2020第十一届蓝桥杯C/C++ B组省赛题目及答案 (2020.10.17)
2020第十一届蓝桥杯C/C++ B组省赛题目 (2020.10.17)
转载:https://blog.csdn.net/jziwjxjd/article/details/109136535
目录
- 2020第十一届蓝桥杯C/C++ B组省赛题目 (2020.10.17)
- 结果填空题
-
- 试题A 门牌制作
-
- 【问题描述】
- 【答案提交】
- 答案:624
- 试题B 既约分数
-
- 【问题描述】
- 【答案提交】
- 答案:2481215
- 试题C 蛇形填数
-
- 【问题描述】
- 【答案提交】
- 答案:761
- 试题D 跑步锻炼
-
- 【问题描述】
- 【答案提交】
- 答案:8879
- 试题E 七段码
-
- 【问题描述】
- 【答案提交】
- 答案:80
- 程序设计题
-
- 试题F 成绩统计
-
- 【问题描述】
- 【输入格式】
- 【输出格式】
- 【样例输入】
- 【样例输出】
- 【评测用例规模与约定】
- 答案
- 试题G 回文日期
-
- 【问题描述】
- 【输入格式】
- 【输出格式】
- 【样例输入】
- 【样例输出】
- 【评测用例规模与约定】
- 答案
- 试题H 子串分值
-
- 【问题描述】
- 【输入格式】
- 【输出格式】
- 【样例输入】
- 【样例输出】
- 【样例说明】
- 答案
- 试题I 平面切分
-
- 【问题描述】
- 【输入格式】
- 【输出格式】
- 【样例输入】
- 【样例输出】
- 【评测用例规模与约定】
- 答案
- 试题J 字串排序
-
- 【问题描述】
- 【输入格式】
- 【输出格式】
- 【样例输入】
- 【样例输出】
- 【样例输入】
- 【样例输出】
- 【评测用例规模与约定】
- 题解一
- 题解二
-
- 假算法
- 搜索+剪枝
结果填空题
试题A 门牌制作
【问题描述】
小蓝要为一条街的住户制作门牌号。
这条街一共有 2020 位住户,门牌号从 1 到 2020 编号。
小蓝制作门牌的方法是先制作 0 到 9 这几个数字字符,最后根据需要将字
符粘贴到门牌上,例如门牌 1017 需要依次粘贴字符 1、 0、 1、 7,即需要 1 个
字符 0, 2 个字符 1, 1 个字符 7。
请问要制作所有的 1 到 2020 号门牌,总共需要多少个字符 2?
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
答案:624
试题B 既约分数
【问题描述】
如果一个分数的分子和分母的最大公约数是1,这个分数称为既约分数。例如,3/4 , 5/2 , 1/8 , 7/1都是既约分数。请问,有多少个既约分数,分子和分母都是1 到2020 之间的整数(包括1和2020)?
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
答案:2481215
试题C 蛇形填数
【问题描述】
如下图所示,小明用从1 开始的正整数“蛇形”填充无限大的矩阵。
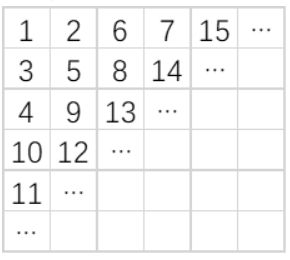
容易看出矩阵第二行第二列中的数是5。请你计算矩阵中第20 行第20 列的数是多少?
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一
个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
答案:761
#include 试题D 跑步锻炼
【问题描述】
小蓝每天都锻炼身体。
正常情况下,小蓝每天跑 1 千米。如果某天是周一或者月初(1 日),为了
激励自己,小蓝要跑 2 千米。如果同时是周一或月初,小蓝也是跑 2 千米。
小蓝跑步已经坚持了很长时间,从 2000 年 1 月 1 日周六(含)到 2020 年
10 月 1 日周四(含)。请问这段时间小蓝总共跑步多少千米?
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一
个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
答案:8879
试题E 七段码
【问题描述】
小蓝要用七段码数码管来表示一种特殊的文字。

七段码上图给出了七段码数码管的一个图示,数码管中一共有7 段可以发光的二极管,分别标记为a, b, c, d, e, f, g。小蓝要选择一部分二极管(至少要有一个)发光来表达字符。在设计字符的表达时,要求所有发光的二极管是连成一片的。
例如:b 发光,其他二极管不发光可以用来表达一种字符。
例如:c 发光,其他二极管不发光可以用来表达一种字符。这种方案与上一行的方案可以用来表示不同的字符,尽管看上去比较相似。
例如:a, b, c, d, e 发光,f, g 不发光可以用来表达一种字符。
例如:b, f 发光,其他二极管不发光则不能用来表达一种字符,因为发光的二极管没有连成一片。
请问,小蓝可以用七段码数码管表达多少种不同的字符?
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一
个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
答案:80
此题解来自:https://blog.csdn.net/weixin_43989094/article/details/109149148
//a-0,b-1,c-2,d-3,e-4,f-5,g-6
#include::iterator it;
// for(it=s.begin();it!=s.end();it++)
// {
// cout<
// }
// cout<
ans++;
}
if(s.size()==7)
return ;
for(int j=0;j<7;j++)
{
if(visit[j]||!ve[x][j])
continue;
s.insert(j);
visit[j]=1;
dfs(j,s);
visit[j]=0;
s.erase(j);
}
}
void add(int x,int y)
{
ve[x][y]=1;
ve[y][x]=1;
}
int main()
{
//a的所有边
add(0,1);
add(0,5);
//b的所有边
add(1,6);
add(1,2);
//c的所有边
add(2,6);
add(2,3);
//d的所有边
add(3,4);
//e的所有边
add(4,5);
add(4,6);
//f的所有边
add(5,6);
set<int> s;
for(int i=0;i<=6;i++)
{
s.insert(i);
visit[i]=1;
dfs(i,s);
visit[i]=0;
s.erase(i);
}
cout<<ans<<endl;
}
程序设计题
试题F 成绩统计
【问题描述】
小蓝给学生们组织了一场考试,卷面总分为 100 分,每个学生的得分都是
一个 0 到 100 的整数。
如果得分至少是 60 分,则称为及格。如果得分至少为 85 分,则称为优秀。
请计算及格率和优秀率,用百分数表示,百分号前的部分四舍五入保留整
数。
【输入格式】
输入的第一行包含一个整数 n,表示考试人数。
接下来 n 行,每行包含一个 0 至 100 的整数,表示一个学生的得分。
【输出格式】
输出两行,每行一个百分数,分别表示及格率和优秀率。百分号前的部分
四舍五入保留整数。
【样例输入】
7
80
92
56
74
88
100
0
【样例输出】
71%
43%
【评测用例规模与约定】
对于50% 的评测用例, 1 ≤ n ≤ 100。
对于所有评测用例,1 ≤ n ≤10000。
答案
#include试题G 回文日期
【问题描述】
2020 年春节期间,有一个特殊的日期引起了大家的注意:2020年2月2日。因为如果将这个日期按“yyyymmdd” 的格式写成一个8 位数是20200202,
恰好是一个回文数。我们称这样的日期是回文日期。
有人表示20200202 是“千年一遇” 的特殊日子。对此小明很不认同,因为不到2年之后就是下一个回文日期:20211202 即2021年12月2日。
也有人表示20200202 并不仅仅是一个回文日期,还是一个ABABBABA型的回文日期。对此小明也不认同,因为大约100 年后就能遇到下一个ABABBABA 型的回文日期:21211212 即2121 年12 月12 日。算不上“千年一遇”,顶多算“千年两遇”。
给定一个8 位数的日期,请你计算该日期之后下一个回文日期和下一个ABABBABA型的回文日期各是哪一天。
【输入格式】
输入包含一个八位整数N,表示日期。
【输出格式】
输出两行,每行1 个八位数。第一行表示下一个回文日期,第二行表示下
一个ABABBABA 型的回文日期。
【样例输入】
20200202
【样例输出】
20211202
21211212
【评测用例规模与约定】
对于所有评测用例,10000101 ≤ N ≤ 89991231,保证N 是一个合法日期的8位数表示。
答案
#include 试题H 子串分值
【问题描述】
对于一个字符串 S,我们定义 S 的分值 f (S ) 为 S 中出现的不同的字符个
数。例如 f (”aba”) = 2, f (”abc”) = 3, f (”aaa”) = 1。
现在给定一个字符串 S [0::n − 1](长度为 n),请你计算对于所有 S 的非空
子串 S [i:: j](0 ≤ i ≤ j < n), f (S [i:: j]) 的和是多少。
【输入格式】
输入一行包含一个由小写字母组成的字符串S。
【输出格式】
输出一个整数表示答案。
【样例输入】
ababc
【样例输出】
28
【样例说明】
子串 f值
a 1
ab 2
aba 2
abab 2
ababc 3
b 1
ba 2
bab 2
babc 3
a 1
ab 2
abc 3
b 1
bc 2
c 1
【评测用例规模与约定】
对于20% 的评测用例,1 ≤ n ≤ 10;
对于40% 的评测用例,1 ≤ n ≤ 100;
对于50% 的评测用例,1 ≤ n ≤ 1000;
对于60% 的评测用例,1 ≤ n ≤ 10000;
对于所有评测用例,1 ≤ n ≤ 100000。
答案
#include 试题I 平面切分
【问题描述】
平面上有 N 条直线,其中第 i 条直线是 y = Ai · x + Bi。
请计算这些直线将平面分成了几个部分。
【输入格式】
第一行包含一个整数 N。
以下 N 行,每行包含两个整数 Ai; Bi。
【输出格式】
一个整数代表答案。
【样例输入】
3
1 1
2 2
3 3
【样例输出】
6
【评测用例规模与约定】
对于 50% 的评测用例, 1 ≤ N ≤ 4, −10 ≤ Ai; Bi ≤ 10。
对于所有评测用例, 1 ≤ N ≤ 1000, −100000 ≤ Ai; Bi ≤ 100000。
答案
此题解来自:https://blog.csdn.net/weixin_43989094/article/details/109149148
#include试题J 字串排序
【问题描述】
小蓝最近学习了一些排序算法,其中冒泡排序让他印象深刻。
在冒泡排序中,每次只能交换相邻的两个元素。小蓝发现,如果对一个字符串中的字符排序,只允许交换相邻的两个字符,则在所有可能的排序方案中,冒泡排序的总交换次数是最少的。
例如,对于字符串 lan 排序,只需要 1 次交换。对于字符串 qiao 排序,总共需要 4 次交换。
小蓝找到了很多字符串试图排序,他恰巧碰到一个字符串,需要 V 次交换,可是他忘了把这个字符串记下来,现在找不到了。
请帮助小蓝找一个只包含小写英文字母且没有字母重复出现的字符串,对该串的字符排序,正好需要 V 次交换。如果可能找到多个,请告诉小蓝最短的那个。如果最短的仍然有多个,请告诉小蓝字典序最小的那个。请注意字符串中可以包含相同的字符。
【输入格式】
输入的第一行包含一个整数V,小蓝的幸运数字。
【输出格式】
题面要求的一行字符串。
【样例输入】
4
【样例输出】
bbaa
【样例输入】
100
【样例输出】
jihgfeeddccbbaa
【评测用例规模与约定】
对于 30% 的评测用例, 1 ≤ V ≤ 20。
对于 50% 的评测用例, 1 ≤ V ≤ 100。
对于所有评测用例, 1 ≤ V ≤ 10000。
题解一
此题解来自https://blog.csdn.net/jziwjxjd/article/details/109136535
(代码在部分数据是错的,只能算骗分代码,写错了…)
#include 题解二
此题解来自https://blog.csdn.net/calculate23/article/details/109139748
由于限定的的合法字符只有 26 个字母,假设没有这个约束可以直接按完全逆序排序使得长度最小,然后在消去部分逆序数。而对于这题,首先字母是可以重复的,并且在长度相同若要保证字典序更小显然要让较大的字母数量较少,此时只要让较小的字母较多即可。
这里可能会陷入一个可贪心的思维误区:这也是我下面展示的一个假算法的例子:错误点在字典序最优是一个全局的特性,局部字典序最优不能保证全局字典序最优,所以正解应该是搜索+剪枝。
假算法
#include 搜索+剪枝
#include