前面介绍了深度神经网络和卷积神经网络,这些神经网络有个特点:输入的向量越大,训练得到的模型越大。但是,拥有大量参数模型的代价是昂贵的,它需要大量的数据进行训练,否则由于缺少足够的训练数据,就可能出现过拟合的问题。尽管卷积神经网络能够在不损失模型性能的情况下减少模型参数,但是仍然需要大量带有标签的数据进行训练。半监督学习通过进一步学习未标签数据来解决这个问题,具体思路是:从未标签数据上学习数据的表征,用这些表征来解决监督学习问题。
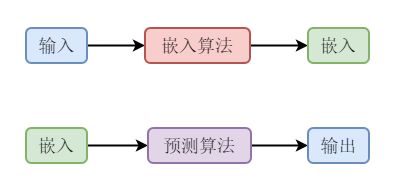
本章介绍的非监督学习中的嵌入方法,又称为低维度表征。非监督学习不用自动特征选取,只用少量数据学习一个相对较小的嵌入模型来解决学习问题,如下图所示。
为了更好地理解嵌入学习,需要探索其他的低维度表征算法,比如可视化和PCA。如果考虑到所有的重要信息都包含在原始的输入时,嵌入学习就等同于一个有效的压缩算法。本章首先介绍经典的降维算法PCA,然后介绍基于强大神经网络的嵌入学习算法。
1.PCA算法
主成分分析(Principal Component Analysis,PCA),是一种分析、简化数据的常用技术。PCA能够减少数据的维度,同时保持数据集中的对方差贡献较大的特征。这种方法是通过保留低阶主成分、忽略高阶主成分做到的。
1.PCA原理
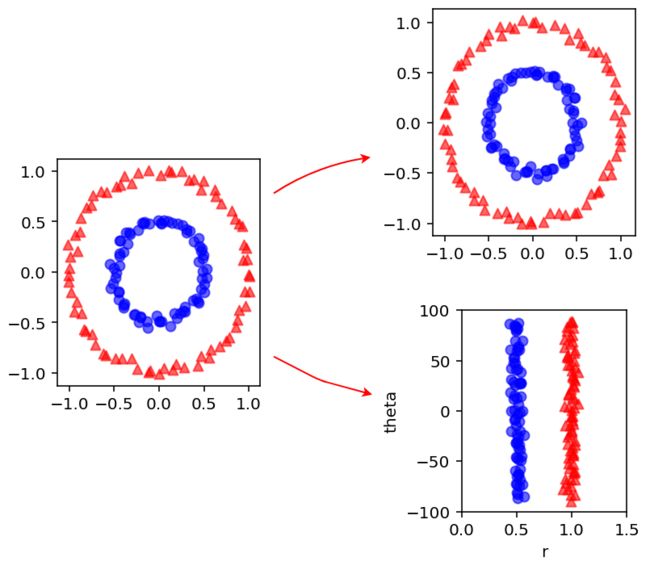
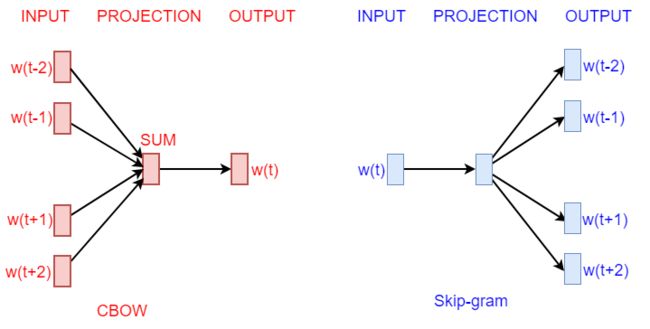
PCA的基本原理是从大量数据中找到少量的主成分变量,在数据维度降低的情况下,尽可能地保留原始数据的信息。比如,假设一个d维的数据,找到一个新的m维数据,其中m 从数学上看,PCA可以看做是输入数据X在向量空间W上的投影,向量空间W由输入数据的协方差矩阵的前m个特征向量扩展得到。假设输入数据是一个维度为n * d的矩阵X,需要创建一个尺寸为n * m的矩阵T(PCA变换),可以使用公式T=WX得到。其中,W的每列对于矩阵XX^T的特征向量。 PCA用于数据降维已经很多年了,但是对于分段线性和非线性问题是不起作用的。如下图所示。原始数据是两个同心圆,如果做PCA变换操作,变换后结果还是两个同心圆。作为人来说,可以直观地将两个同心圆进行区分,只要做极坐标变换,两个同心圆就会变成两个竖向量,这样数据就变成线性可分的了。 上图表示了PCA算法在处理复杂数据时的局限。通常的数据集合(比如图片、文本)都是非线性的,因此有必要找到新的方法来处理非线性的数据降维。采用深度神经网络模型就是一个不错的思路。 前面介绍的PCA算法使用了协方差矩阵,下面代码中的PCA计算过程使用SVD。基于PyTorch的PCA方法如下: 从图中可以看出,对比原始数据和进行PCA的数据,PCA对数据有聚类的作用,有利于数据分类。 1986年Rumelhart提出了自编码器的概念,并将其用于高维复杂数据的降维。自编码器是一种无监督学习算法,使用反向传播,训练目标是让目标值等于输入值。需要指出,这时的自编码器模型网络的层比较浅,只有一个输入层、一个隐含层、一个输出层。Hinton和Salakhutdinov于2006年在《Reducing the dimensionality of data with neural networks》一文中提出了深度自编码器。其显著特点是,模型网络的层较深,提高了学习能力。一般的,没有特殊说明,常见的自编码器都是深度自编码器。 在前向神经网络中,每一个神经网络层都能够学习更深刻的表征输入。在卷积神经网络中,最后一个卷积层能用作输入图片的低维度表征。但在非监督学习中,就不能用这种前向神经网络来做低维度表征。这些神经网络层的确包含输入数据的信息,但是这些信息是当前神经网络训练得到的,也只对当前的任务或目标函数有效。这样可能会导致一个结果,即一些对当前任务不那么重要的信息丢掉了,但是这些信息对其他分类任务至关重要。 在非监督学习中,提出了新的神经网络。这种新的神经网络叫做自编码器。自编码器的结构如下图所示。输入数据经过编码压缩得到低维度向量,这个部分称为编码器,因为它产生了低维度嵌入或者编码。网络的第二部分不同于在前向神经网络中把嵌入映射为输出标签,而是把编码器逆化,重建原始输入,这个部分称为解码。 自编码器是一种类似PCA的神经网络,它是无监督学习方法,目标输出就是其输出。尽管自编码器和PCA都能对数据进行压缩,但是自编码器比PCA灵活和强大得多。在编码过程中,自编码器能够表征线性变换,也能够表征非线性变换;而PCA只能表征线性变换。自编码器能够用于数据的压缩和恢复,还可以用于数据的去噪。 为了展示自编码器的性能,本节用PyTorch实现一个自编码器,并用其进行MNIST图片分类。相对于PCA而言,自编码器性能更加优越。为了对比分析,分别用PyTorch实现自编码器来进行MNIST图片分类,自编码器的嵌入维度是2维。自编码器的结构如下图所示。 基于PyTorch的自编码器如下。 (2)下载数据和预处理 (3)自编码器模型 (4)模型训练 输出如下: (5)模型测试 结果如下: 在代码中,编码和解码模块的系数参考本节前面的自编码器结构图。在文件中,生成多次迭代后的图片,解码后的图片像素精度越来越高,逐渐和原图比较类似。 在本节讨论了自编码器进行图片的压缩和恢复。已经探索了如何使用自动解码通过发现数据点的强表征来总结数据集的内容。这种降维机制在数据点比较丰富且包含相关信息时运作良好。下面将讨论使用自编码器进行图片去噪的实例。 本节将介绍一种图像去噪的算法——去噪自编码器。人的视觉机制能够自动的忍受图像的噪声来识别图片。自编码器的目标是要学习一个近似的恒等函数,使得输出近似等于输入。去噪自编码器采用随机的部分带噪输入来解决恒等函数的问题,自编码器能够获得输入的良好表征,该表征使得自编码器能够进行去噪或回复。 基于Autoendecoder的图片去噪步骤如下。 (1)加载库和配置参数 (2)下载图片库训练集 (3)Encoder和Decoder模型设置 (4)Loss函数和优化器 (5)自编码器训练 输出如下: (6)带噪图片和去噪图片的对比 结果如下: 左图是原图,中图是原图加上噪声,右图是将中图去噪。可见,自编码器去噪的效果还是非常不错的。 人类语言的词汇量很大,语言表示的方法有很多种,词嵌入就是最近涌现出来的优秀方法。词嵌入(word enbedding)是自然语言处理中语言模型与表征学习技术的统称。从概念上讲,它是指把一个维数为所有词数的高维空间嵌入到一个维度低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。词嵌入技术可以追溯到2000年约书亚-本希奥在一系列论文中使用了神经概率语言模型使机器习得词语的分布式表征,从而达到将词语空间降维的目的。2013年谷歌一个托马斯-米科洛维领导的团队发明了一套工具Word2Vec来进行词嵌入,向量空间模型的训练速度比以往的方法都快。此后,词嵌入技术在语言模型、文本分类等自然语言处理中流行起来。 目前使用词嵌入技术的流行训练软件有有谷歌的Word2vec、脸书的fasttext和斯坦福大学的GloVe。词向量是目前词嵌入中运用最多的技术。词向量的使用方法大致有两种:一是直接用于神经网络模型的输入层,这个思路在语言模型、机器翻译、文本分类、文本情感分析等应用上广泛使用;二是作为辅助特征扩充现有模型,这个思路在命名实体识别和短语识别上进一步提高了效果。 要对语言进行处理,必须找到方法把词汇符号化。最简单、最直观的方法就是用one-hot向量来表示词。假设词典中不同词的数量为N,每个词可以和从0到N-1的连续整数一一对应。假设一个词的相应整数表示为i,为了得到该词的one-hot向量表示,我们创建一个全0的长度为N的向量,并将其第i位设成1。 我们可以先举三个例子: The cat likes playing ball. 假设使用一个二维向量(a,b)来定义一个词,其中a,b分别代表这个词的一种属性,比如a代表是否喜欢玩飞盘,b代表是否喜欢玩毛线,并且这个数值越大表示越喜欢,这样我们就可以区分这三个词了,为什么呢? 假设,cat的词向量是(-1,4),kitty的词向量是(-2,5),dog的词向量是(3,-2),boy的词向量是(-2,-3)。我们怎么去定义它们之间的相似度呢?我们可以通过它们之间的夹角定义它们之间的相似度(这就是余弦相似度)。 上图显示出了不同的词之间的夹角,我们可以发现kitty和cat是非常相似的,而dog和boy是不相似的。 使用one-hot词向量并不是一个好选择。一个主要的原因是,one-hot词向量无法表达不同词之间的相似度。例如,任何一对词的one-hot向量的余弦相似度都为0。之前做分类问题的时候我们使用one-hot编码,比如一共有5个类,那么属于第2类的话,它的编码就是(0,1,0,0,0)。对于分类问题,这样当然特别简明,但是对于单词,这样做就不行了。比如有1000个不同的词,那么使用one-hot这样的方法效率就很低了,所以必须要使用另外一种方式去定义每一个单词。这就引出了word embedding。2013年,谷歌团队发布了Word2vec工具。Word2vec工具主要包含两个模型:即跳字模型(skip-gram)和连续词袋模型(Continuous Bags of Words,即CBOW),以及两种高效训练的方法,即负采样(negative sampling)和层序Softmax(hierarchical softmax)。值得一提的是,Word2vec词向量可以较好地表达不同词之间的相似和类比关系。Word2vec自提出后被广泛应用在自然语言处理任务中。它的模型和训练方法也启发了很多后续的词向量模型。本节将重点介绍Word2vec的模型和训练方法。 (1)跳字模型 在跳字模型中,我们用一个词来预测它在文本序列周围的词。例如给定文本序列“the”、“man”、“hit”、“his”和“son”。跳字模型所关心的是,给定“hit”,生成它的临近词“the”、“man”、“his”和“son”的概率。在这个例子中,“hit”叫中心词,“the”、“man”、“his”和“son”叫背景词。由于“hit”只生成与它距离不超过2的背景词,因此该时间窗口大小为2。 (2)连续词袋模型 连续词袋模型与跳字模型类似。与跳字模型最大的不同是,连续词袋模型中用一个中心词在文本序列周围的词来预测该中心词。例如给定文本序列“the”、“man”、“hit”、“his”和“son”。连续词袋模型所关心的是,“the”、“man”、“his”和“son”一起生成中心词“hit”的概率。我们可以看到,无论是跳字模型还是连续词袋模型,每一步计算的开销和词典大小相关。当词典较大时,例如几十万到上百万,这种训练方法的计算开销会很大。因此使用上述训练方法在实践中是有难度的。 跳字模型和连续词袋模型如下图所示。 我们将使用近似的方法来计算这些梯度,从而减少计算开销。常用的近似训练方法包括负采样和层序Softmax。 在PyTorch中,词嵌入使用nn.embedding: class torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2, scale_grad_by_freq=False, sparse=False) 参数含义如下: 常用的只有两个参数:num_embeddings和embedding_dim。 词嵌入的简单使用例子如下: 首先把每个单词用一个数字去表示,“hello”用0表示,“PyTorch”用1表示。然后定义Embedding,这里nn.Embedding(2,5)表示有2个单词,每个单词表示成5个维度,其实就是2 * 5的矩阵。注意,这里建立的词向量只是初始的词向量,并没有经过任何修改和优化,我们需要建立神经网络,通过训练修改word embedding中的参数,使得每一个词向量能够表示每一个不同的词。 我们可以查看一下embedding的内容: 输出如下: 这就是输出的“hello”这个词的word embedding。 下面使用PyTorch实现一个基于词向量的语言模型:通过某个单词的前两个单词来预测这个单词。 (1)加载库和设置参数 CONTEXT_SIZE表示想由前面的几个单词来预测这个单词,这里设置为2,就是说希望通过这个单词的前两个单词来预测这个单词。EMBEDDING_DIM表示word embedding的维数。 将句子中切好的单词,每三个分为一组,前两个作为传入的数据,第三个作为预测的结果。并给每个单词编码,以便下面得到embedding的词向量。 该模型需要传入的参数是词典大小vocab_size,词向量维度embedding_dim和预测需要前面几个单词context_size。然后在向前传播中,首先传入单词得到的词向量,比如在该模型中传入两个词,得到的词向量是(2,100),然后将词向量展开成(1,200),接着传入一个线性模型,经过ReLU激活函数再传入一个线性模型,输出的维数是词典大小,可以看成是一个分类问题,要最大化预测单词的概率,最后经过一个log_softmax激活函数。 (5)训练语言模型 输出如下: 进行训练,这里一共跑了1000个批次。在每个epoch中,context1,context2代表预测单词的前面两个单词,target代表要预测的词。然后记住需要将它们转换成Variable,接着进入网络得到结果,最后通过loss函数得到损失,进行反向传播,更新参数。 输出如下: 根据这个例子打印的结果可知:该三元语言模型的错误率近似为0.022,即正确率达到了97.8%,效果还是很不错的。
2.PCA的PyTorch实现
from sklearn import datasets
import torch
import numpy as np
import matplotlib.pyplot as plt
def PCA(data, k=2):
X = torch.from_numpy(data)
X_mean = torch.mean(X, 0)
X = X - X_mean.expand_as(X)
# SVD
U,S,V = torch.svd(torch.t(X))
return torch.mm(X,U[:,:k])
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_pca = PCA(X)
pca = X_pca.numpy()
plt.figure()
color = ['red','green','blue']
for i,target_name in enumerate(iris.target_names):
plt.scatter(pca[y == i, 0], pca[y == i, 1], label=target_name, color=color[i])
plt.legend()
plt.title('PCA of IRIS dataset')
plt.show()

2.自编码器
1.自编码器原理

2.自编码器的PyTorch实现
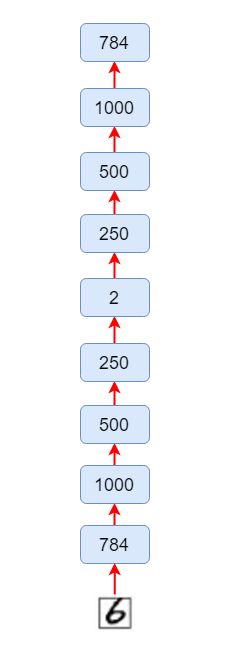
(1)加载库和配置参数import os
import pdb
import torch
import torchvision
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
from torchvision.utils import save_image
from torchvision import datasets
import matplotlib.pyplot as plt
torch.manual_seed(1)
batch_size = 128
learning_rate = 1e-2
num_epochs = 10
train_dataset = datasets.MNIST(root='./data',train=True,transform=transforms.ToTensor(),download=True)
test_dataset = datasets.MNIST(root='./data',train=False,transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=10000,shuffle=False)
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder,self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28,1000),
nn.ReLU(True),
nn.Linear(1000,500),
nn.ReLU(True),
nn.Linear(500,250),
nn.ReLU(True),
nn.Linear(250,2)
)
self.decoder = nn.Sequential(
nn.Linear(2,250),
nn.ReLU(True),
nn.Linear(250,500),
nn.ReLU(True),
nn.Linear(500,1000),
nn.ReLU(True),
nn.Linear(1000,28*28),
nn.Tanh()
)
def forward(self,x):
x = self.encoder(x)
x = self.decoder(x)
return x
model = autoencoder()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate,weight_decay=1e-5)
for epoch in range(num_epochs):
for data in train_loader:
img,_ = data
img = img.view(img.size(0),-1)
img = Variable(img)
output = model(img)
loss = criterion(output,img)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('epoch [{}/{}], loss: {:.4f}'.format(epoch+1,num_epochs,loss))
epoch [1/10], loss: 0.0461
epoch [2/10], loss: 0.0449
epoch [3/10], loss: 0.0432
epoch [4/10], loss: 0.0385
epoch [5/10], loss: 0.0428
epoch [6/10], loss: 0.0432
epoch [7/10], loss: 0.0401
epoch [8/10], loss: 0.0426
epoch [9/10], loss: 0.0418
epoch [10/10], loss: 0.0461
model.eval()
eval_loss = 0
with torch.no_grad():
for data in test_loader:
img, label = data
img = img.view(img.size(0),-1)
img = Variable(img)
label = Variable(label)
out = model(img)
y = label.data.numpy()
plt.scatter(out[:,0],out[:,1],c=y)
plt.colorbar()
plt.title('autocoder of MNIST test dataset')
plt.show()

3.基于自编码器的图像去噪
import numpy as np
import torch
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
import torchvision
from torchvision import utils
from torchvision import datasets
from torchvision import transforms
import matplotlib.pyplot as plt
torch.manual_seed(1)
batch_size = 200
learning_rate = 1e-4
num_epochs = 20
train_dataset = datasets.MNIST(root='./data',train=True,transform=transforms.ToTensor(),target_transform=None,download=True)
test_dataset = datasets.MNIST(root='./data',train=False,transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=10000,shuffle=False)
class Encoder(nn.Module):
def __init__(self):
super(Encoder,self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1,32,3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.Conv2d(32,32,3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.Conv2d(32,64,3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64,64,3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(2,2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(64,128,3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128,128,3,padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(2,2),
nn.Conv2d(128,256,3,padding=1),
nn.ReLU()
)
def forward(self,x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(batch_size,-1)
return out
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(256,128,3,2,1,1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128,128,3,1,1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128,64,3,1,1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64,64,3,1,1),
nn.ReLU(),
nn.BatchNorm2d(64)
)
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(64,32,3,1,1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.ConvTranspose2d(32,32,3,1,1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.ConvTranspose2d(32,1,3,2,1,1),
nn.ReLU()
)
def forward(self,x):
out = x.view(batch_size,256,7,7)
out = self.layer1(out)
out = self.layer2(out)
return out
encoder = Encoder().cuda()
decoder = Decoder().cuda()
parameters = list(encoder.parameters()) + list(decoder.parameters())
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(params=parameters,lr=learning_rate)
noise = torch.rand(batch_size,1,28,28)
for epoch in range(num_epochs):
for image,label in train_loader:
image_n = torch.mul(image+0.25,0.1*noise)
image = Variable(image).cuda()
image_n = Variable(image_n).cuda()
optimizer.zero_grad()
output = encoder(image_n)
output = decoder(output)
loss = loss_func(output,image)
loss.backward()
optimizer.step()
print('epoch [{}/{}], loss: {:.4f}'.format(epoch+1, num_epochs,loss.item()))
epoch [1/20], loss: 0.0123
epoch [2/20], loss: 0.0098
epoch [3/20], loss: 0.0090
epoch [4/20], loss: 0.0082
epoch [5/20], loss: 0.0076
epoch [6/20], loss: 0.0071
epoch [7/20], loss: 0.0068
epoch [8/20], loss: 0.0066
epoch [9/20], loss: 0.0063
epoch [10/20], loss: 0.0065
epoch [11/20], loss: 0.0063
epoch [12/20], loss: 0.0058
epoch [13/20], loss: 0.0056
epoch [14/20], loss: 0.0053
epoch [15/20], loss: 0.0052
epoch [16/20], loss: 0.0050
epoch [17/20], loss: 0.0051
epoch [18/20], loss: 0.0047
epoch [19/20], loss: 0.0045
epoch [20/20], loss: 0.0048
img = image[0].cpu()
input_img = image_n[0].cpu()
output_img = output[0].cpu()
origin = img.data.numpy()
inp = input_img.data.numpy()
out = output_img.data.numpy()
plt.figure('denoising autoencoder')
plt.subplot(1,3,1)
plt.imshow(origin[0],cmap='gray')
plt.subplot(1,3,2)
plt.imshow(inp[0],cmap='gray')
plt.subplot(1,3,3)
plt.imshow(out[0],cmap='gray')
plt.show()
print(label[0])
tensor(4)

3.词嵌入
1.词嵌入原理
The kitty likes playing wool.
The dog likes playing ball.
The boy likes playing ball.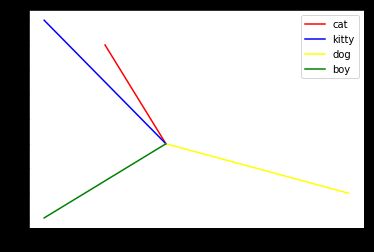
import torch
import torch.nn as nn
import torch.autograd as autograd
word_to_idx = {"hello":0, "PyTorch":1}
embeds = nn.Embedding(2,5)
lookup_tensor = torch.LongTensor([word_to_idx["PyTorch"]])
hello_embed = embeds(autograd.Variable(lookup_tensor))
print(hello_embed)
tensor([[-0.7846, -0.1158, -1.5107, -1.2108, -0.2174]],
grad_fn=2.基于词向量的语言模型的PyTorch实现
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
CONTEXT_SIZE = 2
EMBEDDING_DIM = 10
N_EPHCNS = 1000
(2)数据准备# 语料
test_sentence = """Word embeddings are dense vectors of real numbers, one per word in your vocabulary.
IN NLP, it is almost always the case that your features are words! But how should you represent a word
in a computer? You could store its ascii character representation, but that only tells you what the word
is, it doesn't say much about what it means (you might be able to derive its part of speech from its
affiex, or propertites from its capitalization, but not much). Even more, in what sense could you combine
these representations?""".split()
# 三元模型
trigrams = [([test_sentence[i],test_sentence[i+1],test_sentence[i+2]]) for i in range(len(test_sentence)-2)]
# 词典
vocab = set(test_sentence)
word_to_idx = {word:i for i,word in enumerate(vocab)}
idx_to_word = {i:word for i,word in enumerate(vocab)}
(3)语言模型class NGramLanguageModeler(nn.Module):
def __init__(self,vocab_size,embedding_dim,context_size):
super(NGramLanguageModeler,self).__init__()
self.embeddings = nn.Embedding(vocab_size,embedding_dim)
self.linear1 = nn.Linear(context_size * embedding_dim, 128)
self.linear2 = nn.Linear(128,vocab_size)
def forward(self,inputs):
embeds = self.embeddings(inputs).view((1,-1))
out = F.relu(self.linear1(embeds))
out = self.linear2(out)
log_probs = F.log_softmax(out,dim=len(out))
return log_probs
(4)损失函数和优化器losses = []
loss_function = nn.NLLLoss()
model = NGramLanguageModeler(len(vocab),EMBEDDING_DIM,CONTEXT_SIZE)
optimizer = optim.SGD(model.parameters(),lr=0.001)
for epoch in range(N_EPHCNS):
total_loss = torch.Tensor([0])
for context1,context2,target in trigrams:
# 得到词向量
context_idxs = [word_to_idx[context1],word_to_idx[context2]]
context_var = autograd.Variable(torch.LongTensor(context_idxs))
# 梯度初始化
model.zero_grad()
# 前向传播
log_probs = model(context_var)
# 计算损失
loss = loss_function(log_probs,autograd.Variable(torch.LongTensor([word_to_idx[target]])))
# 后向传播
loss.backward()
# 更新梯度
optimizer.step()
# 累计损失
total_loss += loss.data
print('\r epoch[{}] - loss: {:.6f}'.format(epoch,total_loss[0]))
epoch[0] - loss: 384.948334
epoch[1] - loss: 383.013763
epoch[2] - loss: 381.093689
epoch[3] - loss: 379.185699
epoch[4] - loss: 377.290375
epoch[5] - loss: 375.404846
epoch[6] - loss: 373.529083
epoch[7] - loss: 371.662842
epoch[8] - loss: 369.805328
epoch[9] - loss: 367.956299
epoch[10] - loss: 366.113464
……
epoch[990] - loss: 5.137405
epoch[991] - loss: 5.133943
epoch[992] - loss: 5.130613
epoch[993] - loss: 5.127238
epoch[994] - loss: 5.123822
epoch[995] - loss: 5.120545
epoch[996] - loss: 5.117153
epoch[997] - loss: 5.113895
epoch[998] - loss: 5.110688
epoch[999] - loss: 5.107241
(6)预测结果errors = 0
for i in range(len(trigrams)):
word1,word2,label = trigrams[i]
words = autograd.Variable(torch.LongTensor([word_to_idx[word1],word_to_idx[word2]]))
out = model(words)
_,predict_label = torch.max(out,1)
predict_word = idx_to_word[predict_label.item()]
if label != predict_word:
errors += 1
print("real word is '{}', predict word is '{}'".format(label,predict_word))
print("error rate is {}/{} = {:.6f}".format(errors, len(trigrams),errors/len(trigrams)))
real word is 'are', predict word is 'are'
real word is 'dense', predict word is 'dense'
real word is 'vectors', predict word is 'vectors'
real word is 'of', predict word is 'of'
real word is 'real', predict word is 'real'
real word is 'numbers,', predict word is 'numbers,'
real word is 'one', predict word is 'one'
real word is 'per', predict word is 'per'
real word is 'word', predict word is 'word'
real word is 'in', predict word is 'in'
real word is 'your', predict word is 'a'
real word is 'vocabulary.', predict word is 'vocabulary.'
real word is 'IN', predict word is 'IN'
real word is 'NLP,', predict word is 'NLP,'
real word is 'it', predict word is 'it'
real word is 'is', predict word is 'is'
real word is 'almost', predict word is 'almost'
real word is 'always', predict word is 'always'
real word is 'the', predict word is 'the'
real word is 'case', predict word is 'case'
real word is 'that', predict word is 'that'
real word is 'your', predict word is 'your'
real word is 'features', predict word is 'features'
real word is 'are', predict word is 'are'
real word is 'words!', predict word is 'words!'
real word is 'But', predict word is 'But'
real word is 'how', predict word is 'how'
real word is 'should', predict word is 'should'
real word is 'you', predict word is 'you'
real word is 'represent', predict word is 'represent'
real word is 'a', predict word is 'a'
real word is 'word', predict word is 'word'
real word is 'in', predict word is 'in'
real word is 'a', predict word is 'a'
real word is 'computer?', predict word is 'computer?'
real word is 'You', predict word is 'You'
real word is 'could', predict word is 'could'
real word is 'store', predict word is 'store'
real word is 'its', predict word is 'its'
real word is 'ascii', predict word is 'ascii'
real word is 'character', predict word is 'character'
real word is 'representation,', predict word is 'representation,'
real word is 'but', predict word is 'but'
real word is 'that', predict word is 'that'
real word is 'only', predict word is 'only'
real word is 'tells', predict word is 'tells'
real word is 'you', predict word is 'you'
real word is 'what', predict word is 'what'
real word is 'the', predict word is 'the'
real word is 'word', predict word is 'word'
real word is 'is,', predict word is 'is,'
real word is 'it', predict word is 'it'
real word is 'doesn't', predict word is 'doesn't'
real word is 'say', predict word is 'say'
real word is 'much', predict word is 'much'
real word is 'about', predict word is 'about'
real word is 'what', predict word is 'what'
real word is 'it', predict word is 'it'
real word is 'means', predict word is 'means'
real word is '(you', predict word is '(you'
real word is 'might', predict word is 'might'
real word is 'be', predict word is 'be'
real word is 'able', predict word is 'able'
real word is 'to', predict word is 'to'
real word is 'derive', predict word is 'derive'
real word is 'its', predict word is 'its'
real word is 'part', predict word is 'part'
real word is 'of', predict word is 'of'
real word is 'speech', predict word is 'speech'
real word is 'from', predict word is 'from'
real word is 'its', predict word is 'its'
real word is 'affiex,', predict word is 'capitalization,'
real word is 'or', predict word is 'or'
real word is 'propertites', predict word is 'propertites'
real word is 'from', predict word is 'from'
real word is 'its', predict word is 'its'
real word is 'capitalization,', predict word is 'capitalization,'
real word is 'but', predict word is 'but'
real word is 'not', predict word is 'not'
real word is 'much).', predict word is 'much).'
real word is 'Even', predict word is 'Even'
real word is 'more,', predict word is 'more,'
real word is 'in', predict word is 'in'
real word is 'what', predict word is 'what'
real word is 'sense', predict word is 'sense'
real word is 'could', predict word is 'could'
real word is 'you', predict word is 'you'
real word is 'combine', predict word is 'combine'
real word is 'these', predict word is 'these'
real word is 'representations?', predict word is 'representations?'
error rate is 2/90 = 0.022222