取的网页信息利用pyquery提取需要的信息
我们将数据存储在MongoDB和txt记事本中
fromseleniumimportwebdriverfromselenium.webdriver.support.waitimportWebDriverWaitfrompyqueryimportPyQueryaspqimportcsvimportjsonfromlxmlimportetreeimportpymongoclient=pymongo.MongoClient(host='localhost',port=27017)db=client.天天基金# 指定数据库,若不存在,则直接创建一个test数据库collection=db.基金排行defgethtml(url):brower=webdriver.Firefox()brower.get(url)html=brower.page_sourcereturnhtmldefgetinformation(html):doc=pq(html)items=doc('html body div.mainFrame div.dbtable table#dbtable tbody tr ').items()foriteminitems:list=[]print(item.find('td').text().strip())write(item.find('td').text().strip())infors=item.find('td').items()fori,inforinenumerate(infors):list.append(str(infor.text().strip()))ifi==2:href=infor.find('a').attr('href')write(href)list.append(href)information={'index':list[1],'代码':list[2],'网址':list[3],'简称':list[4],'日期':list[5],'单位净值':list[6],'累计净值':list[7],'日增长绿':list[8],'近一周':list[9],'近一月':list[10],'近三月':list[11],'近六月':list[12],'近一年':list[13],'近两年':list[14],'近三年':list[15],'今年来':list[16],'成立来':list[17],'自定义':list[18],'手续费':list[19],}collection.insert_one(information)defwrite(information):withopen('基金.txt','a',encoding='UTF-8')asf:f.write(information+'\n')f.close()url='http://fund.eastmoney.com/data/fundranking.html#tall;c0;r;szzf;pn100'if__name__=='__main__':html=gethtml(url)getinformation(html)
4.结果展示
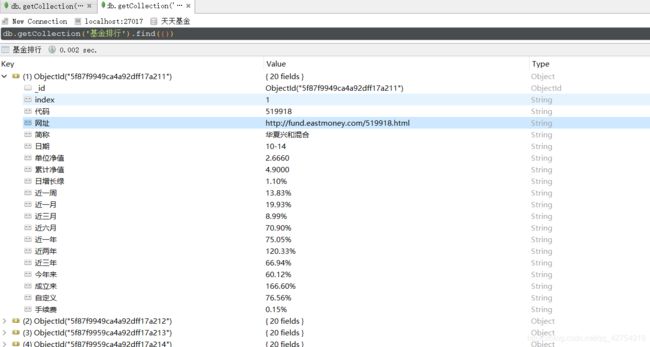

将字典information传入write函数中,可以得到另一种方式存储在记事本中。
write(str(information))
1
