5月31日 12:00 小雨
1.主成分分析原理
翻了很多帖子没有一个可以直接看懂的,每个帖子的说法用词虽然略微不一样,切入点都差不多,感觉都是从一个地方抄过来稍加修改而已。特别是从协方差忽然就切入特征值特征向量,让数学门外汉摸不着头脑。
参考书:<多変量解析II 主成分分析 理論とRによる演習>
使用数据:mtcars
关键词:
1.协方差矩阵
2.特征向量,特征值
主成分分析的目的:
很简单:降低维度(去噪)将一组N维数据降成K维(K小于N)
原始数据Z在主成分向量l上的投影X最大
X=Z*l (Z已知,求l以及l相对应的X)
这里就产生了两个条件(如下)为了达到这个目的就得满足两个条件
- 投影X最大(为了实现最小数据损失)
- 主成分向量l必须是单位直交向量
- 为了求上述方程的解,就使用到了拉格朗日定理,经过推导(详细略)最后相当于将原始数据Z的协方差矩阵对角化,并求出协方差矩阵的特征值和特征向量。
这样就把协方差矩阵和特征值特征向量之间的关系给连起来了。原来并不是人家说的不明白,是自己数学知识不够,之前没听说过拉格朗日定理。详细推导过程了解一下就好,完全没有必要记住甚至钻牛角尖。只要明白为什么求主成分忽然变成了求协方差矩阵的特征值和特征向量就好
0614 11:07 补充
- 特征向量的理解: 原数据投影的地方( 角度)?是单位向量
特征值: 投影的大小
可以用高中物理力的分解思维来反向理解。
理解协方差矩阵
协方差矩阵本质就是一个相关系数矩阵求协方差矩阵的特征值和特征向量
原始数据的标准化数据乘以各特征向量就是各组数据在主成分上的投影,也就是各组数据的主成分得点。(PCA score)Loading Score
概念有点晕,可以理解成原始数据各维度和每个主成分的相关度。
计算:特征值开方以后乘以对应的特征向量。
2. R语言实现
不使用自带函数,手动计算
- 使用数据:
mtcars
Z<-as.matrix(mtcars)
n<-nrow(Z)
Z_scl<-scale(Z)
S<-(1/(n-1))*t(Z_scl)%*%Z_scl #各个维度的写相关矩阵,本数据有11各变量
> head(S)
mpg cyl disp hp drat wt qsec vs
mpg 1.0000000 -0.8521620 -0.8475514 -0.7761684 0.6811719 -0.8676594 0.41868403 0.6640389
cyl -0.8521620 1.0000000 0.9020329 0.8324475 -0.6999381 0.7824958 -0.59124207 -0.8108118
disp -0.8475514 0.9020329 1.0000000 0.7909486 -0.7102139 0.8879799 -0.43369788 -0.7104159
hp -0.7761684 0.8324475 0.7909486 1.0000000 -0.4487591 0.6587479 -0.70822339 -0.7230967
drat 0.6811719 -0.6999381 -0.7102139 -0.4487591 1.0000000 -0.7124406 0.09120476 0.4402785
wt -0.8676594 0.7824958 0.8879799 0.6587479 -0.7124406 1.0000000 -0.17471588 -0.5549157
am gear carb
mpg 0.5998324 0.4802848 -0.5509251
cyl -0.5226070 -0.4926866 0.5269883
disp -0.5912270 -0.5555692 0.3949769
hp -0.2432043 -0.1257043 0.7498125
drat 0.7127111 0.6996101 -0.0907898
wt -0.6924953 -0.5832870 0.4276059
Eigen_value<-eigen(S) #11组特征值 以及 相对应的特征向量
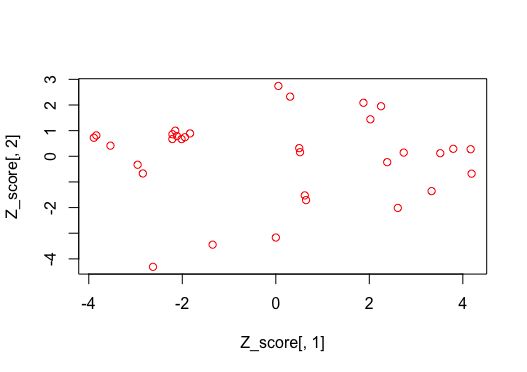
Z_score<-Z_scl %*% Eigen_value$vectors #Z标准化后的主成分得点
> head(Z_score)
[,1] [,2] [,3] [,4] [,5] [,6]
Mazda RX4 0.64686274 -1.7081142 -0.5917309 0.11370221 0.9455234 0.01698737
Mazda RX4 Wag 0.61948315 -1.5256219 -0.3763013 0.19912121 1.0166807 0.24172464
Datsun 710 2.73562427 0.1441501 -0.2374391 -0.24521545 -0.3987623 0.34876781
Hornet 4 Drive 0.30686063 2.3258038 -0.1336213 -0.50380035 -0.5492089 -0.01929700
Hornet Sportabout -1.94339268 0.7425211 -1.1165366 0.07446196 -0.2075157 -0.14919276
Valiant 0.05525342 2.7421229 0.1612456 -0.97516743 -0.2116654 0.24383585
[,7] [,8] [,9] [,10] [,11]
Mazda RX4 -0.42648652 0.009631217 0.14642303 -0.06670350 -0.17969357
Mazda RX4 Wag -0.41620046 0.084520213 0.07452829 -0.12692766 -0.08864426
Datsun 710 -0.60884146 -0.585255765 -0.13122859 0.04573787 0.09463291
Hornet 4 Drive -0.04036075 0.049583029 0.22021812 -0.06039981 -0.14761127
Hornet Sportabout 0.38350816 0.160297757 -0.02117623 -0.05983003 -0.14640690
Valiant -0.29464160 -0.256612420 -0.03222907 -0.20165466 -0.01954506
plot(Z_score[,1],Z_score[,2],col="red",pch=1) #PC1和PC2的plot
0614 10:41 Revised
root_eigen<-sqrt(Eigen_value$values) #开方特征值
#一开始算错了~~loading_score<-root_eigen * Eigen_value$vectors ~~
loading_score<-t(root_eigen * t(Eigen_value$vectors))
#特征值的开方*各特征向量
loading_label<-c(1:11) #给每各变量指定标签
loading_data<-data.frame(loading_score,loading_label)
plot(loading_data$X1,loading_data$X2,col=loading_label,pch=loading_label)
#各变量与PC1,PC2的相关图

prcomp( )函数
难度瞬间降低,不要忘了标准化数据scale=TRUE
函数: prcomp( )
$x: 主成分得点
$sdev: 特征值的平方根
$rotation: 特征向量
$center: 各维度的平均值
- Loading Score 主成分负荷量(prcomp( )里没有包含,需要另外计算)
主成分负荷量就是最后得到的特征值的平方根($sdev)乘以特征向量($rotation)
- 可以用mtcars来实战一下
pca_mtcars<-prcomp(mtcars,scale=T)
summary(pca_mtcars)
> summary(pca_mtcars)
Importance of components:
PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10
Standard deviation 2.571 1.628 0.792 0.5192 0.4727 0.4600 0.3678 0.3506 0.278 0.22811
Proportion of Variance 0.601 0.241 0.057 0.0245 0.0203 0.0192 0.0123 0.0112 0.007 0.00473
Cumulative Proportion 0.601 0.842 0.899 0.9232 0.9436 0.9628 0.9751 0.9863 0.993 0.99800
PC11
Standard deviation 0.148
Proportion of Variance 0.002
Cumulative Proportion 1.000
1.到此差不多大功告成,不得再次吐槽一下的Markdown,不能改字体,数据显示的太别扭了。
2.PCA数据优雅可视化的话需要用ggplot,放到以后再说吧。
3. 根据 prcomp( ) 自编可计算Loading Score的函数
0611 16:11
pca <- function(matr, scla=TRUE){
respca <- summary(prcomp(matr, scale=scl))
n <- nrow(matr)
if(scla) {
respca$loadings <- t(respca$sdev * t(respca$rotation))
}
else {
respca$loadings <- t(respca$sdev * t(respca$rotation)) / apply(matr, 2, sd)
}
respca$loadings[is.nan(respca$loadings)] <- 0
return(respca)
}
哈哈,这几天的R编程知识没有白补。虽然磕磕碰碰,但也算写出来了。
- 测试一下吧
pcamt<-pca(mtcars)
pcamt$loadings
> head(pcamt$loadings)
PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10
mpg -0.932 0.0263 -0.1788 -0.01170 0.0486 -0.0500 0.13524 -0.26436 0.0654 0.0318
cyl 0.961 0.0712 -0.1388 -0.00135 0.0276 0.0775 0.02107 -0.08092 0.0150 -0.1931
disp 0.946 -0.0803 -0.0487 0.13324 0.1862 -0.1546 0.07882 0.00040 0.0551 0.0113
hp 0.848 0.4050 0.1109 -0.03514 0.2553 0.0329 -0.00055 -0.07795 -0.1598 0.0565
drat -0.756 0.4472 0.1277 0.44385 0.0366 0.1125 0.00777 0.01129 -0.0130 -0.0232
wt 0.890 -0.2329 0.2707 0.12768 -0.0355 -0.2139 -0.00760 -0.00301 0.0998 0.0215
PC11
mpg -0.01854
cyl -0.02089
disp 0.09808
hp -0.03808
drat -0.00587
wt -0.08425
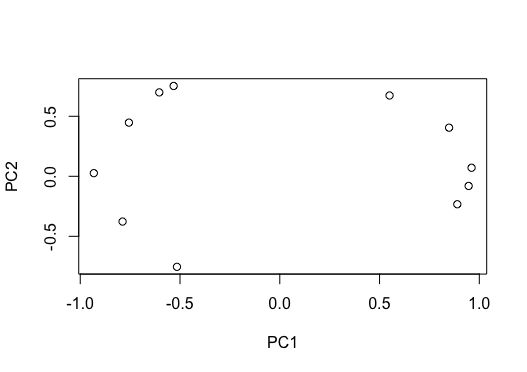
Loading Score 也就是每个变量和主成分的相关系数就这样算出来了。
当然想要plot可视化也是没有问题的。动动手就好了。
plot(pcamt$loadings)
理论上说应该还能计算loading score的p值,等之后统计知识跟上再来补充。嗯,暂时到这里,莫好高骛远。
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4015128/
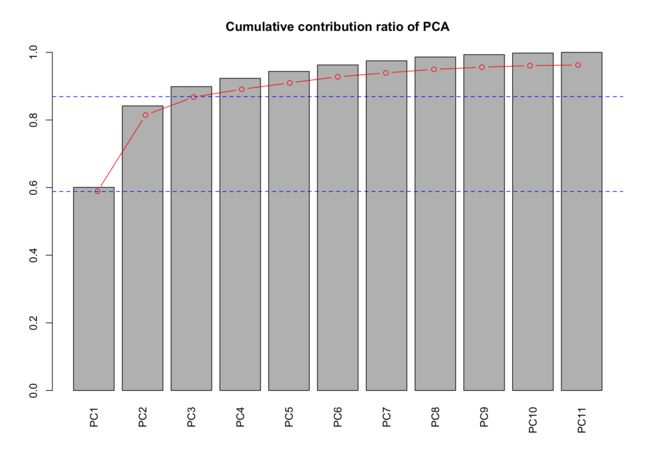
4.计算主成分累计百分比
在刚才的自编函数里添加累计值就好
respca$proportion<- respca$importance[3,]
整理一下就是
pca <- function(mat, scl=TRUE){
respca <- summary(prcomp(mat, scale=scl))
n <- nrow(mat)
respca$proportion<- respca$importance[3,]
if(scl) {
respca$loadings <- t(respca$sdev * t(respca$rotation))
}
else {
respca$loadings <- t(respca$sdev * t(respca$rotation)) / apply(mat, 2, sd)
}
respca$loadings[is.nan(respca$loadings)] <- 0
return(respca)
}
来画个画
barplot(pcamt$proportion, las = 3,
main = paste("Cumulative contribution ratio of PCA"))
par(new = TRUE)
plot(pcamt$proportion, col = 2,
type = "b", ann = F, axes = F, ylim = c(0,1),
xlim = c(0.5, length(pcamt$proportion) + 0.5))
abline(h=c(0.6,0.9),col="blue",lty=2)