相关性分析
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性分析旨在研究两个或两个以上随机变量之间相互依存关系的方向和密切程度。
一般来讲研究对象(样品或处理组)之间使用距离分析,而元素(物种或环境因子)之间进行相关性分析。两个变量之间的相关性可以用简单相关系数(例如皮尔森相关系数等)进行表示,相关系数越接近1,两个元素相关性越大,相关系数越接近0,两个元素越独立。
相关性指标
(1)Pearson相关系数(皮尔逊积差相关系数)
Pearson相关系数是用于表示相关性大小的最常用指标,数值介于-1~1之间,越接近0相关性越低,越接近-1或1相关性越高。正负号表明相关方向,正号为正相关、负号为负相关。适用于两个正态分布的连续变量。
(2)Spearman等级相关系数(斯皮尔曼秩相关系数)
利用两变量的秩次大小来进行分析,属于非参数统计方法。适用于不满足Pearson相关系数正态分布要求的连续变量。也可以用于有序分类变量的之间的相关性测量。
(3)Kendall's Tau相关系数
Kendall's Tau相关系数是一种非参数检验,适用于两个有序分类变量。
(4)其它
此外衡量两个变量之间关系的方法还有:卡方检验、Fisher精确检验等。
cor函数
Pearson、Spearman、Kendall相关系数都可以通过cor函数实现,cov协方差函数参数同cor函数。
(1)用法
cor(x,y=NULL,use="everything",method= c("pearson","kendall","spearman"))
cor(x, use='everything', method='pearson') #计算矩阵相关系数
cor(mtcars$mpg, mtcars$cyl) #计算两两相关系数
- x:矩阵或数据框。
- use:指定缺失数据的处理方式。可选项:all.obs(假设不存在缺失数据)、everything(数据存在缺失值时,相关系数计算结果会显示missing)、complete.obs(行删除)、pairwise.complete.obs(成对删除)。
- method:指定相关系数的类型。可选类型为pearson、spearman、kendall。
(2)R Script
> testdata1[1:5,1:5] #随意找的数据
CF1 CF2 CF3 CF4 CM1
rna13468 66.97984 80.07318 54.87525 91.65463 1.401584
rna885 26.53467 44.51450 33.65076 40.72113 60.633389
rna32332 0.00000 37.71825 11.89813 0.00000 1.403419
rna8744 42.44415 52.31791 60.35968 54.00533 39.524090
rna16488 0.00000 0.00000 0.00000 0.00000 0.000000
> cor_data <- cor(testdata1,method="pearson")
> round(cor_data[1:5,1:5],3)
CF1 CF2 CF3 CF4 CM1
CF1 1.000 0.668 0.697 0.952 -0.129
CF2 0.668 1.000 0.923 0.664 -0.534
CF3 0.697 0.923 1.000 0.647 -0.386
CF4 0.952 0.664 0.647 1.000 -0.203
CM1 -0.129 -0.534 -0.386 -0.203 1.000
> cor_data <- cor(testdata1,method="spearman")
> round(cor_data[1:5,1:5],3)
CF1 CF2 CF3 CF4 CM1
CF1 1.000 0.728 0.706 0.904 -0.055
CF2 0.728 1.000 0.785 0.734 -0.373
CF3 0.706 0.785 1.000 0.605 -0.212
CF4 0.904 0.734 0.605 1.000 -0.182
CM1 -0.055 -0.373 -0.212 -0.182 1.000
corrplot
(1)用法
corrplot(corr, #相关性系数矩阵
method = c("circle", "square", "ellipse", "number", "shade", "color", "pie"),
#可视化的方法,可以是圆形、方形、椭圆形、数值、阴影、颜色或饼图形
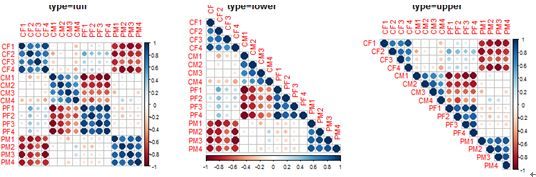
type = c("full", "lower", "upper"),
#指定展示的方式,可以是完全的、下三角或上三角
add = FALSE,
col = NULL, #指定图形展示的颜色,默认以均匀的颜色展示
bg = "white", #背景色
title = "", #标题
is.corr = TRUE, #是否为相关系数绘图
diag = TRUE, #是否展示对角线上的结果
outline = FALSE, #是否绘制圆形、方形或椭圆形的轮廓
mar = c(0,0,0,0), #设置图形的四边间距
addgrid.col = NULL,
#当选择的方法为颜色或阴影时,默认的网格线颜色为白色,否则为灰色
addCoef.col = NULL,
#为相关系数添加颜色,默认不添加相关系数,只有方法为number时,该参数才起作用
addCoefasPercent = FALSE, #是否将相关系数转换为百分比格式
order = c("original", "AOE", "FPC", "hclust", "alphabet"),
#指定相关系数排序的方法,可以是原始顺序original、特征向量角序AOE、第一主成分顺序FPC、
#层次聚类顺序hclust和字母顺序,一般AOE排序结果都比FPC要好
hclust.method = c("complete", "ward", "single", "average",
"mcquitty", "median", "centroid"),
#当order为hclust时,该参数可以是层次聚类中的7种之一
addrect = NULL, #当order为hclust时,可以为添加相关系数图添加矩形框
rect.col = "black", #指定矩形框的颜色
rect.lwd = 2, #指定矩形框的线宽
tl.pos = NULL,
#指定文本标签(变量名称)的位置,当type=full时,默认标签位置在左边和顶部(lt),
#当type=lower时,默认标签在左边和对角线(ld),当type=upper时,默认标签在顶部和对角线,
#d表示对角线,n表示不添加文本标签
tl.cex = 1, #指定文本标签的大小
tl.col = "red", #指定文本标签的颜色
tl.offset = 0.4, tl.srt = 90,
cl.pos = NULL,
#图例(颜色)位置,当type=upper或full时,图例在右侧,当type=lower时,图例在底部,
#不需要图例时,只需指定该参数为n
cl.lim = NULL,
cl.length = NULL, cl.cex = 0.8, cl.ratio = 0.15,
cl.align.text = "c",cl.offset = 0.5,
addshade = c("negative", "positive", "all"),
#只有当method=shade时,该参数才有用,参数值可以是negative/positive和all,分别表示对负相关系数、
#正相关系数和所有相关系数添加阴影。注意:正相关系数的阴影是45度,负相关系数的阴影是135度
shade.lwd = 1, #指定阴影的线宽
shade.col = "white", #指定阴影线的颜色
p.mat = NULL, sig.level = 0.05,
insig = c("pch","p-value","blank", "n"),
pch = 4, pch.col = "black", pch.cex = 3,
plotCI = c("n","square", "circle", "rect"),
lowCI.mat = NULL, uppCI.mat = NULL, ...)
(2)R Script
library(corrplot)
##默认参数
corrplot(cor_data)

##可视化方法
#"circle", "square", "ellipse", "number", "shade", "color", "pie"
corrplot(cor_data, method="pie",title="method=pie")

##展示的方式
#"full", "lower", "upper"
corrplot(cor_data, type="upper",title="type=upper")
##混合图形样式
#corrplot.mixed(matrix,lower="number",upper="circle")
#tl.col修改对角线的颜色,lower.col修改下三角的颜色,number.cex修改下三角字体大小
corrplot.mixed(cor_data,lower="ellipse",upper="pie")
corrplot.mixed(cor_data,lower="number",upper="pie",
tl.col="green",lower.col="skyblue",number.cex=1)

##order
#"original", "AOE", "FPC", "hclust", "alphabet"
#如果是hclust:
#addrect=4 是分组矩形
#rect.col = "black" 矩形框的颜色
#rect.lwd = 2 矩形框的线宽
#hclust.method = c("complete", "ward", "single", "average",
#"mcquitty", "median", "centroid")
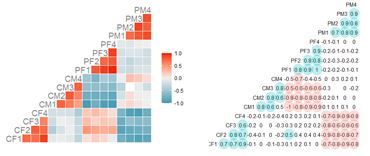
corrplot(cor_data,order="hclust",hclust.method="average",addrect=4)
corrplot(cor_data,order="AOE")

##颜色
col1 <- colorRampPalette(c("blue","white","red"))
corrplot(cor_data,order="hclust",addrect=4,
col=col1(100),
bg="khaki1",addgrid.col="green",
tl.col="purple",tl.cex=0.7)

##添加数字
corrplot(cor_data,method="color",order="hclust",addrect=4,
col=col1(100),
tl.col="black",addCoef.col="grey",addCoefasPercent=T)

ggcorrplot
ggcorrplot包内只有2个函数,一个cor_pmat()用于计算p值,一个ggcorrplot()用于绘图。ggcorrplot相当于精简版的corrplot包,只有主题更加丰富多样。
(1)用法
ggcorrplot(corr, method = c("square", "circle"), type = c("full", "lower", "upper"),
ggtheme = ggplot2::theme_minimal, title = "",
show.legend = TRUE, legend.title = "Corr",
show.diag = FALSE,
colors = c("blue", "white", "red"), outline.color = "gray",
hc.order = FALSE, hc.method = "complete",
lab = FALSE, lab_col = "black", lab_size = 4, p.mat = NULL, sig.level = 0.05,
insig = c("pch", "blank"), pch = 4, pch.col = "black", pch.cex = 5,
tl.cex = 12, tl.col = "black", tl.srt = 45, digits = 2 )
(2)R Script
library(ggcorrplot)
##计算p值
cor_p <- cor_pmat(cor_data)
round(cor_p[1:5,1:5],3)
##默认绘图square
ggcorrplot(cor_data)
##可视化方法
ggcorrplot(cor_data,method="circle")
##使用聚类顺序
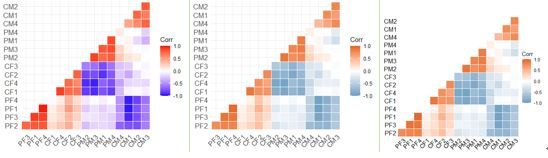
ggcorrplot(cor_data,hc.order=TRUE,outline.color="white")

##展示的方式
ggcorrplot(cor_data,hc.order=TRUE,outline.color="white",
type="lower")
##更改颜色
ggcorrplot(cor_data,hc.order=TRUE,outline.color="white",
type="lower",colors = c("#6D9EC1", "white", "#E46726"))
##更改主题
ggcorrplot(cor_data,hc.order=TRUE,outline.color="white",
type="lower",colors = c("#6D9EC1", "white", "#E46726"),
ggtheme = ggplot2::theme_void())
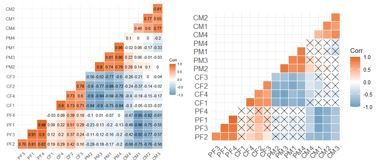
#添加相关系数
ggcorrplot(cor_data,hc.order=TRUE,outline.color="white",
type="lower",colors = c("#6D9EC1", "white", "#E46726"),
lab = TRUE)
#不显著的画x
ggcorrplot(cor_data,hc.order=TRUE,outline.color="white",
type="lower",colors = c("#6D9EC1", "white", "#E46726"),
p.mat = cor_p)
ggcorr
(1)R Script
##计算相关系数
ggcorr(testdata1,method=c("pairwise","spearman"))
##指定颜色标度中包含的断点数
ggcorr(testdata1,method=c("pairwise","spearman"),
nbreaks = 5)
##设置图例
ggcorr(testdata1,method=c("pairwise","spearman"),
name="12345", legend.position="bottom", legend.size=12) +
guides(fill=guide_colorbar(barwidth=18, title.vjust=0.75)) +
theme(legend.title=element_text(size=14))

##设置颜色
ggcorr(testdata1,method=c("pairwise","spearman"),
low="steelblue", mid="white", high="darkred")
##画圆形
ggcorr(testdata1,method=c("pairwise","spearman"),
geom = "circle",min_size=2,max_size=6)
##添加相关系数
ggcorr(testdata1,method=c("pairwise","spearman"),
label=TRUE,label_size=3,label_color="white")
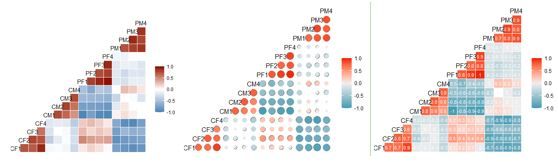
##控制变量标签
ggcorr(testdata1,method=c("pairwise","spearman"),
hjust=0.75, size=5, color="grey50",layout.exp=1)
##显示较高的相关系数
ggcorr(testdata1,method=c("pairwise","spearman"),
label=TRUE, hjust=0.75,geom="blank") +
geom_point(size=10, aes(color=coefficient>0,
alpha=abs(coefficient)>0.5)) +
scale_alpha_manual(values=c("TRUE"=0.25,"FALSE"=0)) +
guides(color=FALSE,alpha=FALSE)
样品间相似性(similarity)和距离(distance)
(1)表示距离的方法
- 欧式距离(Euclidean Distance)
√(a2+b2+c^2)
dist(t(x),p=2) - 曼哈顿距离(Manhattan Distance)
|a1-a2|+|b1-b2|+|c1-c2|
dist(t(x),"manhattan") - 切比雪夫距离(Chebyshev Distance)
max(|a1-a2|,|b1-b2|,|c1-c2|)
dist(t(x),"maximum") - 闵可夫斯基距离(Minkowski Distance)
dist(t(x),"minkowski") - 标准化欧氏距离(Standardized Euclidean distance)
先将数据各维分量标准化到均值方差相等,即(x-μ)/δ,标准化后的值=(标准化前的值-分量的均值)/分量的标准差。
x1 = scale(t(x), center=T,scale=T)
dist(x1) - 马氏距离(Mahalanobis Distance)
- 兰式距离
dist(t(x), method = "canberra") - 夹角余弦(Cosine)
- 汉明距离(Hamming distance)
两个等长字符串s1与s2之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。
x <- c(1, 0, 0)
y <- c(1, 0, 1)
hamming.distance(x, y) #1 - 杰卡德相似系数(Jaccard similarity coefficient)
dist(t(x), method = "Jaccard") - 相关系数(Correlation coefficient)与相关距离(Correlation distance)
1-cor(x) - 信息熵(Information Entropy)
信息熵是衡量分布的混乱程度或分散程度的一种度量。分布越分散(分布越平均),信息熵就越大。分布越有序(分布越集中),信息熵就越小。 - kl散度
(2)dist用法
This function computes and returns the distance matrix computed by using the specified distance measure to compute the distances between the rows of a data matrix.
这个函数用特定的方法计算矩阵的行之间的距离,并返回距离矩阵。
dist(x, method = "euclidean", diag = FALSE, upper = FALSE, p = 2)
- method:可以是"euclidean", "maximum", "manhattan", "canberra", "binary", "minkowski"
- diag:是否显示对角线的值
- upper:是否显示上三角的值
- p:The power of the Minkowski distance
(3)scale用法
scale(x, center = TRUE, scale = TRUE)
scale是对矩阵的每一列进行标准化,如果要对行标准化需要先转置。如heatmapdata <- t(scale(t(heatmapdata)))
(4)R Script
sampleDist <- dist(t(testdata1))
sampleDistMatrix <- as.matrix(sampleDist)
colnames(sampleDistMatrix) <- NULL
colors <- colorRampPalette(rev(brewer.pal(9,"Blues")))(255)
pheatmap(sampleDistMatrix,
clustering_distance_rows=sampleDist,
clustering_distance_cols=sampleDist,
color = colors)
