前面的章节已经介绍了如何使用TensorFlow实现常用的神经网络结构。在将这些神经网络用于实际问题之前,需要先优化网络中的参数。这就是训练神经网络的过程。训练神经网络十分复杂,有时需要几天甚至几周的时间。为了更好地管理、调试和优化神经网络的训练过程,TensorFlow提供了一个可视化工具TensorBoard。TensorBoard可以有效地展示TensorFlow在运行过程中的计算图、各种指标随着时间的变化趋势以及训练中使用到的图像等信息。
本章将详细介绍TensorBoard的使用方法。
1.将介绍TensorBoard的基础知识,并通过TensorBoard来可视化一个简单的TensorFlow样例程序。在这一节中将介绍如何启动TensorBoard,并大致讲解TensorBoard提供的几类可视化信息。
2.介绍通过TensorBoard得到的TensorFlow计算图的可视化结果。TensorFlow计算图保存了TensorFlow程序计算过程的所有信息。因为TensorFlow计算图中的信息含量较多,所以TensorBoard设计了一套交互过程来更加清晰地呈现这些信息。
3.最后将详细讲解如何使用在这一节中将详细讲解如何使用TensorBoard对训练过程进行监控,以及如何通过TensorFlow指定对训练过程进行监控,以及如何通过TensorFlow指定需要可视化的指标。并给出完整的样例程序介绍如何得到可视化结果。
1.TensorBoard简介
TensorBoard是TensorFlow的可视化工具,它可以通过TensorFlow程序运行过程中输出的日志文件可视化TensorFlow程序的运行状态。TensorBoard和TensorFlow程序跑在不同的进程中,TensorBoard会自动读取最新的TensorFlow日志文件,并呈现当前TensorFlow程序运行的最新状态。以下代码展示了一个简单的TensorFlow程序,这个程序中完成了TensorBoard日志输出的功能:
import tensorflow as tf
input1 = tf.constant([1.0, 2.0, 3.0], name="input1")
input2 = tf.Variable(tf.random_uniform([3]), name="input2")
output = tf.add_n([input1, input2], name="add")
writer = tf.summary.FileWriter("C:\\log", tf.get_default_graph())
writer.close()
以上程序输出了TensorFlow计算图的信息,所以运行Tensorboard时,可以看到这个向量相加程序计算图可视化之后的结果。TensorBoard不需要额外的安装过程,在TensorFlow安装完成时,TensorBoard会被自动安装。运行下面的命令可以启动TensorBoard:
运行TensorBoard,并将日志的地址指向上面程序日志输出的地址
tensorboard --logdir=C:\\log
运行上面的命令会启动一个服务,这个服务的端口默认为6006.通过浏览器打开localhost:6006,可以看到下图所示的界面:

如上图,可以看到上面程序TensorFlow计算图的可视化结果。
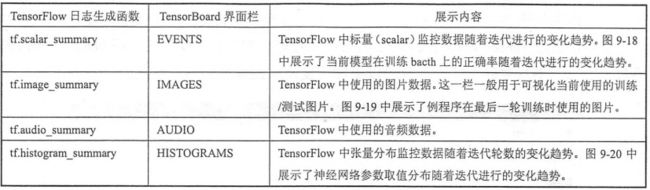
在界面右上方,点击下拉菜单可以看到有12栏,每一栏都对应了一类信息的可视化结果,在下面的章节中将具体介绍每一栏的功能。如图,打开tensorboard界面会默认进入SCALARS栏。因为上面的程序没有输出任何由EVENTS栏可视化的信息,所以这个界面显示的是“NO scalar data was found”(没有发现标量数据)。
2.TensorFlow计算图可视化
在上图中给出了一个TensorFlow计算图的可视化效果图。然而,从TensorBoard可视化结果中可以获取的信息远不止上图所示的这些。这一节将详细介绍如何更好地利用TensorFlow计算图的可视化结果。
1.首先将介绍通过TensorFlow节点的命名空间整理Tensorboard可视化得到的TensorFlow计算图。在前面介绍过,TensorFlow会将所有的计算以图的形式组织起来。TensorBoard可视化得到的图并不仅是将TensorFlow计算图中的节点和边直接可视化,它会根据每个TensorFlow计算节点的命名空间来整理可视化得到的效果,使得神经网络的整体结构不会被过多的细节所淹没。除了显示TensorFlow计算图的结构,TensorBoard还可以展示TensorFlow计算节点上的其他信息。
2.第二小节将介绍如何从可视化结果中获取TensorFlow计算图中的这些信息。
2.1命名空间与TensorBoard图上节点
在上一节给出的样例程序中只定义了一个加法操作,然而从图中可以看到,将这个TensorFlow计算图可视化得到的效果图上却有
多个节点,可以想象,一个复杂的神经网络模型所对应的TensorFlow计算图会比上图中简单的向量加法样例程序的计算图复杂很多,那么没有经过整理得到的可视化效果图并不能帮助很好地理解神经网络模型的结构。
为了更好地组织可视化效果图中的计算节点,TensorBoard支持通过TensorFlow命名空间来整理可视化效果图上的节点。在TensorBoard的默认视图中,TensorFlow计算图中同一个命名空间下的所有节点会被缩略成一个节点,只有顶层命名空间中的节点才会被显示在TensorBoard可视化效果图上。在前面介绍过变量的命名空间,以及如何通过tf.variable_scope函数管理变量的命名空间。除了tf.variable_scope函数,tf.name_scope函数也提供了命名空间管理的功能。这两个函数在大部分情况下是等价的,唯一的区别是在使用tf.get_variable函数时,以下代码简单地说明了这两个函数的区别:
1.不同的命名空间
import tensorflow as tf
with tf.variable_scope("foo"):
a = tf.get_variable("bar", [1])
print a.name
with tf.variable_scope("bar"):
b = tf.get_variable("bar", [1])
print b.name
输出:
- tf.Variable和tf.get_variable的区别。
with tf.name_scope("a"):
a = tf.Variable([1])
print a.name
a = tf.get_variable("b", [1])
print a.name
输出:
结果分析:
使用tf.Variable函数生成变量会受到tf.name_scope影响,于是这个变量的名称为“a/Variable”
而使用tf.get_variable函数不受tf.name_scope函数的影响,于是变量并不在b这个命名空间中。所以这个变量名称为b
通过对命名空间管理,可以改进上一节中向量加法的样例代码,使得可视化得到的效果图更加清晰。以下代码展示了改进的方法:
with tf.name_scope("input1"):
input1 = tf.constant([1.0, 2.0, 3.0], name="input1")
with tf.name_scope("input2"):
input2 = tf.Variable(tf.random_uniform([3]), name="input2")
output = tf.add_n([input1, input2], name="add")
writer = tf.summary.FileWriter("C:\\log", tf.get_default_graph())
writer.close()
下图显示了改进后的可视化效果图:

从图中可以看到,上图中很多的节点都被缩略到了图中input2节点。这样TensorFlow程序中定义的加法运算被清晰地展示了出来。需要查看input2节点中具体包含了哪些运算时,可以将鼠标移动到input2节点,并点开右上角加好“+”。下图展示了input2节点之后的视图:

在input2的展开图中可以看到数据初始化相关的操作都被整理到了一起。下面将给出一个样例程序来展示如何很好地可视化一个真实的神经网络结构图。本节将继续采用之前的MNIST数字识别问题哪一章的架构,以下代码给出了改造后的mnist_train.py程序:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
- 定义神经网络的参数。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 3000
MOVING_AVERAGE_DECAY = 0.99
- 定义训练的过程并保存TensorBoard的log文件。
def train(mnist):
# 输入数据的命名空间。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 处理滑动平均的命名空间。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算损失函数的命名空间。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 定义学习率、优化方法及每一轮执行训练的操作的命名空间。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
writer = tf.summary.FileWriter("log", tf.get_default_graph())
# 训练模型。
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
if i % 1000 == 0:
# 配置运行时需要记录的信息。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
_, loss_value, step = sess.run(
[train_op, loss, global_step], feed_dict={x: xs, y_: ys},
options=run_options, run_metadata=run_metadata)
writer.add_run_metadata(run_metadata=run_metadata, tag=("tag%d" % i), global_step=i)
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
writer.close()
- 主函数。
def main(argv=None):
mnist = input_data.read_data_sets("../../datasets/MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
main()
4.运行结果如下图:

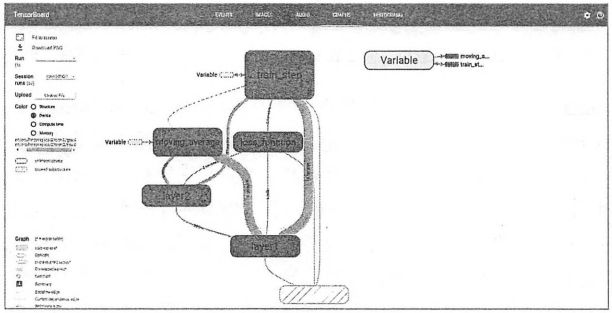
相比前面给出的mnist_train.py程序,上面程序最大的改变就是将完成类似功能的计算放到了由tf.name_scope函数生成的上下文管理器中。这样TensorBoard可以将这些节点有效地合并,从而突出神经网络的整体结构。因为在mnist_inference.py程序中已经使用了tf.variable_scope来管理变量的命名空间,所以这里不需要再做调整。下图展示了新的MNIST程序的TensorFlow计算图可视化得到的效果图:

从图中可以看到,TensorBoard可视化效果图很好地展示了整个神经网络的结构,在图中,input节点代表了训练神经网络需要的输入数据,这些输入数据会提供给神经网络的第一层layer1.然后神经网络第一层layer1的结果会被传到第二层layer2,经过layer2的计算得到前向传播的结果。loss_function节点表示计算损失函数的过程,这个过程既依赖于前向传播的结果来计算交叉熵(layer2到loss_function的边),又依赖于每一层中所定义的变量来计算L2正则化损失(layer1和layer2到loss_function的边)。loss_function的计算结果会提供给神经网络的优化过程,也就是图中train_step所代表的节点。综上所述,通过TensorBoard可视化得到的效果图可以对整个神经网络的网络结构有一个大致了解。
在图中可以发现节点之间有两种不同的边。一种边是通过实线表示的,这种边刻画了数据传输,边上的箭头方向表达了数据传输的方向。比如layer1和layer2之间的边表示了layer1的输出将会作为layer2的输入。有些边上的箭头是双向的,比如节点Variable和train_step之间的边。这表明train_step会修改Variable的状态,在这里也就是表明训练过程会修改记录训练迭代轮数的变量。
TensorBoard可视化效果图的边上还标注了张量的维度信息。下图放大了可视化得到的效果图:
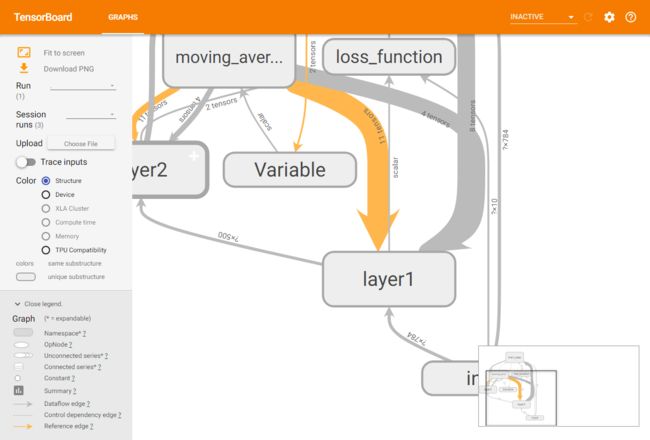
从图中可以看出,节点input和layer1之间传输的张量的维度为100*784.这说明了训练时提供的batch大小为100,输入层节点的个数为784.当两个节点之间传输的张量多于1个时,可视化效果图上将只显示张量的个数。效果图上边的粗细表示的是两个节点之间传输的标量维度的总大小,而不是传输的标量个数。比如layer2和loss_function之间虽然传输了两个张量,但其维度都比较小,所以这条边比layer1和layer2之间的边还要细。
TensorBoard可视化效果图上另外一种边是通过虚线表示的,比如图中所示moving_average和train_step之间的边。虚边表达了计算之间的依赖关系,比如在程序中,通过tf.control_dependencies函数指定了更新参数滑动平均值的操作和通过反方向传播更新变量的操作需要同时进行,于是moving_average与train_step之间存在一条虚边。
除了手动的通过TensorFlow中的命名空间来调整TensorBoard的可视化效果图,TensorBoard也会智能地调整可视化效果图上的节点。TensorFlow中部分计算节点会有比较多的依赖关系,如果全部画在一张图上会使可视化得到的效果图非常拥挤。于是TensorBoard将TensorFlow计算图分成了主图(Main Graph)和辅助图(Auxiliary nodes)两个部分来呈现。上面第一个图中,左侧展示的是计算图的主要部分,也就是主图;右侧展示的是一些单独列出来的节点,也就是辅助图。TensorBoard会自动将连接比较多的节点放在辅助图中,使得主图的结构更加清晰。
除了自动的方式,TensorBoard也支持手工的方式来调整可视化效果,如下图所示:

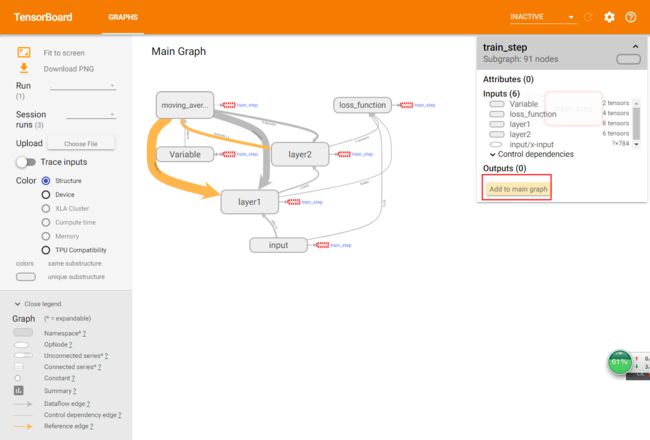
如图,右键单击可视化效果图上的节点会弹出一个选项,这个选项可以将节点加入主图或者从主图中删除。左键选择一个节点并点击信息框下部的选项也可以完成类似的功能。
2.2节点信息
除了展示TensorFlow计算图的结构,TensorBoard还可以展示TensorFlow计算图上每个节点的基本信息以及运行时消耗的时间和空间。本小节将进一步讲解如何通过TensorBoard展现TensorFlow计算图节点上的这些信息。TensorFlow计算节点的运行时间都是非常有用的信息,它可以帮助更加有针对性地优化TensorFlow程序,使得整个程序的运行速度更快。使用TensorBoard可以非常直观地展现所有TensorFlow计算节点在某一次运行时所消耗的时间和内存。将以下代码加入上一小节中修改后的mnist_train.py神经网络训练部分,就可以将不同迭代轮数时每一个TensorFlow计算节点的运行时间和消耗的内存写入TensorBoard的日志文件中:
# 训练模型。
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 每1000轮记录一次运行状态
if i % 1000 == 0:
# 配置运行时需要记录的信息。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
# 将配置信息和记录运行信息的proto传入运行的过程,从而记录运行时每一个节点的时间、空间开销信息
_, loss_value, step = sess.run(
[train_op, loss, global_step], feed_dict={x: xs, y_: ys},
options=run_options, run_metadata=run_metadata)
# 将节点在运行时的信息写入日志文件
writer.add_run_metadata(run_metadata=run_metadata, tag=("tag%d" % i), global_step=i)
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
运行以上程序,并使用这个程序输出的日志启动TensorBoard,就可以可视化每个TensorFlow计算节点在某一次运行时所消耗的时间和空间了。进入GRAPHS栏后,需要先选择一次运行来查看。
如下图所示:

如图所示,点击页面左侧的Session.runs选项会出现一个下拉单,在这个下拉单中会出现所有通过train_writer.add_run_metadata函数记录的运行数据。选择一次运行后,TensorBoard左侧的Color栏中将会新出现Computetime和Memory这两个选项。
在Color栏中选择Compute time可以看到在这次运行中每个TensorFlow计算节点的运行时间。类似的,选择Memory可以看到这次运行中每个TensorFlow计算节点所消耗的内存。下图展示了在第2000轮迭代时,不同TensorFlow计算节点时间消耗的可视化效果图:

上图中颜色越深的节点表示时间消耗越大。从图中可以看出,代表训练神经网络的train_step节点消耗的时间是最多的。通过对每一个计算节点消耗时间的可视化,可以很容易地找到TensorFlow计算图上的性能瓶颈,这大大方便了算法优化的工作。在性能调优时,一般会选择迭代轮数较大时的数据(比如上图中第2000轮迭代时的数据)作为不同计算节点时间/空间消耗的标准,因为这样可以减少TensorFlow初始化对性能的影响。
在TensorBoard界面左侧的Color栏中,除了Compute time和Memory,还有Structure和Device两个选项。除了上一图,在上面几个图中,展示的可视化效果图都是使用默认的Structure选项。在这个视图中,灰色的节点表示没有其他节点和它拥有相同结构。如果有两个节点的结构相同,那么它们会被涂上相同的颜色。下图展示了一个拥有相同结构节点的卷积神经网络可视化得到的效果图:
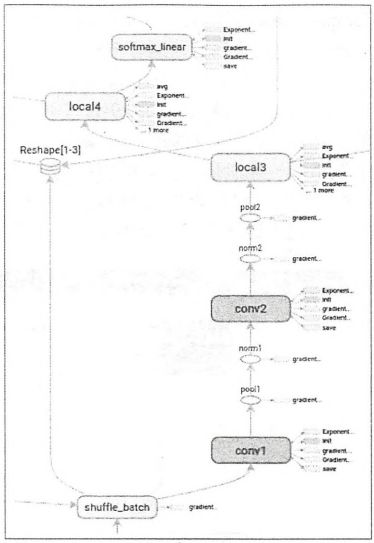
在上图中,两个卷积层的结构是一样的,所以他们都被涂上了相同的颜色。最后,Color栏还可以选择Device选项,这个选项可以根据TensorFlow计算节点运行的机器给可视化效果图上的节点染色。在使用GPU时,可以通过这种方式直观地看到哪些计算节点被放到了GPU上。下图给出了一个使用了GPU的TensorFlow计算图的可视化效果:
上图中深灰色的节点表示对应的计算放在了GPU上,浅灰色的节点表示对应的计算放在了CPU上。具体如何使用GPU将在下一章介绍。
当点击TensorBoard可视化效果图中的节点时,界面的右上角会弹出一个信息卡片显示这个节点的基本信息,如下图:

当点击的节点为一个命名空间时,TensorBoard展示的信息有这个命名空间内所有计算节点的输入、输出以及依赖关系。虽然属性(Attribute)也会展示在卡片中,但是在代表命名空间的属性下不会有任何内容。当Session.runs选择了某一次运行时,节点的信息卡片上会出现这个节点运行所消耗的时间和内存等信息。
当点击的TensorBoard可视化效果图上的节点对应一个TensorFlow计算节点时,TensorBoard也会展示类似的信息。下图展示了一个TensorFlow计算节点所对应的信息卡片:

3.监控指标可视化
在上一节中着重介绍了通过TensorBoard的GRAPHS栏可视化TensorFlow计算图的结构以及在计算图上的信息。TensorBoard除了可以可视化TensorFlow的计算图,还可以可视化TensorFlow程序运行过程中各种有助于了解程序运行状态的监控指标。在本节中将介绍如何利用TensorBoard中其他栏目可视化这些监控指标。除了Graphs栏,TensorBoard界面中还提供了EVENTS/IMAGES/AUDIO和HISTOGRAMS四个栏目来可视化其他的监控指标。下面的程序展示了如何将TensorFlow程序运行时的信息输出到TensorBoard日志文件中:
1.定义变量
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
2.生成变量监控信息并定义生成监控信息日志的操作。
SUMMARY_DIR = "C:/log/supervisor.log"
BATCH_SIZE = 100
TRAIN_STEPS = 3000
# var:需要记录的张量
# name:可视化结果中显示的图表名称,这个名称一般与变量名一致
def variable_summaries(var, name):
# 将生成监控信息的操作放到同一个命名空间下
with tf.name_scope('summaries'):
# tf.summary.histogram:记录张量中元素的取值分布
tf.summary.histogram(name, var)
# 计算变量的平均值
mean = tf.reduce_mean(var)
tf.summary.scalar('mean/' + name, mean)
# 计算变量的标准差
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev/' + name, stddev)
3.生成一层全链接的神经网络
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
# 将同一层神经网络放在一个统一的命名空间下
with tf.name_scope(layer_name):
# 声明神经网络边上的权重,并调用生成权重监控信息日志的函数
with tf.name_scope('weights'):
weights = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
variable_summaries(weights, layer_name + '/weights')
# 声明神经网络的偏置项,并调用生成偏置项监控信息日志的函数
with tf.name_scope('biases'):
biases = tf.Variable(tf.constant(0.0, shape=[output_dim]))
variable_summaries(biases, layer_name + '/biases')
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
# 记录神经网络输出节点在经过激活函数之前的分布
tf.summary.histogram(layer_name + '/pre_activations', preactivate)
activations = act(preactivate, name='activation')
# 记录神经网络节点输出在经过激活函数之后的分布。
tf.summary.histogram(layer_name + '/activations', activations)
return activations
def main():
mnist = input_data.read_data_sets("../../datasets/MNIST_data", one_hot=True)
# 定义输入
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
# 将输入向量还原成图片的像素矩阵,并通过tf.summary.image将当前的图片信息写入日志的操作
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
hidden1 = nn_layer(x, 784, 500, 'layer1')
y = nn_layer(hidden1, 500, 10, 'layer2', act=tf.identity)
# 计算交叉熵并定义生成交叉熵监控日志的操作
with tf.name_scope('cross_entropy'):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
tf.summary.scalar('cross_entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
# 计算模型在当前给定数据上的正确率
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# tf.summary.merge_all:整理所有的日志生成操作
merged = tf.summary.merge_all()
with tf.Session() as sess:
# 初始化写日志的writer,并将当前TensorFlow计算图写入日志
summary_writer = tf.summary.FileWriter(SUMMARY_DIR, sess.graph)
tf.global_variables_initializer().run()
for i in range(TRAIN_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 运行训练步骤以及所有的日志生成操作,得到这次运行的日志。
summary, _ = sess.run([merged, train_step], feed_dict={x: xs, y_: ys})
# 将得到的所有日志写入日志文件,这样TensorBoard程序就可以拿到这次运行所对应的
# 运行信息。
summary_writer.add_summary(summary, i)
summary_writer.close()
if __name__ == '__main__':
main()
运行代码,如下图所示:

运行完之后,在C:/log/supervisor.log目录,会发现有个文件events.out.tfevents.1567588311.1002330QL,在命令行执行命令:
tensorboard --logdir=C:/log/supervisor.log
再到浏览器访问: http://localhost:6006
可以得到如下图所示的结果:

从程序中可以看出,除了GRSPHS之外,TensorBoard中的每一栏对应了TensorFlow中一种日志生成函数,下表总结了这个对应关系: