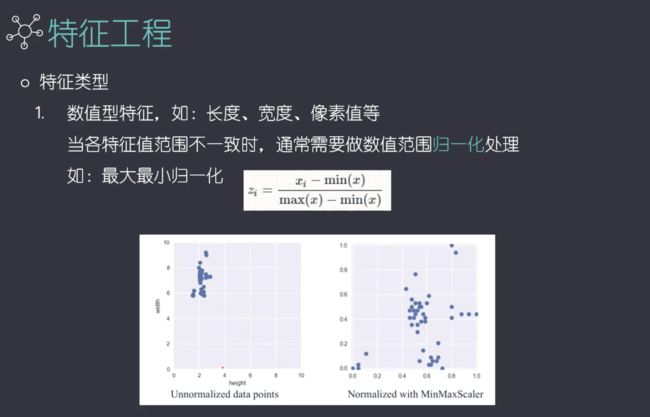

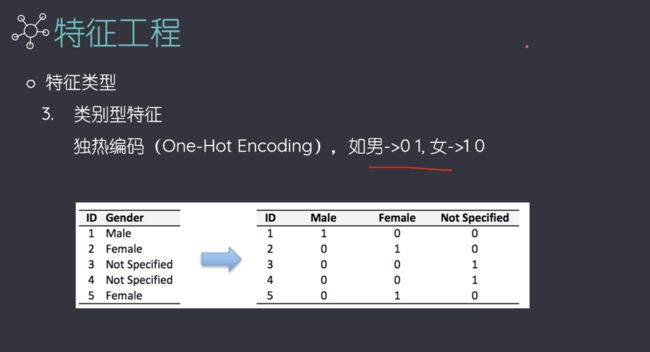
类别较多的时候,独热编码性能不好,可能会造成类数的爆炸,可以预先进行粗分,再接着往下分类。
独热编码的矩阵是稀疏矩阵。

# 人工智能数据源下载地址:https://video.mugglecode.com/data_ai.zip,下载压缩包后解压即可(数据源与上节课相同)
# -*- coding: utf-8 -*-
"""
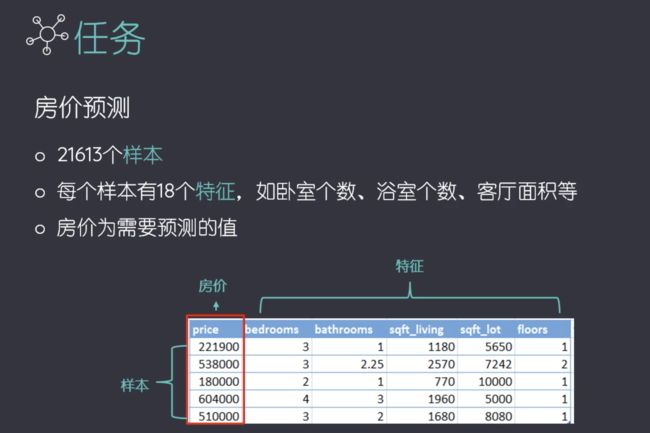
任务:房屋价格预测
"""
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import OneHotEncoder, MinMaxScaler
import numpy as np
DATA_FILE = './data_ai/house_data.csv'
# 使用的特征列
NUMERIC_FEAT_COLS = ['sqft_living', 'sqft_above', 'sqft_basement', 'long', 'lat']
CATEGORY_FEAT_COLS = ['waterfront']
def process_features(X_train, X_test):
"""
特征预处理
"""
# 1. 对类别型特征做one-hot encoding
encoder = OneHotEncoder(sparse=False)
encoded_tr_feat = encoder.fit_transform(X_train[CATEGORY_FEAT_COLS])
encoded_te_feat = encoder.transform(X_test[CATEGORY_FEAT_COLS])
# 2. 对数值型特征值做归一化处理
scaler = MinMaxScaler()
scaled_tr_feat = scaler.fit_transform(X_train[NUMERIC_FEAT_COLS])
scaled_te_feat = scaler.transform(X_test[NUMERIC_FEAT_COLS])
# 3. 特征合并
X_train_proc = np.hstack((encoded_tr_feat, scaled_tr_feat))
X_test_proc = np.hstack((encoded_te_feat, scaled_te_feat))
return X_train_proc, X_test_proc
def main():
"""
主函数
"""
house_data = pd.read_csv(DATA_FILE, usecols=NUMERIC_FEAT_COLS + CATEGORY_FEAT_COLS + ['price'])
X = house_data[NUMERIC_FEAT_COLS + CATEGORY_FEAT_COLS]
y = house_data['price']
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3, random_state=10)
# 建立线性回归模型
linear_reg_model = LinearRegression()
# 模型训练
linear_reg_model.fit(X_train, y_train)
# 验证模型
r2_score = linear_reg_model.score(X_test, y_test)
print('模型的R2值', r2_score)
# 数据预处理
X_train_proc, X_test_proc = process_features(X_train, X_test)
# 建立线性回归模型
linear_reg_model2 = LinearRegression()
# 模型训练
linear_reg_model2.fit(X_train_proc, y_train)
# 验证模型
r2_score2 = linear_reg_model2.score(X_test_proc, y_test)
print('特征处理后,模型的R2值', r2_score2)
print('模型提升了{:.2f}%'.format( (r2_score2 - r2_score) / r2_score * 100) )
if __name__ == '__main__':
main()
模型的R2值 0.627060068329868
特征处理后,模型的R2值 0.6272862884031768
模型提升了0.04%
可能有的疑问解答:
OneHotEncoder, MinMaxScaler 操作完以后自动会把pandas对象转化成numpy对象是吗?特征处理前后数据类型不一样对吧?np对象和pandas对象不影响?
有影响,OneHotEncoder, MinMaxScaler 操作完以后自动会把pandas对象转化成numpy对象,pandas对象跟numpy经常转换来转换去的。
scikit-learn要求X是一个特征矩阵,y是一个NumPy向量,pandas构建在NumPy之上。因此,X可以是pandas的DataFrame,y可以是pandas的Series,scikit-learn可以理解这种结构。
-
只是这个X特征矩阵是numpy.ndarray格式,或者是pandas.core.frame.DataFrame格式,都可以传入进model中去的。
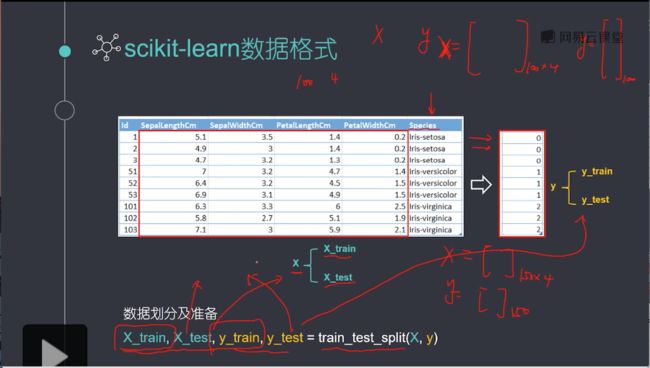 image.png
image.png
scikit-learn中fit_transform()与transform()到底有什么区别,能不能混用?
fit_transform是fit和transform的组合。
fit(x,y)在新手入门的例子中比较多,但是这里的fit_transform(x)的括号中只有一个参数,这是因为fit(x,y)传两个参数的是有监督学习的算法,fit(x)传一个参数的是无监督学习的算法,比如降维、特征提取、标准化。
为什么出来fit_transform()这个东西?
fit和transform没有任何关系,仅仅是数据处理的两个不同环节,之所以出来这么个函数名,仅仅是为了写代码方便,
所以会发现transform()和fit_transform()的运行结果是一样的。
注意:运行结果一模一样不代表这两个函数可以互相替换,绝对不可以。transform函数是一定可以替换为fit_transform函数的,fit_transform函数不能替换为transform函数!
因为 sklearn里的封装好的各种算法都要fit、然后调用各种API方法,transform只是其中一个API方法,所以当你调用除transform之外的方法,必须要先fit,为了通用的写代码,还是分开写比较好
也就是说,这个fit相对于transform而言是没有任何意义的,但是相对于整个代码而言,fit是为后续的API函数服务的,所以fit_transform不能改写为transform。
fit_transform与transform运行结果一致,但是fit与transform无关,只是数据处理的两个环节,fit是为了程序的后续函数transform的调用而服务的,是个前提条件。
如果把机器学习代码中的fit_transform改为transform,编译器就会报错。
总结
- 二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)
- fit_transform(partData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该partData进行转换transform,从而实现数据的标准化、归一化等等。。
- 根据对之前部分fit的整体指标,对剩余的数据(restData)使用同样的均值、方差、最大最小值等指标进行转换transform(restData),从而保证part、rest处理方式相同。
- 必须先用fit_transform(partData),之后再transform(restData)
如果直接transform(partData),程序会报错 - 如果fit_transfrom(partData)后,使用fit_transform(restData)而不用transform(restData),虽然也能归一化,但是两个结果不是在同一个“标准”下的,具有明显差异。
练习
使用特征预处理提升糖尿病患病指标预测模型的性能
题目描述:对特征进行预处理,然后预测糖尿病的患病指标,并比较模型的性能
题目要求:
对类别型特征及数值型特征进行预处理
数据文件:
数据源下载地址:https://video.mugglecode.com/diabetes.csv (数据源与之前相同)
diabetes.csv,包含了442个数据样本。
共11列数据
AGE:年龄
SEX: 性别
BMI: 体质指数(Body Mass Index)
BP: 平均血压(Average Blood Pressure)
S1~S6: 一年后的6项疾病级数指标
Y: 一年后患疾病的定量指标,为需要预测的标签
参考代码:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import OneHotEncoder, MinMaxScaler
def LR(X_train, X_test, y_train, y_test):
model = LinearRegression()
model.fit(X_train,y_train)
R2_score = model.score(X_test,y_test)
return R2_score
def attr_proc(X_train, X_test,feat_col_quant,feat_col_quali):
Encoder = OneHotEncoder(sparse= False)
Encoded_X_train_quali = Encoder.fit_transform(X_train[feat_col_quali])
Encoded_X_test_quali = Encoder.transform(X_test[feat_col_quali])
Scaler = MinMaxScaler()
Scaled_X_train_quant = Scaler.fit_transform(X_train[feat_col_quant])
Scaled_X_test_quant = Scaler.transform(X_test[feat_col_quant])
return np.hstack((Encoded_X_train_quali,Scaled_X_train_quant)), np.hstack((Encoded_X_test_quali,Scaled_X_test_quant))
data = pd.read_csv('./data_ai/diabetes.csv')
feat_col_quant = ['AGE','BMI','BP','S1','S2','S3','S4','S5','S6'] #定量量
feat_col_quali = ['SEX'] #定性量
X = data[feat_col_quant + feat_col_quali]
y = data[['Y']] #其实外面多套一层括号,结果还是一样的,不套括号也行,但是对于多列的那种还是要多套括号的
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=1/5,random_state=10)
X_train_proc, X_test_proc = attr_proc(X_train, X_test,feat_col_quant,feat_col_quali)
Non_proc_score = LR(X_train, X_test, y_train, y_test)
Proc_score = LR(X_train_proc, X_test_proc, y_train, y_test)
print(f'处理前R2得分为{Non_proc_score}\n处理后R2得分为{Proc_score}')
print(f'处理后的精确度相比处理前精确度变化了{(Proc_score-Non_proc_score)/Non_proc_score * 100}%')
运行结果:
处理前R2得分为0.5341988244945843
处理后R2得分为0.5327074373208649
处理后的精确度相比处理前精确度变化了-0.279182039595551%
所以把,有时候归一化拟合的效果还反而不好了,这是为啥呢?