
原文链接:https://blog.51cto.com/14815984/2511989
背景
通常我们在通过SQL慢查询日志或其它三方工具分析出查询性能较差的SQL语句后,经常需要定位原因。那么对于MYSQL我们常用其内置的执行计划(EXPLAIN)命令对慢的语句进行模拟执行查询过程的分析,从而发现我们语句的性能瓶颈点,再进行有针对性地优化工作。
执行计划
一、为什么要分析执行计划细节 ,我们能得到哪些方面信息 ?
理解语句执行的任务拆分和任务的执行顺序;
分析执行计划拆分的任务内部的划分和含义;
分析单步执行任务的执行效果的理想程度;
了解语句的执行计划建议可以使用哪些索引;
查看执行计划究竟内部用上了哪些目前的索引;
追踪执行过程中,对表及字段的引用逻辑;
了解每个子任务过滤的表记录数,从而调整表的连接和组织方式;
二、语法
EXPLAIN +SQL语句 , 如:EXPLAIN select * from table;
详解分析结果
一、任务id理解
场景1. 执行任务id一样,表明查询优化器执行任务的顺序是至上而下顺序执行。
如下图查询语句,执行将从表t1开始,依次执行t3和t2的任务。
EXPLAIN SELECT t2.* FROM t1,t2,t3 WHERE t1.id=t2.id AND t1.id=t3.id AND t1.other_column='';

场景2. 执行任务id不同, 查询优化器执行规则为:id值最大的任务优先被执行,按由大到小的顺序依次执行拆分的任务项。
如下图语句中执行过程:执行将从任务3开始,依次执行任务2和任务1;
EXPLAIN SELECT t2.* FROM t2 WHERE id=(
SELECT id FROM t1 WHERE id=(SELECT t3.id FROM t3 WHERE t3.other_column='')
);

场景3. 执行任务id相同与不同混合场景,查询优化器优先执行任务id最大的;任务id一样的部分单独分组,至上而下顺序执行。
如下图语句中执行过程: 任务将被优先执行,然后再从上到下依次执行id=1d的两个任务;
EXPLAIN
SELECT t2.* FROM( SELECT t3.idFROM t3 WHERE t3.other_column='' ) s1,t2 WHERE s1.id=t2.id ;

二、任务查询类型 - select_type
从语句整体上,划分为多种不同的查询类型场景。

1.SIMPLE类型,如:EXPLAIN SELECT * FROM t_order;
- PRIMARY和SUBQUERY类型
如:EXPLAIN SELECT *,(SELECT id FROM t_order_detail WHERE order_id=2) FROM t_order t1;
- DERIVDE 衍生类型
如:EXPLAIN SELECT t1.* FROM t1,( SELECT t2.* FROM t2 WHERE t2.id =1) s2 WHERE t1.id=s2.id;

截图中的
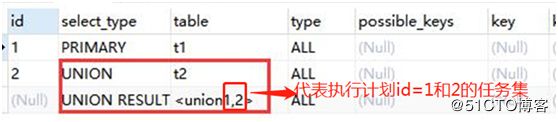
4. UNION / UNION RESULT类型
如以下语句: EXPLAIN SELECT * FROM t1 UNION SELECT * FROM t2;
三、建议可以使用哪些索引 - possible_keys
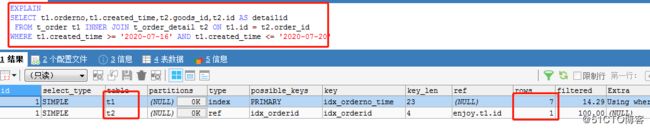
EXPLAIN
SELECT t1.orderno,t1.created_time,t2.goods_id,t2.id AS detailid
FROM t_order t1 INNER JOIN t_order_detail t2 ON t1.id = t2.order_id
WHERE t1.created_time >= '2020-07-18' AND t1.created_time <= '2020-07-20' ;
如上截图待优化语句中,红框中的索引,就是查询优化器建议使用的索引进行对应的优化
四、实际使用到的索引 - key
如下图中,就是查询优化器实际用到的索引(可能是多个)
CREATE INDEX idx_col1_col2 ON t1 (col1, col2);
EXPLAIN SELECT col1,col2 FROM t1 ;

五、分析是否充分用到了索引 - key_len
影响key_len值的因素:字符集设置、索引字段的长度(或字节数)、索引字段是否设置允许为null。
字符集和 char / varchar类型字节对应关系

场景一、对于char类型
单个字段key_len长度计算公式为 = 字符集占用最大字节空间 * 字段长度 + 是/否允许为null (是=1, 否=0) ;


所以截图1中的key_len=30的计算=3*10+0=30;
场景二、对于varchar类型
单个字段key_len长度计算公式为 = 字符集占用最大字节空间 * 字段长度+(预留长度) + 是/否允许为null (是=1, 否=0) ;
公式中的预留长度值: mysql官网的介绍是: 长度在1 ~ 255之间,预留长度=1; 长度在256 ~ 16384之间,预留长度=2;


所以截图2中的key_len=32的计算=3*10+2+0=32;
场景三、数字类型 (包括:int系列, 单精度、双精度、Decimal等)
单个字段key_len长度计算公式为 = 字段类型占字节空间 + 是/否允许为null (是=1, 否=0) ;


截图3中的key_len=4的计算=4+0=4;

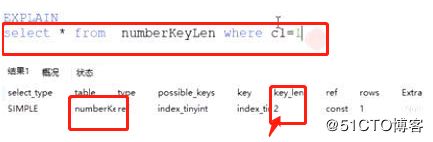
截图4中的key_len=2的计算=1+1=2;
场景四、日期/日期时间/时间戳/时间等类型, 计算规则同场景三(这里不再赘述)。
其它须知原则
充分用到索引的key_len长度肯定比未充分用到的要长,但字段加索引的原则是优先选择长度较短的数据类型上加索引,查询更高效;
复合索引key_len原则:复合索引有最左前缀的特性,如果复合索引能全部使用上,则是复合key_len为各索引字段的key_len长度之和,这也可以用来判定复合索引是否部分使用,还是全部使用;
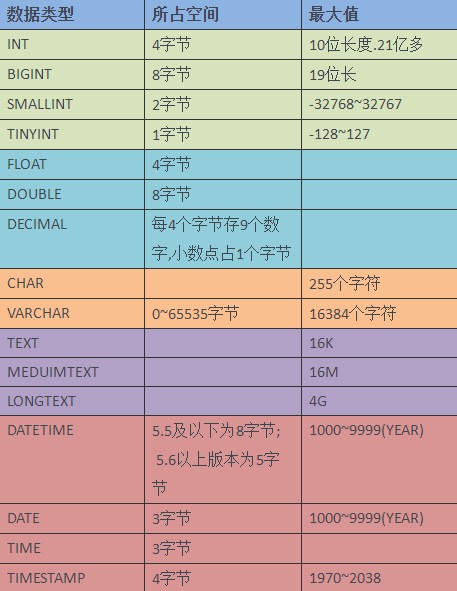
附数据类型占字节空间对应表
六、任务访问类型 - type
访问类型值,从最好到最坏依次排序级别是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
级别值详解
system: 优化器拆分的计划id对应表中只有一条记录
const: 通过索引一次就找到了目标数据
eq_ref: 唯一索引扫描,表中唯一记录与之匹配,常用在主键或唯一索引
如执行包含主键id的索引查询type即为eq_ref级:EXPLAIN SELECT * from t1,t2 where t1.id=t2.id
ref: 非唯一索引扫描
如执行非唯一索引查询type即为ref级: EXPLAIN select count(DISTINCTcol1) from t1 where col1='ac'

range: 检索给定范围的行,使用一个索引来选择行; (常用在bewteen and 、IN、<>);
index : 计划执行的是全表扫描( 通过索引扫描全表, select出的字段全是索引列) ;
ALL: 同上全表扫描,但扫描的是全表数据;
需掌握级别:
system > const > eq_ref > ref
range > index > ALL
一般查询需要保证达到range 级别,至少为ref
七、对表和列的引用 - ref

八、引用表多少行被优化器查询到 - row
九、十分重要的额外信息 - extra
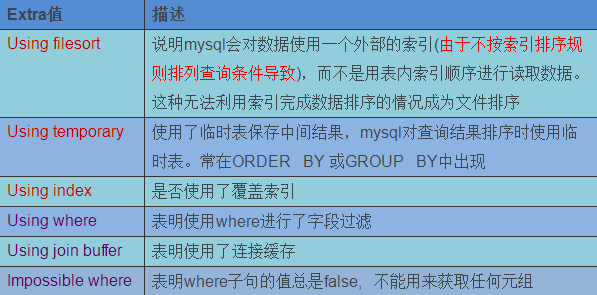
1. 产生filesort文件排序的原因
创建复合索引时的字段排序顺序是key(a,b,c); 但是采用where或order by 时,却只按照c或其它字段排序,这样查询优化器就无法采用索引来排序,需重新建立排序规则,即产生了这种情况;
如下截图所示:



解决办法:order by c2,c3 ;

2. temporary表产生的原因
在order by或group by排序 中不采用索引字段排序顺序,导致产生中间临时表。
解决办法:group by c1,c2 ;

3.索引覆盖举例


4. join buffer理解:不循环数据逐一和另一张表匹配,而是缓存整个小表数据,整体和另一张表进行匹配方式,提升查询效率;
5. impossible_where: 无法查询到任何数据

总结
以上就是MYSQL执行计划模拟执行结果的所有细节分析。
写在最后
欢迎大家关注我的公众号【风平浪静如码】,海量Java相关文章,学习资料都会在里面更新,整理的资料也会放在里面。
觉得写的还不错的就点个赞,加个关注呗!点关注,不迷路,持续更新!!!