第01章 Pandas基础
第02章 DataFrame基础运算
第03章 创建和持久化DataFrame
第04章 开始数据分析
第05章 探索性数据分析
第06章 选取数据子集
第07章 过滤行
第08章 索引对齐
5.1 概括性统计
概括性统计包括平均值、分位值、标准差。.describe方法能计算DataFrame中数值列的统计信息:
>>> import pandas as pd
>>> import numpy as np
>>> fueleco = pd.read_csv("data/vehicles.csv.zip")
>>> fueleco
barrels08 barrelsA08 ... phevHwy phevComb
0 15.695714 0.0 ... 0 0
1 29.964545 0.0 ... 0 0
2 12.207778 0.0 ... 0 0
3 29.964545 0.0 ... 0 0
4 17.347895 0.0 ... 0 0
... ... ... ... ... ...
39096 14.982273 0.0 ... 0 0
39097 14.330870 0.0 ... 0 0
39098 15.695714 0.0 ... 0 0
39099 15.695714 0.0 ... 0 0
39100 18.311667 0.0 ... 0 0
调用独立的方法计算平均值、标准差、分位值:
>>> fueleco.mean()
barrels08 17.442712
barrelsA08 0.219276
charge120 0.000000
charge240 0.029630
city08 18.077799
...
youSaveSpend -3459.572645
charge240b 0.005869
phevCity 0.094703
phevHwy 0.094269
phevComb 0.094141
Length: 60, dtype: float64
>>> fueleco.std()
barrels08 4.580230
barrelsA08 1.143837
charge120 0.000000
charge240 0.487408
city08 6.970672
...
youSaveSpend 3010.284617
charge240b 0.165399
phevCity 2.279478
phevHwy 2.191115
phevComb 2.226500
Length: 60, dtype: float64
>>> fueleco.quantile(
... [0, 0.25, 0.5, 0.75, 1]
... )
barrels08 barrelsA08 ... phevHwy phevComb
0.00 0.060000 0.000000 ... 0.0 0.0
0.25 14.330870 0.000000 ... 0.0 0.0
0.50 17.347895 0.000000 ... 0.0 0.0
0.75 20.115000 0.000000 ... 0.0 0.0
1.00 47.087143 18.311667 ... 81.0 88.0
调用.describe方法:
>>> fueleco.describe()
barrels08 barrelsA08 ... phevHwy phevComb
count 39101.00... 39101.00... ... 39101.00... 39101.00...
mean 17.442712 0.219276 ... 0.094269 0.094141
std 4.580230 1.143837 ... 2.191115 2.226500
min 0.060000 0.000000 ... 0.000000 0.000000
25% 14.330870 0.000000 ... 0.000000 0.000000
50% 17.347895 0.000000 ... 0.000000 0.000000
75% 20.115000 0.000000 ... 0.000000 0.000000
max 47.087143 18.311667 ... 81.000000 88.000000
查看object列的统计信息:
>>> fueleco.describe(include=object)
drive eng_dscr ... modifiedOn startStop
count 37912 23431 ... 39101 7405
unique 7 545 ... 68 2
top Front-Wh... (FFS) ... Tue Jan ... N
freq 13653 8827 ... 29438 5176
更多
对.describe的结果进行转置,可以显示更多信息:
>>> fueleco.describe().T
count mean ... 75% max
barrels08 39101.0 17.442712 ... 20.115 47.087143
barrelsA08 39101.0 0.219276 ... 0.000 18.311667
charge120 39101.0 0.000000 ... 0.000 0.000000
charge240 39101.0 0.029630 ... 0.000 12.000000
city08 39101.0 18.077799 ... 20.000 150.000000
... ... ... ... ... ...
youSaveSpend 39101.0 -3459.572645 ... -1500.000 5250.000000
charge240b 39101.0 0.005869 ... 0.000 7.000000
phevCity 39101.0 0.094703 ... 0.000 97.000000
phevHwy 39101.0 0.094269 ... 0.000 81.000000
phevComb 39101.0 0.094141 ... 0.000 88.000000
5.2 列的类型
查看.dtypes属性:
>>> fueleco.dtypes
barrels08 float64
barrelsA08 float64
charge120 float64
charge240 float64
city08 int64
...
modifiedOn object
startStop object
phevCity int64
phevHwy int64
phevComb int64
Length: 83, dtype: object
每种数据类型的数量:
>>> fueleco.dtypes.value_counts()
float64 32
int64 27
object 23
bool 1
dtype: int64
更多
可以转换列的数据类型以节省内存:
>>> fueleco.select_dtypes("int64").describe().T
count mean ... 75% max
city08 39101.0 18.077799 ... 20.0 150.0
cityA08 39101.0 0.569883 ... 0.0 145.0
co2 39101.0 72.538989 ... -1.0 847.0
co2A 39101.0 5.543950 ... -1.0 713.0
comb08 39101.0 20.323828 ... 23.0 136.0
... ... ... ... ... ...
year 39101.0 2000.635406 ... 2010.0 2018.0
youSaveSpend 39101.0 -3459.572645 ... -1500.0 5250.0
phevCity 39101.0 0.094703 ... 0.0 97.0
phevHwy 39101.0 0.094269 ... 0.0 81.0
phevComb 39101.0 0.094141 ... 0.0 88.0
city08和comb08两列的值都没超过150。iinfo函数可以查看数据类型的范围。可以将类型改为int16。内存降为原来的25%:
>>> np.iinfo(np.int8)
iinfo(min=-128, max=127, dtype=int8)
>>> np.iinfo(np.int16)
iinfo(min=-32768, max=32767, dtype=int16)
>>> fueleco[["city08", "comb08"]].info(memory_usage="deep")
RangeIndex: 39101 entries, 0 to 39100
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 city08 39101 non-null int64
1 comb08 39101 non-null int64
dtypes: int64(2)
memory usage: 611.1 KB
>>> (
... fueleco[["city08", "comb08"]]
... .assign(
... city08=fueleco.city08.astype(np.int16),
... comb08=fueleco.comb08.astype(np.int16),
... )
... .info(memory_usage="deep")
... )
RangeIndex: 39101 entries, 0 to 39100
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 city08 39101 non-null int16
1 comb08 39101 non-null int16
dtypes: int16(2)
memory usage: 152.9 KB
finfo函数可以查看浮点数的范围。
基数低的话,category类型更节省内存。传入memory_usage='deep',查看object和category两种类型的内存占用:
>>> fueleco.make.nunique()
134
>>> fueleco.model.nunique()
3816
>>> fueleco[["make"]].info(memory_usage="deep")
RangeIndex: 39101 entries, 0 to 39100
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 make 39101 non-null object
dtypes: object(1)
memory usage: 2.4 MB
>>> (
... fueleco[["make"]]
... .assign(make=fueleco.make.astype("category"))
... .info(memory_usage="deep")
... )
RangeIndex: 39101 entries, 0 to 39100
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 make 39101 non-null category
dtypes: category(1)
memory usage: 90.4 KB
>>> fueleco[["model"]].info(memory_usage="deep")
RangeIndex: 39101 entries, 0 to 39100
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 model 39101 non-null object
dtypes: object(1)
memory usage: 2.5 MB
>>> (
... fueleco[["model"]]
... .assign(model=fueleco.model.astype("category"))
... .info(memory_usage="deep")
... )
RangeIndex: 39101 entries, 0 to 39100
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 model 39101 non-null category
dtypes: category(1)
memory usage: 496.7 KB
5.3 类型数据
数据可以分为日期、连续型数据、类型数据。
选取数据类型为object的列:
>>> fueleco.select_dtypes(object).columns
Index(['drive', 'eng_dscr', 'fuelType', 'fuelType1', 'make', 'model',
'mpgData', 'trany', 'VClass', 'guzzler', 'trans_dscr', 'tCharger',
'sCharger', 'atvType', 'fuelType2', 'rangeA', 'evMotor', 'mfrCode',
'c240Dscr', 'c240bDscr', 'createdOn', 'modifiedOn', 'startStop'],
dtype='object')
使用.nunique方法确定基数:
>>> fueleco.drive.nunique()
7
使用.sample方法查看一些数据:
>>> fueleco.drive.sample(5, random_state=42)
4217 4-Wheel ...
1736 4-Wheel ...
36029 Rear-Whe...
37631 Front-Wh...
1668 Rear-Whe...
Name: drive, dtype: object
确认缺失值的数量和百分比:
>>> fueleco.drive.isna().sum()
1189
>>> fueleco.drive.isna().mean() * 100
3.0408429451932175
使用.value_counts查看每种数据的个数:
>>> fueleco.drive.value_counts()
Front-Wheel Drive 13653
Rear-Wheel Drive 13284
4-Wheel or All-Wheel Drive 6648
All-Wheel Drive 2401
4-Wheel Drive 1221
2-Wheel Drive 507
Part-time 4-Wheel Drive 198
Name: drive, dtype: int64
如果值太多,则查看排名前6的,折叠其余的:
>>> top_n = fueleco.make.value_counts().index[:6]
>>> (
... fueleco.assign(
... make=fueleco.make.where(
... fueleco.make.isin(top_n), "Other"
... )
... ).make.value_counts()
... )
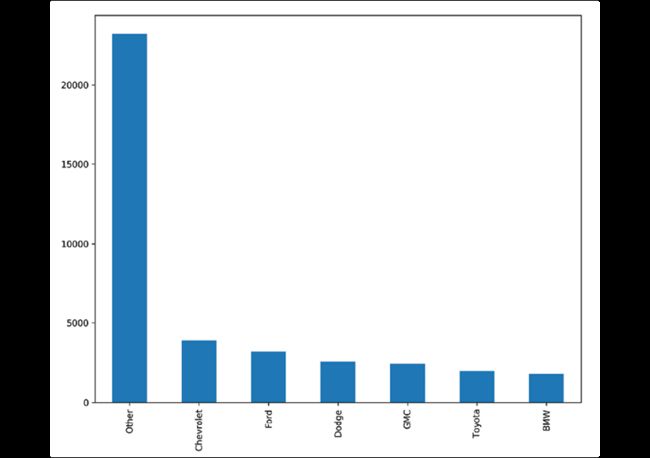
Other 23211
Chevrolet 3900
Ford 3208
Dodge 2557
GMC 2442
Toyota 1976
BMW 1807
Name: make, dtype: int64
使用Pandas对统计作图:
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> top_n = fueleco.make.value_counts().index[:6]
>>> (
... fueleco.assign(
... make=fueleco.make.where(
... fueleco.make.isin(top_n), "Other"
... )
... )
... .make.value_counts()
... .plot.bar(ax=ax)
... )
>>> fig.savefig("c5-catpan.png", dpi=300)
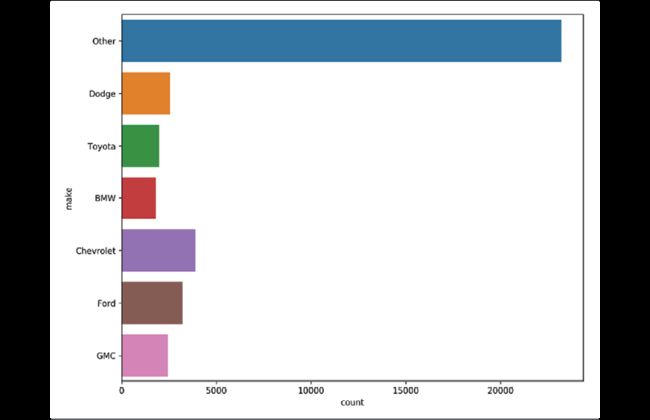
使用seaborn对统计作图:
>>> import seaborn as sns
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> top_n = fueleco.make.value_counts().index[:6]
>>> sns.countplot(
... y="make",
... data=(
... fueleco.assign(
... make=fueleco.make.where(
... fueleco.make.isin(top_n), "Other"
... )
... )
... ),
... )
>>> fig.savefig("c5-catsns.png", dpi=300)
原理
查看drive列是缺失值的行:
>>> fueleco[fueleco.drive.isna()]
barrels08 barrelsA08 ... phevHwy phevComb
7138 0.240000 0.0 ... 0 0
8144 0.312000 0.0 ... 0 0
8147 0.270000 0.0 ... 0 0
18215 15.695714 0.0 ... 0 0
18216 14.982273 0.0 ... 0 0
... ... ... ... ... ...
23023 0.240000 0.0 ... 0 0
23024 0.546000 0.0 ... 0 0
23026 0.426000 0.0 ... 0 0
23031 0.426000 0.0 ... 0 0
23034 0.204000 0.0 ... 0 0
因为value_counts不统计缺失值,设置dropna=False就可以统计缺失值:
>>> fueleco.drive.value_counts(dropna=False)
Front-Wheel Drive 13653
Rear-Wheel Drive 13284
4-Wheel or All-Wheel Drive 6648
All-Wheel Drive 2401
4-Wheel Drive 1221
NaN 1189
2-Wheel Drive 507
Part-time 4-Wheel Drive 198
Name: drive, dtype: int64
更多
rangeA这列是object类型,但用.value_counts检查时,发现它其实是数值列。这是因为该列包含/和-,Pandas将其解释成了字符串列。
>>> fueleco.rangeA.value_counts()
290 74
270 56
280 53
310 41
277 38
..
328 1
250/370 1
362/537 1
310/370 1
340-350 1
Name: rangeA, Length: 216, dtype: int64
可以使用.str.extract方法和正则表达式提取冲突字符:
>>> (
... fueleco.rangeA.str.extract(r"([^0-9.])")
... .dropna()
... .apply(lambda row: "".join(row), axis=1)
... .value_counts()
... )
/ 280
- 71
Name: rangeA, dtype: int64
缺失值的类型是字符串:
>>> set(fueleco.rangeA.apply(type))
{, }
统计缺失值的数量:
>>> fueleco.rangeA.isna().sum()
37616
将缺失值替换为0,-替换为/,根据/分割字符串,然后取平均值:
>>> (
... fueleco.rangeA.fillna("0")
... .str.replace("-", "/")
... .str.split("/", expand=True)
... .astype(float)
... .mean(axis=1)
... )
0 0.0
1 0.0
2 0.0
3 0.0
4 0.0
...
39096 0.0
39097 0.0
39098 0.0
39099 0.0
39100 0.0
Length: 39101, dtype: float64
另一种处理数值列的方法是用cut和qcut方法分桶:
>>> (
... fueleco.rangeA.fillna("0")
... .str.replace("-", "/")
... .str.split("/", expand=True)
... .astype(float)
... .mean(axis=1)
... .pipe(lambda ser_: pd.cut(ser_, 10))
... .value_counts()
... )
(-0.45, 44.95] 37688
(269.7, 314.65] 559
(314.65, 359.6] 352
(359.6, 404.55] 205
(224.75, 269.7] 181
(404.55, 449.5] 82
(89.9, 134.85] 12
(179.8, 224.75] 9
(44.95, 89.9] 8
(134.85, 179.8] 5
dtype: int64
qcut方法是按分位数平均分桶:
>>> (
... fueleco.rangeA.fillna("0")
... .str.replace("-", "/")
... .str.split("/", expand=True)
... .astype(float)
... .mean(axis=1)
... .pipe(lambda ser_: pd.qcut(ser_, 10))
... .value_counts()
... )
Traceback (most recent call last):
...
ValueError: Bin edges must be unique: array([ 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. , 449.5]).
>>> (
... fueleco.city08.pipe(
... lambda ser: pd.qcut(ser, q=10)
... ).value_counts()
... )
(5.999, 13.0] 5939
(19.0, 21.0] 4477
(14.0, 15.0] 4381
(17.0, 18.0] 3912
(16.0, 17.0] 3881
(15.0, 16.0] 3855
(21.0, 24.0] 3676
(24.0, 150.0] 3235
(13.0, 14.0] 2898
(18.0, 19.0] 2847
Name: city08, dtype: int64
5.4 连续型数据
提取出数值列:
>>> fueleco.select_dtypes("number")
barrels08 barrelsA08 ... phevHwy phevComb
0 15.695714 0.0 ... 0 0
1 29.964545 0.0 ... 0 0
2 12.207778 0.0 ... 0 0
3 29.964545 0.0 ... 0 0
4 17.347895 0.0 ... 0 0
... ... ... ... ... ...
39096 14.982273 0.0 ... 0 0
39097 14.330870 0.0 ... 0 0
39098 15.695714 0.0 ... 0 0
39099 15.695714 0.0 ... 0 0
39100 18.311667 0.0 ... 0 0
使用.sample查看一些数据:
>>> fueleco.city08.sample(5, random_state=42)
4217 11
1736 21
36029 16
37631 16
1668 17
Name: city08, dtype: int64
查看缺失值的数量和比例:
>>> fueleco.city08.isna().sum()
0
>>> fueleco.city08.isna().mean() * 100
0.0
获取统计信息:
>>> fueleco.city08.describe()
count 39101.000000
mean 18.077799
std 6.970672
min 6.000000
25% 15.000000
50% 17.000000
75% 20.000000
max 150.000000
Name: city08, dtype: float64
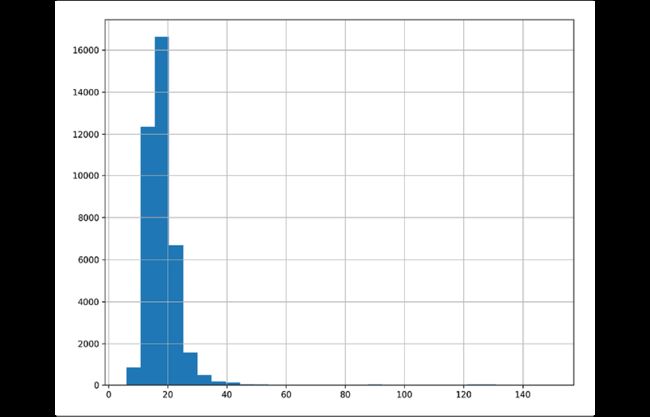
使用Pandas画柱状图:
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> fueleco.city08.hist(ax=ax)
>>> fig.savefig(
... "c5-conthistpan.png", dpi=300
... )
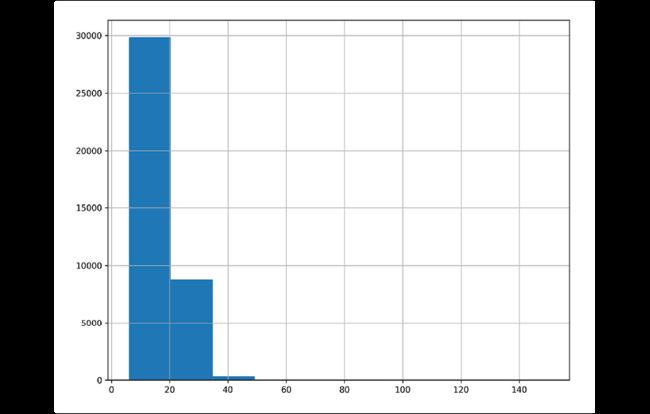
发现这张图中的数据很偏移,尝试提高分桶的数目:
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> fueleco.city08.hist(ax=ax, bins=30)
>>> fig.savefig(
... "c5-conthistpanbins.png", dpi=300
... )
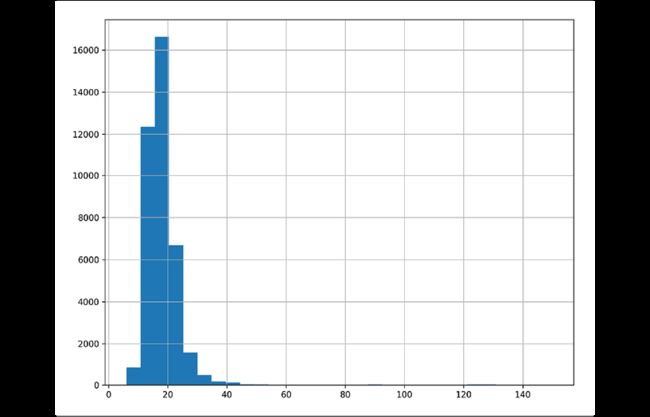
使用seaborn创建分布图,包括柱状图、核密度估计和地毯图:
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> sns.distplot(fueleco.city08, rug=True, ax=ax)
>>> fig.savefig(
... "c5-conthistsns.png", dpi=300
... )
更多
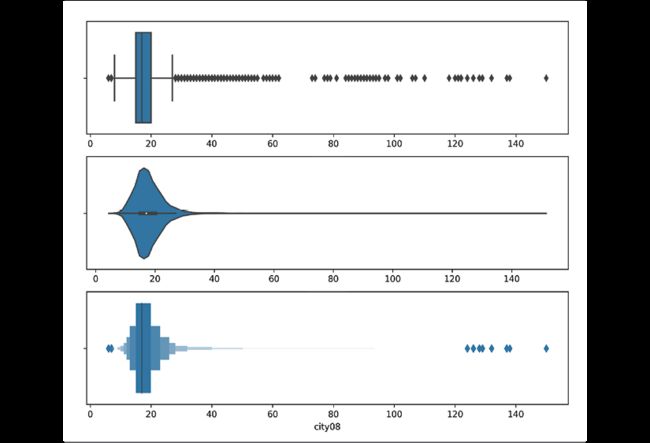
seaborn中还有其它用于表征数据分布的图:
>>> fig, axs = plt.subplots(nrows=3, figsize=(10, 8))
>>> sns.boxplot(fueleco.city08, ax=axs[0])
>>> sns.violinplot(fueleco.city08, ax=axs[1])
>>> sns.boxenplot(fueleco.city08, ax=axs[2])
>>> fig.savefig("c5-contothersns.png", dpi=300)
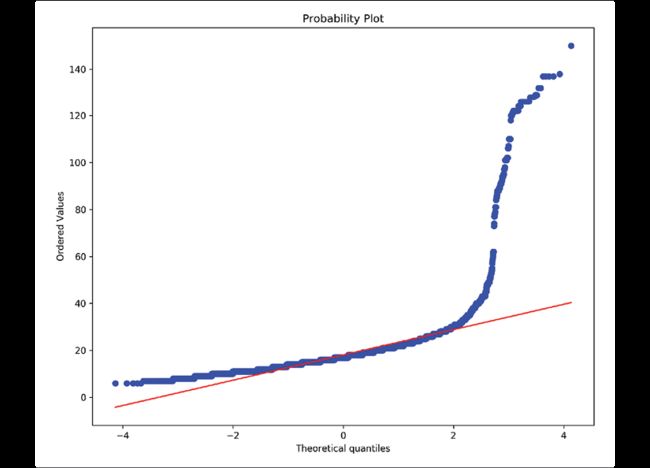
如果想检查数据是否是正态分布的,可以使用Kolmogorov-Smirnov测试,该测试提供了一个p值,如果p < 0.05,则不是正态分布的:
>>> from scipy import stats
>>> stats.kstest(fueleco.city08, cdf="norm")
KstestResult(statistic=0.9999999990134123, pvalue=0.0)
还可以用概率图检查数据是否是正态的,如果贴合红线,则数据是正态的:
>>> from scipy import stats
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> stats.probplot(fueleco.city08, plot=ax)
>>> fig.savefig("c5-conprob.png", dpi=300)
5.5 在不同种数据间比较连续值
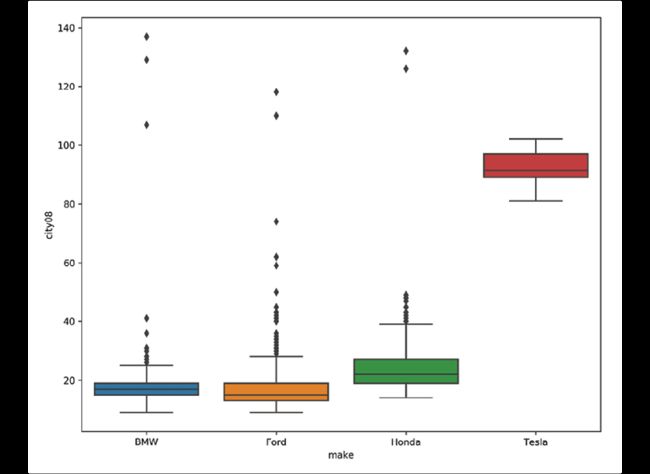
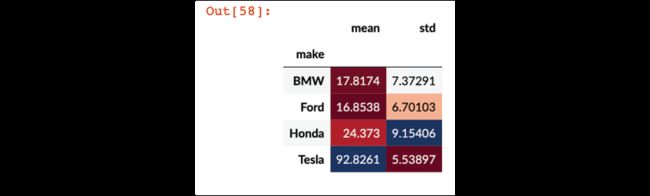
分析Ford、Honda、Tesla、BMW四个品牌的city08列的平均值和标准差:
>>> mask = fueleco.make.isin(
... ["Ford", "Honda", "Tesla", "BMW"]
... )
>>> fueleco[mask].groupby("make").city08.agg(
... ["mean", "std"]
... )
mean std
make
BMW 17.817377 7.372907
Ford 16.853803 6.701029
Honda 24.372973 9.154064
Tesla 92.826087 5.538970
使用seaborn进行画图:
>>> g = sns.catplot(
... x="make", y="city08", data=fueleco[mask], kind="box"
... )
>>> g.ax.figure.savefig("c5-catbox.png", dpi=300)
更多
boxplot不能体现出每个品牌中的数据量:
>>> mask = fueleco.make.isin(
... ["Ford", "Honda", "Tesla", "BMW"]
... )
>>> (fueleco[mask].groupby("make").city08.count())
make
BMW 1807
Ford 3208
Honda 925
Tesla 46
Name: city08, dtype: int64
另一种方法是在boxplot的上方画swarmplot:
>>> g = sns.catplot(
... x="make", y="city08", data=fueleco[mask], kind="box"
... )
>>> sns.swarmplot(
... x="make",
... y="city08",
... data=fueleco[mask],
... color="k",
... size=1,
... ax=g.ax,
... )
>>> g.ax.figure.savefig(
... "c5-catbox2.png", dpi=300
... )
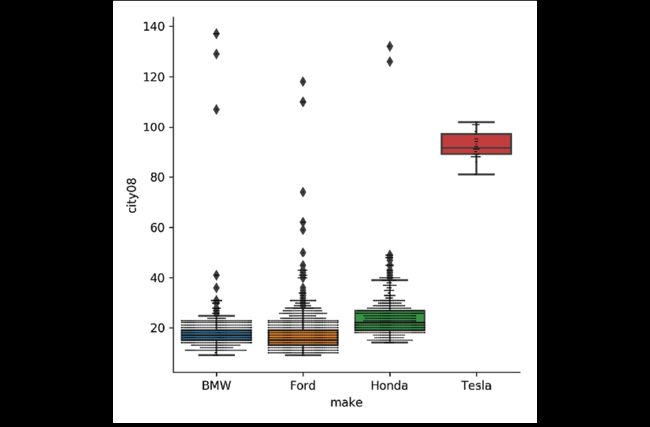
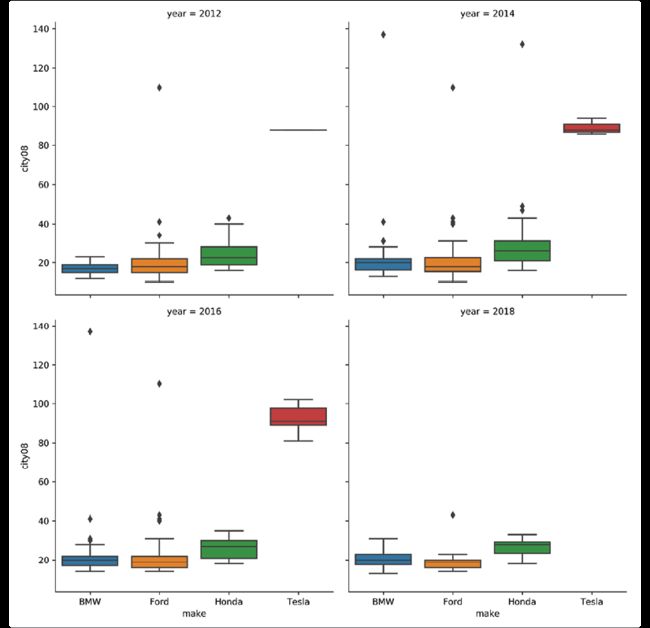
catplot可以补充更多的维度,比如年份:
>>> g = sns.catplot(
... x="make",
... y="city08",
... data=fueleco[mask],
... kind="box",
... col="year",
... col_order=[2012, 2014, 2016, 2018],
... col_wrap=2,
... )
>>> g.axes[0].figure.savefig(
... "c5-catboxcol.png", dpi=300
... )
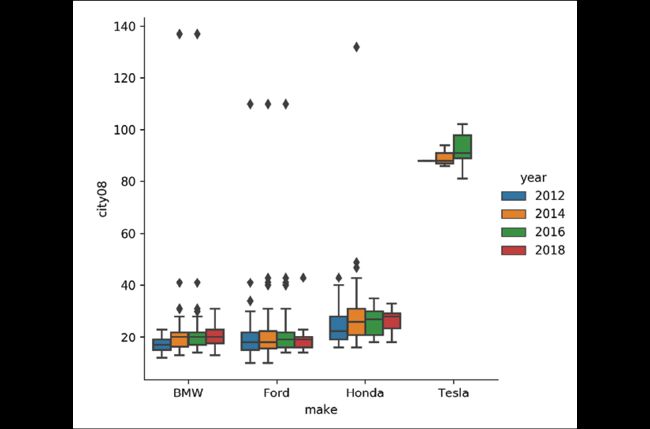
或者,可以通过参数hue将四张图放进一张:
>>> g = sns.catplot(
... x="make",
... y="city08",
... data=fueleco[mask],
... kind="box",
... hue="year",
... hue_order=[2012, 2014, 2016, 2018],
... )
>>> g.ax.figure.savefig(
... "c5-catboxhue.png", dpi=300
... )
如果是在Jupyter中,可以对groupby结果使用格式:
>>> mask = fueleco.make.isin(
... ["Ford", "Honda", "Tesla", "BMW"]
... )
>>> (
... fueleco[mask]
... .groupby("make")
... .city08.agg(["mean", "std"])
... .style.background_gradient(cmap="RdBu", axis=0)
... )
5.6 比较两列连续型数据列
比较两列的协方差:
>>> fueleco.city08.cov(fueleco.highway08)
46.33326023673625
>>> fueleco.city08.cov(fueleco.comb08)
47.41994667819079
>>> fueleco.city08.cov(fueleco.cylinders)
-5.931560263764761
比较两列的皮尔森系数:
>>> fueleco.city08.corr(fueleco.highway08)
0.932494506228495
>>> fueleco.city08.corr(fueleco.cylinders)
-0.701654842382788
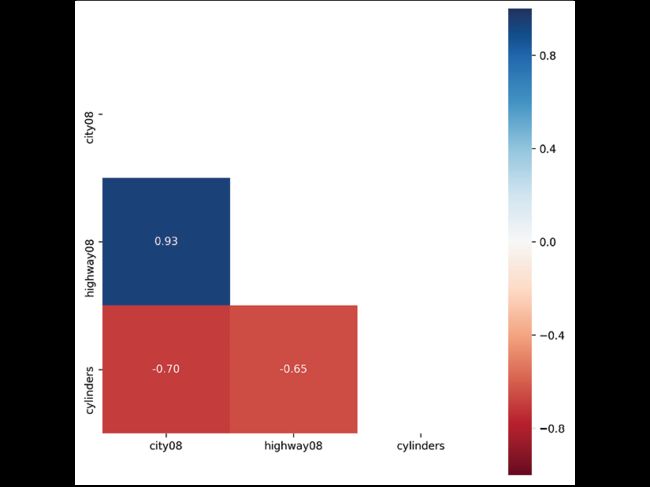
用热力图显示相关系数:
>>> import seaborn as sns
>>> fig, ax = plt.subplots(figsize=(8, 8))
>>> corr = fueleco[
... ["city08", "highway08", "cylinders"]
... ].corr()
>>> mask = np.zeros_like(corr, dtype=np.bool)
>>> mask[np.triu_indices_from(mask)] = True
>>> sns.heatmap(
... corr,
... mask=mask,
... fmt=".2f",
... annot=True,
... ax=ax,
... cmap="RdBu",
... vmin=-1,
... vmax=1,
... square=True,
... )
>>> fig.savefig(
... "c5-heatmap.png", dpi=300, bbox_inches="tight"
... )
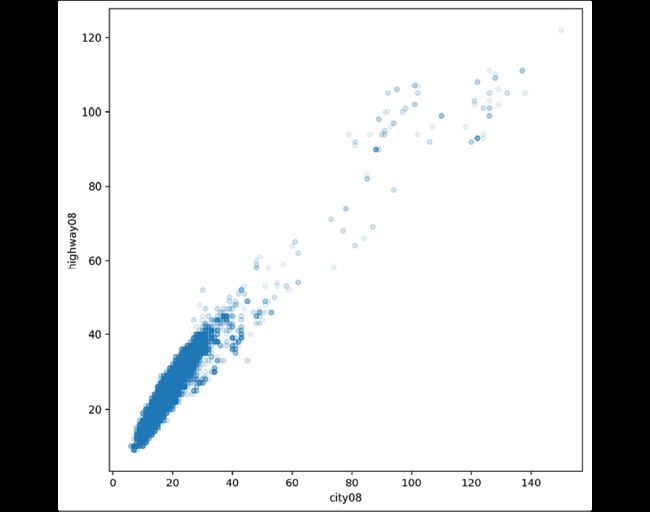
用散点图表示关系:
>>> fig, ax = plt.subplots(figsize=(8, 8))
>>> fueleco.plot.scatter(
... x="city08", y="highway08", alpha=0.1, ax=ax
... )
>>> fig.savefig(
... "c5-scatpan.png", dpi=300, bbox_inches="tight"
... )
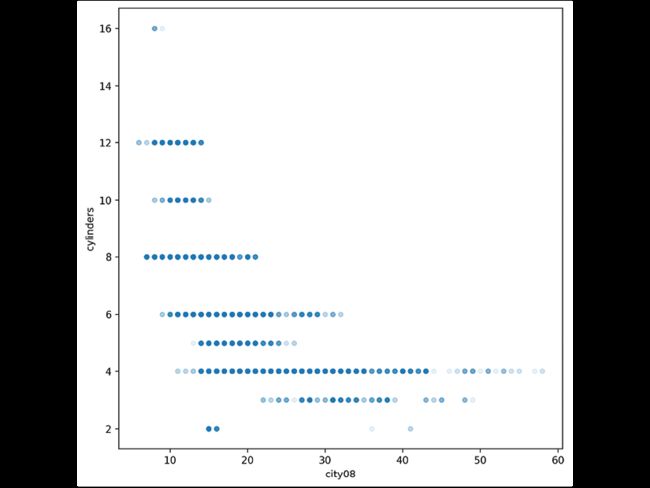
>>> fig, ax = plt.subplots(figsize=(8, 8))
>>> fueleco.plot.scatter(
... x="city08", y="cylinders", alpha=0.1, ax=ax
... )
>>> fig.savefig(
... "c5-scatpan-cyl.png", dpi=300, bbox_inches="tight"
... )
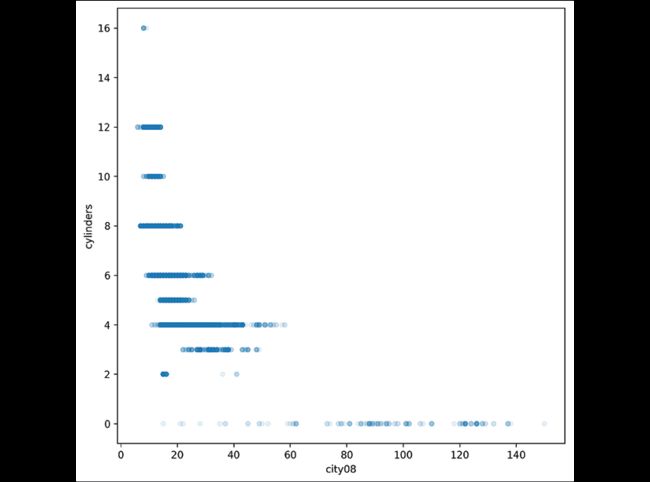
因为有的车是电车,没有气缸,我们将缺失值填为0:
>>> fueleco.cylinders.isna().sum()
145
>>> fig, ax = plt.subplots(figsize=(8, 8))
>>> (
... fueleco.assign(
... cylinders=fueleco.cylinders.fillna(0)
... ).plot.scatter(
... x="city08", y="cylinders", alpha=0.1, ax=ax
... )
... )
>>> fig.savefig(
... "c5-scatpan-cyl0.png", dpi=300, bbox_inches="tight"
... )
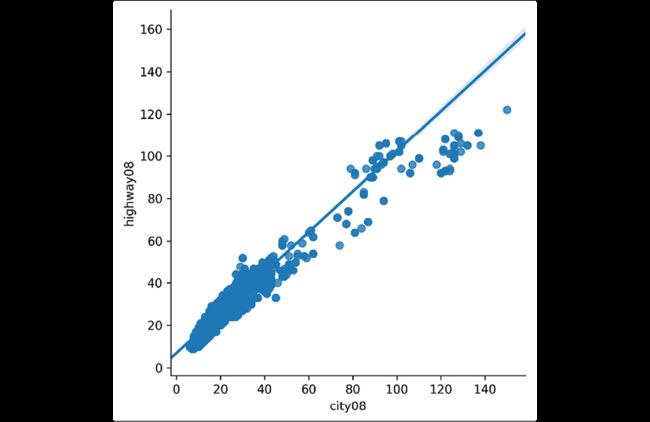
使用seaborn添加回归线:
>>> res = sns.lmplot(
... x="city08", y="highway08", data=fueleco
... )
>>> res.fig.savefig(
... "c5-lmplot.png", dpi=300, bbox_inches="tight"
... )
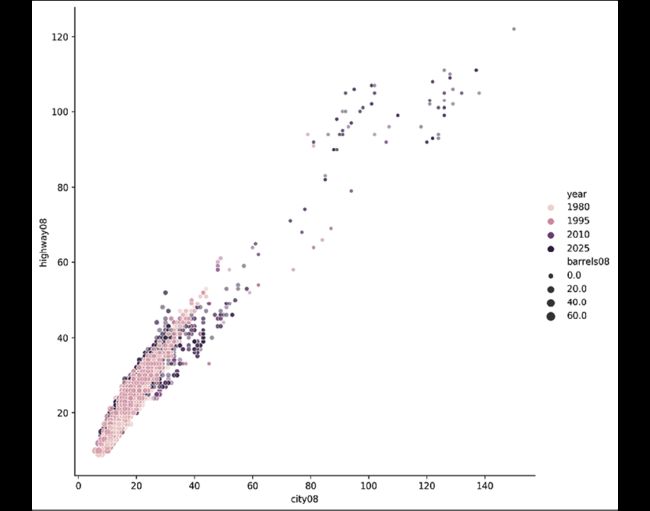
使用relplot,散点可以有不同的颜色和大小:
>>> res = sns.relplot(
... x="city08",
... y="highway08",
... data=fueleco.assign(
... cylinders=fueleco.cylinders.fillna(0)
... ),
... hue="year",
... size="barrels08",
... alpha=0.5,
... height=8,
... )
>>> res.fig.savefig(
... "c5-relplot2.png", dpi=300, bbox_inches="tight"
... )
还可以加入类别维度:
>>> res = sns.relplot(
... x="city08",
... y="highway08",
... data=fueleco.assign(
... cylinders=fueleco.cylinders.fillna(0)
... ),
... hue="year",
... size="barrels08",
... alpha=0.5,
... height=8,
... col="make",
... col_order=["Ford", "Tesla"],
... )
>>> res.fig.savefig(
... "c5-relplot3.png", dpi=300, bbox_inches="tight"
... )

如果两列不是线性关系,还可以使用斯皮尔曼系数:
>>> fueleco.city08.corr(
... fueleco.barrels08, method="spearman"
... )
-0.9743658646193255
5.7 比较类型值
降低基数,将VClass列变为SClass,只用六个值:
>>> def generalize(ser, match_name, default):
... seen = None
... for match, name in match_name:
... mask = ser.str.contains(match)
... if seen is None:
... seen = mask
... else:
... seen |= mask
... ser = ser.where(~mask, name)
... ser = ser.where(seen, default)
... return ser
>>> makes = ["Ford", "Tesla", "BMW", "Toyota"]
>>> data = fueleco[fueleco.make.isin(makes)].assign(
... SClass=lambda df_: generalize(
... df_.VClass,
... [
... ("Seaters", "Car"),
... ("Car", "Car"),
... ("Utility", "SUV"),
... ("Truck", "Truck"),
... ("Van", "Van"),
... ("van", "Van"),
... ("Wagon", "Wagon"),
... ],
... "other",
... )
... )
对每个品牌的车辆品类进行计数:
>>> data.groupby(["make", "SClass"]).size().unstack()
SClass Car SUV ... Wagon other
make ...
BMW 1557.0 158.0 ... 92.0 NaN
Ford 1075.0 372.0 ... 155.0 234.0
Tesla 36.0 10.0 ... NaN NaN
Toyota 773.0 376.0 ... 132.0 123.0
使用crosstab达到上一步同样的目标:
>>> pd.crosstab(data.make, data.SClass)
SClass Car SUV ... Wagon other
make ...
BMW 1557 158 ... 92 0
Ford 1075 372 ... 155 234
Tesla 36 10 ... 0 0
Toyota 773 376 ... 132 123
加入更多维度:
>>> pd.crosstab(
... [data.year, data.make], [data.SClass, data.VClass]
... )
SClass Car ... other
VClass Compact Cars Large Cars ... Special Purpose Vehicle 4WD
year make ...
1984 BMW 6 0 ... 0
Ford 33 3 ... 21
Toyota 13 0 ... 3
1985 BMW 7 0 ... 0
Ford 31 2 ... 9
... ... ... ... ...
2017 Tesla 0 8 ... 0
Toyota 3 0 ... 0
2018 BMW 37 12 ... 0
Ford 0 0 ... 0
Toyota 4 0 ... 0
使用Cramér's V方法检查品类的关系:
>>> import scipy.stats as ss
>>> import numpy as np
>>> def cramers_v(x, y):
... confusion_matrix = pd.crosstab(x, y)
... chi2 = ss.chi2_contingency(confusion_matrix)[0]
... n = confusion_matrix.sum().sum()
... phi2 = chi2 / n
... r, k = confusion_matrix.shape
... phi2corr = max(
... 0, phi2 - ((k - 1) * (r - 1)) / (n - 1)
... )
... rcorr = r - ((r - 1) ** 2) / (n - 1)
... kcorr = k - ((k - 1) ** 2) / (n - 1)
... return np.sqrt(
... phi2corr / min((kcorr - 1), (rcorr - 1))
... )
>>> cramers_v(data.make, data.SClass)
0.2859720982171866
.corr方法可以接收可调用变量,另一种方法如下:
>>> data.make.corr(data.SClass, cramers_v)
0.2859720982171866
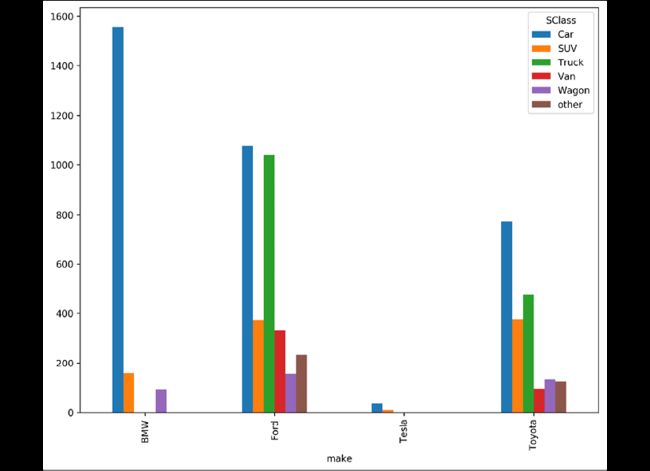
使用barplot可视化:
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> (
... data.pipe(
... lambda df_: pd.crosstab(df_.make, df_.SClass)
... ).plot.bar(ax=ax)
... )
>>> fig.savefig("c5-bar.png", dpi=300, bbox_inches="tight")
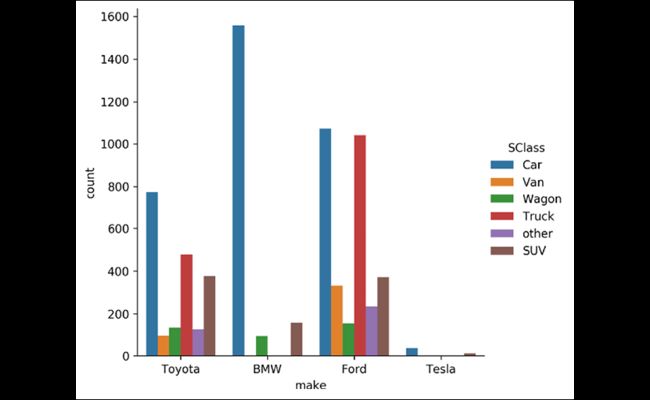
用seaborn实现:
>>> res = sns.catplot(
... kind="count", x="make", hue="SClass", data=data
... )
>>> res.fig.savefig(
... "c5-barsns.png", dpi=300, bbox_inches="tight"
... )
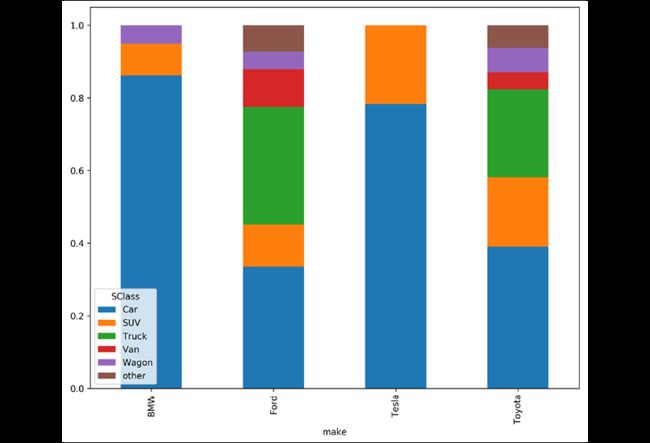
使用堆积条形图来表示:
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> (
... data.pipe(
... lambda df_: pd.crosstab(df_.make, df_.SClass)
... )
... .pipe(lambda df_: df_.div(df_.sum(axis=1), axis=0))
... .plot.bar(stacked=True, ax=ax)
... )
>>> fig.savefig(
... "c5-barstacked.png", dpi=300, bbox_inches="tight"
... )
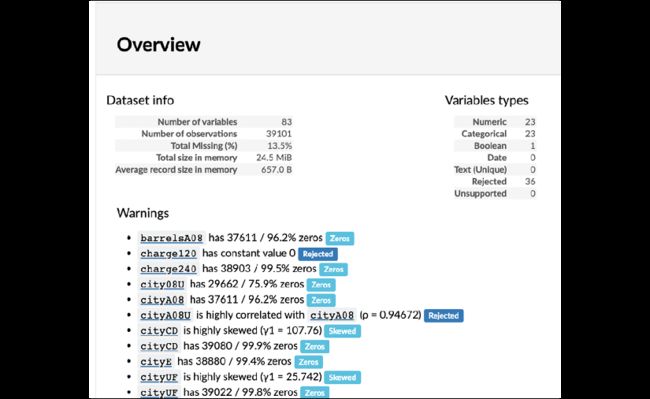
5.8 使用Pandas的profiling库
使用pip install pandas-profiling安装profiling库。使用ProfileReport创建一个HTML报告:
>>> import pandas_profiling as pp
>>> pp.ProfileReport(fueleco)
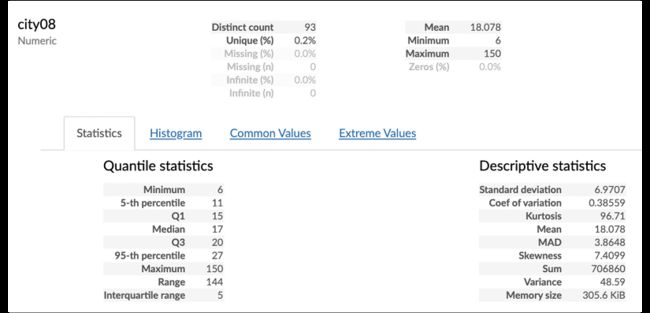
可以将其保存到文件:
>>> report = pp.ProfileReport(fueleco)
>>> report.to_file("fuel.html")
第01章 Pandas基础
第02章 DataFrame基础运算
第03章 创建和持久化DataFrame
第04章 开始数据分析
第05章 探索性数据分析
第06章 选取数据子集
第07章 过滤行
第08章 索引对齐