insightface最新项目Partial FC论文理解
人脸识别 Partial FC: Training 10 Million Identities on a Single Machine论文翻译
文章目录
- 人脸识别 Partial FC: Training 10 Million Identities on a Single Machine论文翻译
- 前言
- Abstract
- Introduction
- Related Work
-
- Face Recognition
- Acceleration for Softmax
- Method
-
- Problem Formulation
- Approximate Strategy
- Experiment
-
- Datasets and Settings
- Effectiveness and Robustness
- Benchmark Results
- Training 100 millions identities
- Compare with other sampling-based methods.
- Conclusion
-
- References
- 总结
前言
【2020年10月13日】insightface最新人脸识别论文
Partial FC代码
Abstract
人脸识别长期以来一直是计算机视觉界一个活跃而重要的研究课题。以往的研究主要集中在人脸特征提取网络中的loss函数,其中基于softmax based loss函数的改进大大提高了人脸识别的性能。然而,人脸身份的急剧增加与GPU内存的不足之间的矛盾正逐渐变得不可调和。在本文中,我们进行了深入的分析,基于softmax based丢失函数的优化目标和大量身份的训练难点。我们发现softmax函数中的负类在人脸表征学习中的重要性并没有我们之前认为的那么高。实验表明,在训练时没有准确性损失与在主流基准上使用SOTA模型进行full-class训练相比,基于softmax based loss function的类只有10%的随机抽样。考虑到模型精度和训练效率,我们还实现了一个非常高效的分布式采样算法,该算法仅使用8个NVIDIA RTX2080Ti来完成数以千万计身份的分类任务
Introduction
人脸识别在现代生活中发挥着越来越重要的作用,广泛应用于住宅安全、人脸认证(Wang et al. 2015)、刑事侦查等领域。在人脸识别模型的学习过程中,将数据集中每个人的特征映射到所谓的嵌入空间中,在这个空间中,属于同一个人的特征更加紧凑,属于不同人的特征在欧几里得距离基更大。一个黄金法则是数据集提供的身份越多,模型可以学习的信息就越多,并且进一步获得的区分这些特征的能力就越强(Cao, Li, and Zhang 2018;(邓等2019)。许多公司都有数百万甚至数千万的面部识别训练集。例如,2015年谷歌的人脸数据集已经有2亿张图像,其中包含800万不同身份(Schroff, Kalenichenko和Philbin 2015)。
softmax loss及其变体(Wang et al. 2018b;Deng et al. 2019;Wang etc al,2018a;(Liu et al. 2017)被广泛用作人脸识别的目标。通常,它们在嵌入特征与线性变换矩阵相乘时进行全局特征到类的比较。尽管如此,当训练集中存在大量的identity时,最终的线性矩阵的存储和计算成本很容易超过当前GPU的能力,导致无法进行训练。
Zhang等人通过在每个小批量中动态选择 active classes,并仅使用类的子集(partial-classes)来近似完整类softmax,从而减少了计算量(Zhang等,2018)。Deng等人通过模型并行的方式缓解了每个GPU的内存压力,并通过很少的通信计算出全类softmax (Deng et al. 2019)。选择active classes的问题是,当标识数量大到一定程度,比如1000万个时,通过特征检索活动类的时间消耗是不可忽视的。在模型并行方面,分布式gpu节省内存的优点存在瓶颈。当身份数增加时,GPU数量的增加确实可以缓解权值矩阵W的存储问题,而最终日志的存储将给GPU内存带来新的负担。
 图1:(a)通过使用hash forest,查找 active classes 的复杂度从O(N)降低到O(logN)。(b)随机选择正类和负类,采样复杂度为O(1)。
图1:(a)通过使用hash forest,查找 active classes 的复杂度从O(N)降低到O(logN)。(b)随机选择正类和负类,采样复杂度为O(1)。
在本文中,我们提出了一种有效的人脸识别训练策略,可以完成超大规模的人脸识别训练。具体地说,我们首先将softmax线性变换矩阵的非重叠子集按顺序均匀地存储在所有gpu上。然后,每个GPU负责计算存储在其自身和输入特性上的采样子矩阵的点积和。之后,每个GPU从其他GPU收集本地和来近似整个类的softmax函数。通过只通信采样的局部和,我们用少量的通信来逼近full-class softmax。该方法大大降低了每个GPU的通信、计算和存储成本。此外,我们证明了我们的策略的有效性,可以将训练效率提高到以前的几倍。通过使用8 NVIDIA RTX2080Ti,可以训练1000万个身份的数据集,64个gpu可以训练1亿个身份。为了验证算法在学术界的有效性和鲁棒性,我们对算法进行了清理和整合现有公共人脸识别数据集获得的最大公共可用人脸识别训练集Glint360K,将会发布。从多个数据集的实验结果表明,我们的方法只使用10%的类来计算softmax,可以达到很高的准确性与SOTA作品。
综上所述,我们的贡献主要如下:
1)我们提出了一个softmax近似算法,它可以在只使用10%类中心的情况下保持精度。
2)提出了一种高效的分布式训练策略,可以轻松地训练具有大量类的分类任务。
3)清理、合并并发布最大、最干净的人脸识别数据集Glint360K。使用我们提出的训练策略,在Glint360K上训练的baseline模型可以轻松达到SOTA水平。
Related Work
Face Recognition
随着深度学习的发展,深度神经网络在人脸识别领域发挥着越来越重要的作用。一般的流程是深度神经网络为每个输入图像提取一个特征。在学习的过程中,类内部的距离逐渐缩小,类之间的距离也逐渐扩大。目前,最成功的分类器是使用softmax分类器或其变体来区分不同的身份(Wang et al.2018b;邓等2019;(Liu等,2017)。人脸识别领域现在需要大量的身份来训练一个模型,例如。, 10数百万。对于基于softmax loss的方法,线性变换矩阵W会随着类数的增加而线性增加。当身份数量较大时,一个GPU甚至无法加载这样的权值矩阵。
Acceleration for Softmax
为了加速人脸识别中的大规模softmax,已经有了一些方法。HF-softmax (Goodman 2001)为每个小批动态地选择active class中心的子集。通过在嵌入空间中构造一个随机hash forest来选择active class中心以及根据特征检索最接近的类中心。但该方法的所有类中心都存储在RAM中,不能忽略特征检索计算的时间代价。Softmax分离(He et al. 2020)将Softmax损失分为类内目标和类间目标,减少了类间目标冗余度的计算,但不能扩展到其他基于Softmax的损失
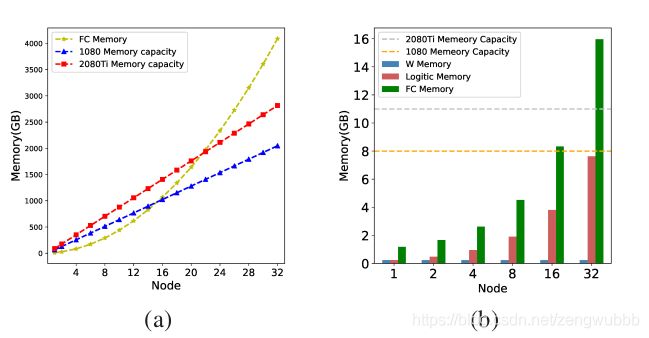 图2:(a)随着类和GPU数量的增加,总内存使用量随着GPU数量的增加而增加。(b) W内存成本不变,但logits会线性增加,在16台服务器8个GPU的情况下,GPU总内存的百分比高达90% 。
图2:(a)随着类和GPU数量的增加,总内存使用量随着GPU数量的增加而增加。(b) W内存成本不变,但logits会线性增加,在16台服务器8个GPU的情况下,GPU总内存的百分比高达90% 。
这些方法在使用多gpu训练时都是基于数据并行的。即使只使用了部分类中心来近似softmax loss函数,在应用梯度平均同步SGD时,gpu间通信仍然代价高昂(Li et al. 2014)。此外,可选择类中心的数量受到单个GPU内存容量的限制。ArcFace (Deng et al. 2019)提出了模型并行,将softmax权重矩阵分离到不同的gpu,然后以极低的通信代价计算全类softmax损失。他们成功地在一台机器上用8个gpu训练了100万个身份。但是,这个方法仍然有内存限制。当身份数不断增加时,GPU内存消耗最终会超过容量限制,尽管GPU的数量以同样的比例增加。我们将在后面的章节中详细分析模型并行的GPU内存使用情况。
Method
在本节中,我们首先详细介绍现有的并行模型,分析其设备间通信开销、存储成本和内存限制。然后介绍了我们的性能无损逼近方法,并解释了该方法的工作原理。最后,我们提出了我们的分布逼近方法和实现细节。
Problem Formulation

图3:(a) pcc值的曲线。实线表示以0.5和0.1的速率获取整个正类中心和抽样部分负类中心(PPRN)。虚线表示以0.1和0.5的速率随机抽样所有班级中心。(b)局部负类中心采样率分别为0.1、0.5和1.0 (PPRN)时CA pcc曲线的值。
Model parallel 在没有使用并行模型的情况下,训练具有大量身份的模型是很痛苦的,这受制于单一显卡的内存容量。softmax权重矩阵W∈R d×C存在瓶颈,其中d为嵌入特征维数,C为类数。打破瓶颈的一种自然而直接的方法是将W划分为k个子矩阵W,大小为d×Ck,并将第i个子矩阵放在第i个GPU上。因此,为了计算最终的softmax输出,每个GPU必须从所有其他GPU收集功能,因为权重在不同的GPU之间被分割。softmax函数的定义是

分子的计算可以由每个GPU独立完成,作为输入特征X,相应的权值子矩阵w i被存储在本地。
为了计算softmax函数的分母,所有的e w j X的总和具体来说,信息从所有其他gpu必须被收集。自然,我们可以先计算每个GPU的局部和,然后通过通信计算全局和。与单纯的数据并行相比,该实现的通信成本可以忽略不计。不同之处在于要传递的数据发生了变化。数据并行需要传输整个W的梯度来更新所有权值,而模型并行只传递局部和,其代价可以忽略。具体来说,通信开销的大小等于批处理大小乘以4个字节(Float32)。我们使用集合通信原语和矩阵运算来描述模型在第i个GPU上并行的计算过程,包括前向传播和后向传播,如算法1所示。这种方法可以大大减少工作人员之间的交流。因为尺寸的W x i,∇x d∗C, N d和d N∗∗∗k分别和大规模分类任务,我们通常假设C≫N∗(k + 1),其中N代表每个GPU mini-batch大小。

Memory Limits Of Model Parallel 并行模型可以完全解决w的存储和通信问题,因为无论C多大,我们都可以轻松地增加更多的gpu。使每个GPU存储子矩阵w的内存大小保持不变,即:

然而,w并不是唯一存储在GPU内存中的。预计日志的存储会受到总批大小的增加的影响。我们将每个GPU上的logits存储表示为logits = Xw,那么每个GPU上存储logits的内存消耗就等于

其中N为每个GPU上的mini-batch大小,k为GPU的数量。假设每个GPU的批处理大小是恒定的,当C增大时,为了保持Ck不变,我们必须同时增大k。因此,logits占用的GPU内存将继续增加,因为特征的批处理大小随着k的增加而同步增加,假设只考虑分类层,由于我们在训练时使用动量SGD优化算法,每个参数将占用12个字节。如果使用CosFace (Wang et al. 2018b)或ArcFace (Deng et al.2019), logits中的每个元素占用8个字节。因此,分类层所占用的GPU内存总量计算为

如图2所示,假设每个GPU上的mini-batch大小为64,嵌入特征维数为512,则100万个分类任务需要8个GPU,训练1000万个分类任务至少需要80个GPU。我们发现日志占用的内存是w的10倍,这使得存储日志成为模型并行的新瓶颈。结果表明,单纯增加gpu是无法解决大量身份的训练任务的。

图4:我们方法的分布式实现结构。k表示gpu的数量。Allgather:从所有gpu收集数据,并将合并后的数据分发给所有gpu。Allreduce:对数据进行汇总,并将结果分发给所有gpu。
Approximate Strategy
Roles of positive and negative classes 使用最广泛的分类损失函数softmax损失可以描述为

其中x i∈R d为第i个样本的深度特征,属于第y i-th类。w j∈R d,表示权值w∈R d×C的第j列。批号为N,类号为C。
fj通常表示为权向量w j和偏置bj的全连通层的激活。为了简单起见,我们将偏差bj固定为0,结果fj为

其中,l5j为权值w j与特征xi之间的夹角。以下(Wang et al. 2018b;Liu等2017;Deng等2019;王et al . 2018年),我们解决个人体重千瓦j k, l 2正常化,我们也修复功能kx我k, l 2正常化并重新调节。正常化一步特性和重量使得预测只取决于之间的角度特性和体重。
自然地,线性变换矩阵的每一列都被视为一个类中心,而矩阵的第j列对应于类j的类中心。我们将wyi表示为xi的正类中心,其余为负类中心。
通过对softmax方程的分析,我们得出以下假设:如果我们想选择类中心的子集来近似softmax,则必须选择正的类中心,而负的类中心只需要从所有的子集中选择。通过这样做,可以维护模型的性能。
我们用两个实验来证明这个假设。在每次实验中,只采样一定百分比的类中心来计算每次迭代中近似的softmax损失。第一个实验主要选取当前批次中与输入特征相对应的所有正类,然后对负类中心进行随机采样。在下一节中,我们将这种抽样策略简称为正随机负(PPRN)。第二种就是从所有的类中心进行随机选择。两个实验的采样率都设置为0.1和0.5。在训练过程中,我们将xi和wyi的平均余弦距离定义为CA pcc,即:

实验结果如图3所示。在图3 (a)中,我们可以发现,在采样率为0.1时,完全随机采样导致的模型性能低于PPRN。因为正中心和特征之间的平均余弦角是我们的优化目标。在训练没有采样正中心时,x的梯度我只知道样本远离负中心的方向,而没有类内聚类的目标。但是,随着抽样率的增加,这种性能下降会逐渐下降,因为抽样为正类的概率也在增加。
由图3 (b)可以看出,在采样率分别为0.1、0.5和1.0的情况下,PPRN训练的模型表现相似。为了解释这种现象,关键之一是预测没有抽样概率P我与PPRN采样策略和预测的概率P̂我在某些情况下非常相似。即。


表1:LFW、CFP-FP和AgeDB-30小模型的验证性能(%)

图5:PPRN (ours)和所有类中心在不同val数据集上的随机抽样验证结果。在训练数据集CASIA时,我们采用ResNet50作为骨干和CosFace loss。(a) LFW的验证结果。(b)AgeDB-30的验证结果。
 式中,S为采样类的集合,r为采样率。
式中,S为采样类的集合,r为采样率。
随着采样策略PPRN不断优化正类中心,正类P gt的概率P和采样类P j的和的概率不断增加。这使得任何负类的概率之间的差距和P P̂我越来越小。也就是说在训练过程的后期,负类中心的优化方向和幅度与采样率的关系不大。因此,这也是0.1、0.5和1.0的采样率可以得到非常相似结果的原因。
Distributed Approximation如前一节所述,只有类中心的一个子集可以实现可比较的性能。为了训练具有大量恒等式的训练集,我们提出了一种分布逼近方法。抽样子集类中心的过程很简单:1)首先选取正类中心;2)随机抽取负的类中心。在模型并行的情况下,为了平衡每个GPU的计算和存储,每个GPU上采样的类中心数应该相等,因此采样过程改变如下:
1. 在这个GPU是获得正类中心
W将按顺序平均分成不同的gpu,如W = [W 1, W 2,…, w k], k是gpu的数量。当我们知道样本xi的标签yi,它的正类中心是yi的W线性矩阵的第i列。因此,通过对当前批处理中的特征进行标记y,可以很容易地获得当前GPU上的正类中心。
2. 计算负的类中心数量
根据之前的信息,数量的类中心存储在这个GPU是我| | w,积极的类中心的数量是我p | | w,然后负类中心的数量需要随机抽样在GPU是s i =(我| | w−我p | | w)∗r, r是PPRN的采样率
3.随机抽样负类
通过在wi和wi p之间的差集中随机采样i的负类中心,我们得到了负类中心wi n = random(w i - wi p, s i)
最后,我们得到所有的类中心都参与softmax计算,W s =[W p, W n],其中W p =[W 1 p,…[a] . [b] . [c] . [d] .], wk n]。实际上,该方法是一种近似的方法来获得每个GPU的负载均衡。

Experiment
Datasets and Settings
Training Dataset 我们的训练数据集包括CASIA(Liu et al. 2015)和MS1MV2 (Deng et al. 2019)。此外,我们清理了Celeb-500k (Cao, Li, Zhang 2018),并添加更多的名人合并到一个新的训练集,我们称之为Glint360K。发布的数据集包含360K个人的1800万张图像,是目前学术界最大、最干净的训练集。
Testing Dataset 我们探索高效的人脸验证数据集(例如,LFW (Huang et al. 2008)、CFP-FP(Sengupta et al. 2016)、AgeDB-30 (Moschoglou et al.2017)),以检查不同设置下的改进。此外,我们报告了我们的方法在大姿态和大年龄数据集(例如,CPLFW(郑和邓2018)和CFLFW(郑,邓和胡2017))上的性能。此外,我们还在大规模的图像数据集(如图像数据集)上进行了广泛的测试。、MegaFace (Kemelmacher-Shlizerman等人2016)、IJB-B (Whitelam等人2017)、IJB-C (Maze等人2018))和InsightFace Recognition Test (IFRT)
Training Settings 我们使用ResNet50和ResNet100(Deng et al. 2019;(He et al. 2016)作为骨干网络,并使用两个边缘基损失函数(即CosFace和ArcFace)。我们将feature scale s设为64,CosFace的cos margin m设为0.4,ArcFace的arccos margin m设为0.5。我们在8个NVIDIA RTX2080Ti上使用512的小批处理。学习率从0.1开始。CASIA在20K时学习率除以10,28K次迭代,32K次完成训练过程。对于MS1MV2,我们将学习率分为100K次,160K次迭代,最后以180K次迭代结束。对于Glint360K,在200k、400k、500k、550k迭代时学习率除以10,在600K迭代时完成。
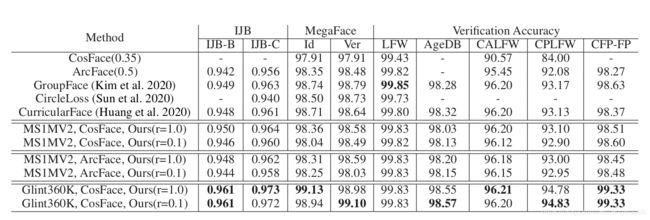
表2:LFW、AgeDB-30、CALFW、CPLFW、CFP-FP数据集1:1的验证精度。在IJB-B和IJB-C数据集上报告TAR@FAR=1e-4。以FaceScrub为探测集,对MegaFace Challenge1的识别与验证评估。“Id”为1M干扰物下的第1级人脸识别精度,“Ver”为人脸验证TAR@FPR=1e-6。r表示抽样率。

表3:在InsightFace Recognition Test (IFRT)中1:1的验证精度,TAR@FAR=1e-6是对所有1:1 protocal进行测量的。r表示抽样率。
Effectiveness and Robustness
Effects on positive class centers我们比较不同抽样率下各班中心的PPRN和随机抽样的结果,如图5所示。实验表明,当抽样率较小时,所有类中心的随机抽样的准确率会急剧下降,而我们的方法将保持不变。
Effects on small-scaled trainset 如表1所示。在较小的训练集上,采样率为10%的PPRN对准确率几乎没有影响,这说明我们的方法即使在较小的数据集上也是有效的。
Robustness on the number of identities 如表2所示,我们使用两个大的训练集MS1MV2和Glint360K来验证训练集中的恒等数对我们的采样方法的影响。对于IJB-B和IJBC,在使用MS1MV2时,ijb和IJB-C中10%抽样与full softmax的精度差分别为0.4%和0.4%,在使用Glint360K时,10%抽样对IJB-B无差异,对IJB-C只有0.1%的差异。MegaFace在使用MS1MV2时,10%的采样率与full softmax的识别和验证精度差分别为0.24%和0.09%,在使用Glint360K时,10%的采样率与full softmax的性能相当,在验证评估中,10%甚至优于full softmax,比full softmax多出+0.12%。该结论表明,我们的方法同样适用于更大规模的训练集,当识别器的数量增加大于或等于300K时,10%采样的性能与全softmax相当。
Benchmark Results
Results on IJB-B and IJB-C 我们遵循ArcFace的测试协议,利用人脸检测分数和特征规范对模板中的人脸重新赋值。通过在MS1MV2和Glint360K两个数据集上的实验,证明采样率为10%的PPRN进行softmax计算时性能损失很小。如表2所示,当我们对大样本训练数据(Glint360K)采用采样率为10%的PPRN时,将IJB-B和IJB-C的TAR (@FAR=1e-4)进一步提高到0.961和0.972。
Results on MegaFace 我们采用MegaFace的改进版本(Deng et al. 2019)进行公平评估,在大协议下使用MS1MV2和Glint360K。如表2所示。最后,我们利用采样率为10%的大规模Glint360K数据集和PPRN,在MegaFace数据集上实现了99.13%的最先进的验证精度。
Results on IFRT IFRT是一个全球性的公平的人脸识别算法基准,这个测试数据集包含242143个身份和1624305张图像。IFRT评估算法在世界范围内包含不同性别、年龄和种族的网络图片上的性能。在表3中,我们比较了我们的方法在Glint360k上训练的性能。与MS1MV3相比,Glint360k数据集明显提高了性能。此外,采样率为10%的PPRN与 full softmax的性能仍具有可比性。

表4:大规模分类训练比较。占用的内存越少,吞吐量越大,效果越好。OOM是指GPU内存溢出,无法对模型进行训练。当应用并行模型时,在RAM中存储权重矩阵是没有用的,因为在计算softmax损失时,所有的类中心仍然需要加载回gpu中。
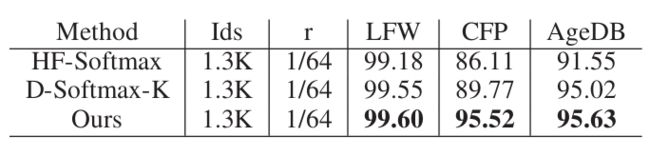
表5:我们的方法与现有的基于采样的方法在LFW、CFP和AgeDB上的人脸验证精度比较。r表示抽样率。
Training 100 millions identities
我们通过设置不同数量的身份和gpu来测试我们的方法和模型并行的训练速度。在所有的实验中,我们都消除了IO的影响。我们比较了四种设置,如表4所示.
1. 1 Million identities on 8 GPUs GPU可以存储一百万个类中心,我们在GPU上存储W。由于logits带来的计算减少,我们的速度比模型并行快30%。
2. 10 Million identities on 8 GPUs当身份数量达到1000万个时,模型并行方法无法工作。我们仍然可以继续训练,我们方法的训练速度是每秒900张图像。
3. 10 Million identities on 64 GPUs在使用模型并行时,64个GPU会带来较大的全局批处理容量,这会增加日志的GPU内存。2048是模型并行的最大批大小。与模型并行相比,我们的方法在每个GPU上的内存消耗从9.6G减少到6.7G,训练速度为每秒12600张图像,比模型并行快3倍。
4. 100 Million identities on 64 GPUs拥有64个gpu,训练1000万个身份已经达到了模型并行的极限,但我们的可以轻松扩展到2000万个、3000万个,甚至1亿个身份。在训练2000万、3000万和1亿个身份时,我们方法的训练速度分别为每秒10790、8600和2000张图像。我们是第一个提出如何训练1亿个类的。

表6:我们的方法与现有的基于采样的方法在训练速度上的比较,我们计算的总平均时间为整个模型向前向后传递一次的平均时间。
Compare with other sampling-based methods.
我们将我们的方法与目前一些基于采样的方法进行了比较。方法为(Zhang et al. 2018)中提出的HF-Softmax pro和(He et al. 2020)中提出的D-Softmax。我们采用了与(Zhang et al. 2018;;(He et al. 2020)进行公平比较。在相同的1/64采样率下,我们的方法在准确率和速度上都优于所有的方法,如表5和表6所示。
Conclusion
在本文中,我们首先系统地分析了模型并行的优缺点。在此基础上,针对并行模型不能训练大量类模型的问题,引入了PPRN采样策略。一方面,通过在每次迭代中只训练所有类的子集,训练速度可以非常快。更重要的是,通过对部分类方法的训练,GPU内存不再是模型并行的瓶颈,可以将海量的身份从不可能变为可能。接下来,我们做了广泛的实验来验证PPRN在不同模型、损失函数、训练集和测试集之间的有效性和鲁棒性。最后,为了加快该领域的发展,我们发布了迄今为止最大、最干净的人脸识别数据集Glint360K。在Glint360K上进行训练时,我们仅用10%的类来进行训练,就可以实现SOTA性能。
References
Read the Paper and https://github.com/deepinsight/insightface/tree/master/recognition/partial_fc
总结
本人也是刚看完论文,接下来好好研究源码,训练一个更加优秀的模型…