Python爬虫 之数据解析之正则表达式
数据解析之正则表达式
-
- 一、聚焦爬虫
- 二、数据解析概述
- 三、正则表达式
- 四、实际案例
一、聚焦爬虫
1、概念
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。而我们日常使用的大多数是聚焦爬虫。
用一句话概括:
聚焦爬虫:爬取页面中所指定的页面内容
2、编码流程
① 指定url
② 发起请求
③ 获取相应数据
④ 数据解析
⑤ 持续化存储
二、数据解析概述
1、数据解析分类:
① 正则表达式
② bs4
③ xpath
而我们平日里最常用的是xpath,因为xpath这种数据解析的通用性比较强。不止在Python中可以使用xpath,在其它的编程语言中也会使用。
2、数据解析原理概述:
解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储
① 进行指定标签的定位
② 标签或者标签对应的属性中存储的数据值进行提取(解析)
三、正则表达式
1、概念
正则表达式是一个特殊的字符序列,它能帮助我们方便的检查一个字符串是否与某种模式匹配。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
2、常用正则表达式
① 单字符:
| 修饰符 | 描述 |
|---|---|
| . | 除换行以外所有字符 |
| […] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’;[a-z] 匹配a-z集合中任意一个字符 |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| \d | 数字 [0-9] |
| \D | 非数字 |
| \w | 数字、字母、下划线、中午 |
| \W | 非\w |
| \s | 所有的空白字符包,包括空格、制表符、换页符。价于[ \n \f \r \t \v]。 |
| \S |
② 数量修饰
| 修饰符 | 描述 |
|---|---|
| * | 任意多次 >=0 |
| + | 至少一次 >=1 |
| ? | 可有可无 0次或者1次 |
| {m} | 固定m次 例:hello{3} |
| {m,} | 至少m次 |
| {m,n} | m-n次 |
③ 边界
| 修饰符 | 描述 |
|---|---|
| $ | 以某某结尾 |
| ^ | 以某某开头 |
④ 分组
| 修饰符 | 描述 |
|---|---|
| 贪婪模式 | .* |
| 非贪婪(惰性)模式 | .*? |
⑤ 正则表达式修饰符
| 修饰符 | 描述 |
|---|---|
| re.I | 忽略大小写 |
| re.M | 多行匹配 |
| re.S | 单行匹配 |
⑥ 函数
re.sub(正则表达式, 替换内容, 字符串)
四、实际案例
需求:
爬取糗图百科中热图里面的所有图片,并且存在文件夹当中。
网址:https://www.qiushibaike.com/imgrank/
思路:
打开网页右键进入管理者选项,点击检查,查看图片的信息。我们发现每张图片都对应一个img src,而这个img src对应的就是图片的地址。我们可以用requests.get方法得到页面所有的数据,然后再用正则表达对某一个部分进行截取。
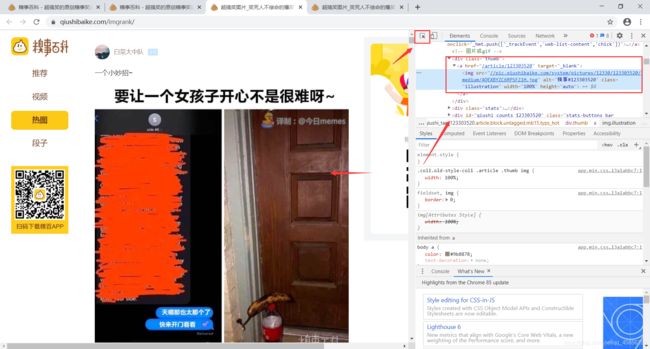
就是对这个thumb下面的进行截取。这样我们就完成了对一张页面的所有图片进行爬取的操作。
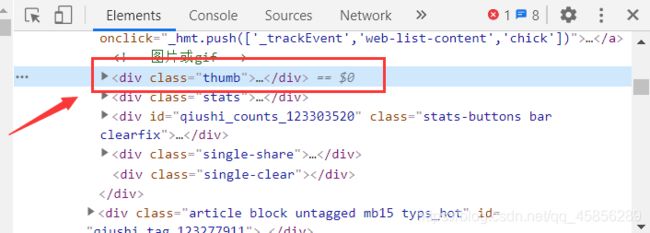
然后只需要完成,所有页码的所有照片进行爬取即可。我们发现每一页的前面部分都是相同的,只有page后面的数字不同,而且这个数字正好和页码相同,也就是说这个数字是页码。我们可以用for循环进行遍历,通过%和format()函数进行格式化控制字符,这样就完成了对每一页url的遍历,也就完成了对每一页的每张图片爬取的操作。

![]()
完整代码:
# 爬取糗图百科图片数据
import requests
import re
import os
if __name__ == '__main__':
# 创建一个文件夹,用来保存图片
if not os.path.exists('./Tupian'):
os.mkdir('./Tupian')
# 进行UA伪装
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
# 指定url
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
# 可以任意页码(从n到m:range(n,m+1))
for num in range(1,5):
new_url = format(url%num)
# 使用通用爬虫对url对应的一整张页面进行爬取
page_text = requests.get(url=new_url,headers=header).text
# print(page_text)
# 使用聚焦爬虫将页面所有的图片进行解析/提取
ex = '.*?) '
img_src_list = re.findall(ex,page_text,re.S)
# print(img_src_list)
for src in img_src_list:
# 一张图片完整的地址 拼接出一个完整的url
src = 'https:' + src
# 请求到了图片的二进制数据
# constent返回一个二进制相应数据
img_data = requests.get(url=src,headers=header).content
# 生成图片名称
img_name = src.split('/')[-1]
# print(img_name, '爬取成功!!!')
# 图片存储路径
img_path = '/Tupian' + img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name, '下载成功!!!')
'
img_src_list = re.findall(ex,page_text,re.S)
# print(img_src_list)
for src in img_src_list:
# 一张图片完整的地址 拼接出一个完整的url
src = 'https:' + src
# 请求到了图片的二进制数据
# constent返回一个二进制相应数据
img_data = requests.get(url=src,headers=header).content
# 生成图片名称
img_name = src.split('/')[-1]
# print(img_name, '爬取成功!!!')
# 图片存储路径
img_path = '/Tupian' + img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name, '下载成功!!!')