目标检测任务超大图像的切图实现
前言
难点:图像分辨率大,样本中小目标居多的情况下,如果reshape成小图再送进网络训练的话,目标会变得非常小,识别难度大。直接大图训练GPU显存又顶不住,太大的原图会消耗太多的cpu时间,导致极度拖慢训练时间,而且推理速度会很慢。
这里实现一种离线切图的形式把原图按一定的宽高,切成很多个小图进行训练。
一、实现原理
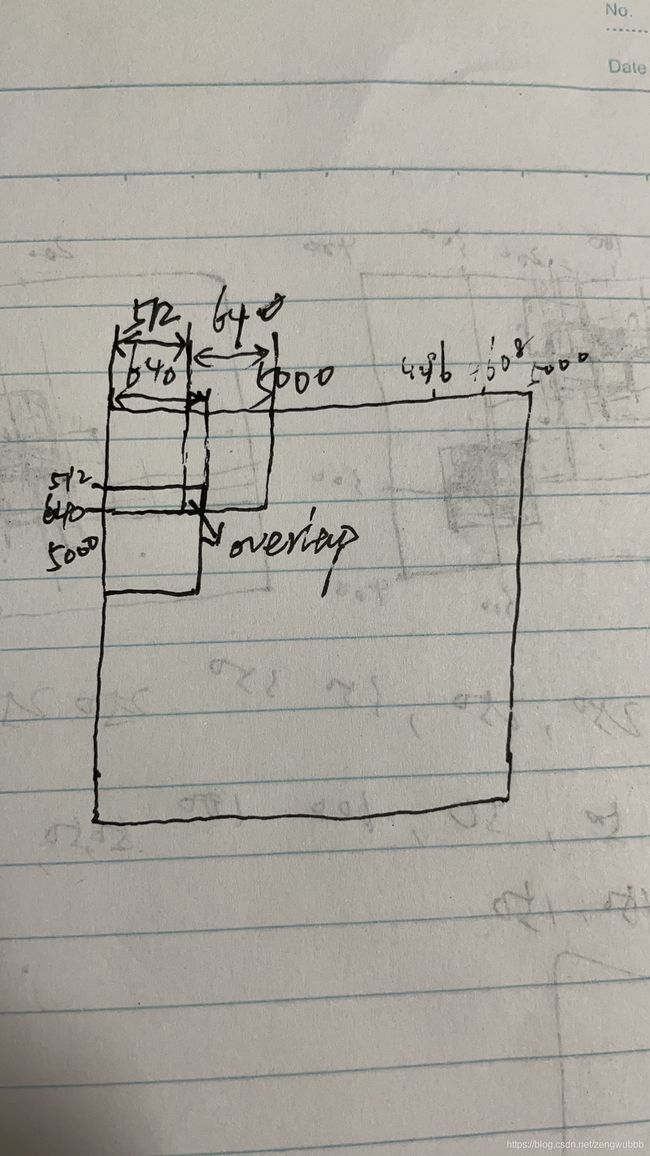
关于切图操作
待切的原图大小为:h=5000,w=5000
切图尺寸:640x640, overlop比例:0.2,则步长为512.,从左向右,自上而下依次滑动切片。
从原图左上角开始切图,切出来图像的左上角记为x,y,
那么可以容易想到y依次为:0,512,1024,…,4096,4608…但接下来最后一个窗口是4608+512>5000,所以这里要对切图的overlop做一个调整,最后一步的y=5000-640.(这很关键!!!)
关于标签的变化
根据上面的切图思路,通过划窗的方放很容易知道切出的小图的左上角点和右下角点在原图中的坐标(x, y)。那么如何把原图上的目标坐标映射到小图上呢? 这时要考虑多种情况
1 目标左上角在小图内
2 目标右下角在小图内
3 目标左上角不在小图内
4 目标右下角不在小图内
5 目标左上角在小图上方
6 目标左上角在小图左方
7 目标右下角在小图上方
8 目标右下角在小图右方
9 目标左上角在小图左上方、目标右下角在小图右下方
以上情况排列组合

实现示例代码如下,标签为VOC格式,可选择多线程单线程
# -*- coding: utf-8 -*-
"""
@Author : zengwb
@Time : 2021/4/17
@Software: PyCharm
"""
import os
import cv2
import time
import codecs
import xml.etree.ElementTree as ET
from tqdm import tqdm
import shutil
from tqdm import trange # 显示进度条
from multiprocessing import cpu_count # 查看cpu核心数
from multiprocessing import Pool
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.'%(name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.'%(name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def deal_xml(xml_f):
tree = ET.parse(xml_f)
root = tree.getroot()
object_list=[]
# 处理每个标注的检测框
for obj in get(root, 'object'):
# 取出检测框类别名称
category = get_and_check(obj, 'name', 1).text
# 更新类别ID字典
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(get_and_check(bndbox, 'xmin', 1).text) - 1
ymin = int(get_and_check(bndbox, 'ymin', 1).text) - 1
xmax = int(get_and_check(bndbox, 'xmax', 1).text)
ymax = int(get_and_check(bndbox, 'ymax', 1).text)
assert (xmax > xmin)
assert (ymax > ymin)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
obj_info=[xmin,ymin,xmax,ymax,category]
object_list.append(obj_info)
return object_list
def exist_objs(list_1,list_2, sliceHeight, sliceWidth):
'''
list_1:当前slice的图像
list_2:原图中的所有目标
return:原图中位于当前slicze中的目标集合
'''
return_objs=[]
min_h, min_w = 35, 35 # 有些目标GT会被窗口切分,太小的丢掉
s_xmin, s_ymin, s_xmax, s_ymax = list_1[0], list_1[1], list_1[2], list_1[3]
for vv in list_2:
xmin, ymin, xmax, ymax,category=vv[0],vv[1],vv[2],vv[3],vv[4]
# 1111111
if s_xmin<=xmin<s_xmax and s_ymin<=ymin<s_ymax: # 目标点的左上角在切图区域中
if s_xmin<xmax<=s_xmax and s_ymin<ymax<=s_ymax: # 目标点的右下角在切图区域中
x_new=xmin-s_xmin
y_new=ymin-s_ymin
return_objs.append([x_new,y_new,x_new+(xmax-xmin),y_new+(ymax-ymin),category])
if s_xmin<=xmin<s_xmax and ymin < s_ymin: # 目标点的左上角在切图区域上方
# 22222222
if s_xmin < xmax <= s_xmax and s_ymin < ymax <= s_ymax: # 目标点的右下角在切图区域中
x_new = xmin - s_xmin
y_new = 0
if xmax - s_ymax - x_new > min_w and ymax - s_ymax - y_new > min_h:
return_objs.append([x_new, y_new, xmax - s_ymax, ymax - s_ymax, category])
# 33333333
if xmax > s_xmax and s_ymin < ymax <= s_ymax: # 目标点的右下角在切图区域右方
x_new = xmin - s_xmin
y_new = 0
if s_xmax-s_xmin - x_new > min_w and ymax - s_ymin - y_new > min_h:
return_objs.append([x_new, y_new, s_xmax-s_xmin, ymax - s_ymin, category])
if s_ymin < ymin <= s_ymax and xmin < s_xmin: # 目标点的左上角在切图区域左方
# 444444
if s_xmin < xmax <= s_xmax and s_ymin < ymax <= s_ymax: # 目标点的右下角在切图区域中
x_new = 0
y_new = ymin - s_ymin
if xmax - s_xmin - x_new > min_w and ymax - s_ymin - y_new > min_h:
return_objs.append([x_new, y_new, xmax - s_xmin, ymax - s_ymin, category])
# 555555
if s_xmin < xmax < s_xmax and ymax >= s_ymax: # 目标点的右下角在切图区域下方
x_new = 0
y_new = ymin - s_ymin
if xmax - s_xmin - x_new > min_w and s_ymax - s_ymin - y_new > min_h:
return_objs.append([x_new, y_new, xmax - s_xmin, s_ymax - s_ymin, category])
# 666666
if s_xmin >= xmin and ymin <= s_ymin: # 目标点的左上角在切图区域左上方
if s_xmin<xmax<=s_xmax and s_ymin<ymax<=s_ymax: # 目标点的右下角在切图区域中
x_new = 0
y_new = 0
if xmax - s_xmin - x_new > min_w and ymax - s_ymin - y_new > min_h:
return_objs.append([x_new, y_new, xmax - s_xmin, ymax - s_ymin, category])
# 777777
if s_xmin <= xmin < s_xmax and s_ymin <= ymin < s_ymax: # 目标点的左上角在切图区域中
if ymax >= s_ymax and xmax >= s_xmax: # 目标点的右下角在切图区域右下方
x_new = xmin - s_xmin
y_new = ymin - s_ymin
if s_xmax - s_xmin - x_new > min_w and s_ymax - s_ymin - y_new > min_h:
return_objs.append([x_new, y_new, s_xmax - s_xmin, s_ymax - s_ymin, category])
# 8888888
if s_xmin < xmax < s_xmax and ymax >= s_ymax: # 目标点的右下角在切图区域下方
x_new = xmin - s_xmin
y_new = ymin - s_ymin
if xmax - s_xmin - x_new > min_w and s_ymax - s_ymin - y_new > min_h:
return_objs.append([x_new, y_new, xmax - s_xmin, s_ymax - s_ymin, category])
# 999999
if xmax > s_xmax and s_ymin < ymax <= s_ymax: # 目标点的右下角在切图区域右方
x_new = xmin - s_xmin
y_new = ymin - s_ymin
if s_xmax - s_xmin - x_new > min_w and ymax - s_ymin - y_new > min_h:
return_objs.append([x_new, y_new, s_xmax - s_xmin, ymax - s_ymin, category])
return return_objs
def make_slice_voc(outpath,exiset_obj_list,sliceHeight=1024, sliceWidth=1024):
name=outpath.split('/')[-1]
#
#
with codecs.open(os.path.join(slice_voc_dir, name[:-4] + '.xml'), 'w', 'utf-8') as xml:
xml.write('\n' )
xml.write('\t' + name + '\n')
xml.write('\t\n' )
xml.write('\t\t' + str(sliceWidth) + '\n')
xml.write('\t\t' + str(sliceHeight) + '\n')
xml.write('\t\t' + str(3) + '\n')
xml.write('\t\n')
cnt = 1
for obj in exiset_obj_list:
#
bbox = obj[:4]
class_name = obj[-1]
xmin, ymin, xmax, ymax = bbox
#
xml.write('\t
xml.write('\t\t' + class_name + '\n')
xml.write('\t\t\n' )
xml.write('\t\t\t' + str(int(xmin)) + '\n')
xml.write('\t\t\t' + str(int(ymin)) + '\n')
xml.write('\t\t\t' + str(int(xmax)) + '\n')
xml.write('\t\t\t' + str(int(ymax)) + '\n')
xml.write('\t\t\n')
xml.write('\t\n')
cnt += 1
assert cnt > 0
xml.write('')
###############################################################################
def slice_im(List_subsets, outdir, raw_images_dir, raw_ann_dir, i=None, sliceHeight=640, sliceWidth=640,
zero_frac_thresh=0.2, overlap=0.2, verbose=True):
cnt = 0
# print(List_subsets)
for per_img_name in tqdm(List_subsets):
# print(per_img_name)
# if 'c' not in per_img_name:
# continue
o_name, _ = os.path.splitext(per_img_name)
out_name = str(o_name) + '_' + str(cnt)
image_path = os.path.join(raw_images_dir, per_img_name)
ann_path = os.path.join(raw_ann_dir, per_img_name[:-4] + '.xml')
image0 = cv2.imread(image_path, 1) # color
ext = '.' + image_path.split('.')[-1]
win_h, win_w = image0.shape[:2]
# if slice sizes are large than image, pad the edges
# 避免出现切图的大小比原图还大的情况
object_list = deal_xml(ann_path)
pad = 0
if sliceHeight > win_h:
pad = sliceHeight - win_h
if sliceWidth > win_w:
pad = max(pad, sliceWidth - win_w)
# pad the edge of the image with black pixels
if pad > 0:
border_color = (0, 0, 0)
image0 = cv2.copyMakeBorder(image0, pad, pad, pad, pad,
cv2.BORDER_CONSTANT, value=border_color)
win_size = sliceHeight * sliceWidth
t0 = time.time()
n_ims = 0
n_ims_nonull = 0
dx = int((1. - overlap) * sliceWidth) # 153
dy = int((1. - overlap) * sliceHeight)
for y0 in range(0, image0.shape[0], dy):
for x0 in range(0, image0.shape[1], dx):
n_ims += 1
#
#这一步确保了不会出现比要切的图像小的图,其实是通过调整最后的overlop来实现的
#举例:h=6000,w=8192.若使用640来切图,overlop:0.2*640=128,间隔就为512.所以小图的左上角坐标的纵坐标y0依次为:
#:0,512,1024,....,5120,接下来并非为5632,因为5632+640>6000,所以y0=6000-640
if y0 + sliceHeight > image0.shape[0]:
y = image0.shape[0] - sliceHeight
else:
y = y0
if x0 + sliceWidth > image0.shape[1]:
x = image0.shape[1] - sliceWidth
else:
x = x0
#
slice_xmax = x + sliceWidth
slice_ymax = y + sliceHeight
exiset_obj_list=exist_objs([x,y,slice_xmax,slice_ymax],object_list, sliceHeight, sliceWidth)
if exiset_obj_list!=[]: # 如果为空,说明切出来的这一张图不存在目标
# extract image
window_c = image0[y:y + sliceHeight, x:x + sliceWidth]
# get black and white image
window = cv2.cvtColor(window_c, cv2.COLOR_BGR2GRAY)
# find threshold that's not black
#
ret, thresh1 = cv2.threshold(window, 2, 255, cv2.THRESH_BINARY)
non_zero_counts = cv2.countNonZero(thresh1)
zero_counts = win_size - non_zero_counts
zero_frac = float(zero_counts) / win_size
# print "zero_frac", zero_fra
# skip if image is mostly empty
if zero_frac >= zero_frac_thresh:
if verbose:
print("Zero frac too high at:", zero_frac)
continue
# else save
else:
outpath = os.path.join(outdir, out_name + \
'|' + str(y) + '_' + str(x) + '_' + str(sliceHeight) + '_' + str(sliceWidth) + \
'_' + str(pad) + '_' + str(win_w) + '_' + str(win_h) + ext)
#
cnt += 1
# if verbose:
# print("outpath:", outpath)
cv2.imwrite(outpath, window_c)
n_ims_nonull += 1
#------制作新的xml------
make_slice_voc(outpath,exiset_obj_list,sliceHeight,sliceWidth)
if __name__ == "__main__":
not_use_multiprocessing = True
raw_images_dir = '。/train/c_slice/' # 这里就是原始的图片
raw_ann_dir = '。/train/box'
slice_voc_dir = '。/annotations4' # 切出来的标签也保存为voc格式
outdir = '。/JPEGImages4'
if not os.path.exists(slice_voc_dir):
os.makedirs(slice_voc_dir)
if not os.path.exists(outdir):
os.makedirs(outdir)
List_imgs = os.listdir(raw_images_dir)
if not_use_multiprocessing:
slice_im(List_imgs, outdir, raw_images_dir, raw_ann_dir, sliceHeight=768, sliceWidth=768)
else:
Len_imgs = len(List_imgs) # 数据集长度
num_cores = cpu_count() # cpu核心数
# print(num_cores, Len_imgs)
if num_cores >= 8: # 八核以上,将所有数据集分成八个子数据集
num_cores = 8
subset1 = List_imgs[:Len_imgs // 8]
subset2 = List_imgs[Len_imgs // 8: Len_imgs // 4]
subset3 = List_imgs[Len_imgs // 4: (Len_imgs * 3) // 8]
subset4 = List_imgs[(Len_imgs * 3) // 8: Len_imgs // 2]
subset5 = List_imgs[Len_imgs // 2: (Len_imgs * 5) // 8]
subset6 = List_imgs[(Len_imgs * 5) // 8: (Len_imgs * 6) // 8]
subset7 = List_imgs[(Len_imgs * 6) // 8: (Len_imgs * 7) // 8]
subset8 = List_imgs[(Len_imgs * 7) // 8:]
List_subsets = [subset1, subset2, subset3, subset4, subset5, subset6, subset7, subset8]
p = Pool(num_cores)
for i in range(num_cores):
p.apply_async(slice_im, args=(List_subsets[i], outdir, raw_images_dir, raw_ann_dir, i))
p.close()
p.join()
2.推理操作
测试时将原图以(640,640),步长512的窗口滑动切片,对切片进行预测,映射回原图时,
使用NMS对重叠区域的目标重复预测情况进行抑制。后面也可以再加WBF优化回归框。
总结
实现参考了GitHub,以目标中心点实现的切图思路,主要是增加了多线程处理和一些特殊情况是目标bbox没有映射到小图的bug,使用中如有问题欢迎指出。