MVCNN:利用二维多视角的3D识别
Highlights
用物体的三维数据从不同“视角”所得到的二维渲染图,作为原始的训练数据。用经典、成熟的二维图像卷积网络进行训练,训练出的模型,对三维物体的识别、分类效果之好,比那些用三维数据直接训练出的模型好很多。
Critical Review
Introduction
由于之前人们很少能够接触到直接的三维物体特征,所以一直以来在计算机视觉中研究者大多是使用3维图像的2维特征来进行识别等操作。随着技术的发展,虽然有一些公开的3维库但是数量有限。本文推出了一种看起来“很不靠谱”的方法,即通过2D图片的渲染来生成一个3D图片分类器,并且效果可以显著的超过直接使用3D图片进行分类的模型,这是因为通过2D可以利用大量的现有image description和databases。值得一提的是,作者特意着重强调了dramatically outperform这个词,可见其对自己的工作还是很有信心的。

文中还提到“抖动”这一方法,在这里可以理解为我们在进行训练前的数据增强,比如旋转、缩放、对称映射和平移等操作,这样可以获得更多的数据,也可以使得模型自动的去学习要识别物体的变换不变性。
从上图我们也可以得知,最后的模型需要融合12个视角的数据来综合判断,那么如何融合就成为了模型的关键。这里作者尝试了使用combine方式和之前常用的averageing方式,实验结果表明前者效果更加优异。其实从现在来说,这是肯定的,因为我们现在较常用的分割网络UNet就是采用combine的方式来结合的,而不是简单地相加平均。
Method
Input: A Multi-view Representation
对于形状描述算子等相关知识在这里就不做介绍,我们重点来看一下本文所采用的具体方法。
本文的工作中面对的主要问题是:
- 作者研究的这个Multi-view based三维形状描述算子,目前研究较少
- 在将同一件三维形状的不同视角下的图,结合起来提取三维形状描述算子的具体结合方法
对此,作者提出了一个叫做“view-pooling layer”的结构,经过实验,发现三维形状数据经过多视角的图结合,经过CNN网络训练后,能够提取到单一、简单的形状描述算子。
这里需要说明的是,上图中的相机并不是真正的相机,而是“虚拟相机”。在真实工作中,是以虚拟引擎渲染出12个不同视角的。而为了产生3D形状的多视角渲染图,我们需要设定一个“视角”(虚拟相机)来产生网格的渲染图。
文中试验了两种视角初始化。
- 假设输入的3D形状是按照一个恒定的轴(Z-轴)正直的摆放的。这种情况下,物体被12个“虚拟相机”包围,也就是每隔30度,产生一个2D视角渲染图。而且在相机工作时,是与水平面有30度的水平角的,且径直指向3D网格数据的中心。
- 此时假设3D形状不沿着恒定的Z轴放置。此时物体的形状会更加显得不规则,所以需要更多的视角来确定。文中采用的是围绕物体生成20面体,然后放置20个虚拟相机,每个虚拟相机通过旋转0、90、180和270度来获得4个视角的数据,因此总共可以获得80个视角的数据。
同时作者注意到,使用不同的阴影系数或光照模型并不会影响我们的输出描述算子,因为学习到的滤波器对光照变化的不变性。
Recognition with Multi-view Representations
本文中使用的CNN是基于VGG-M的变种,网络结构主要为:5个卷积层,3个全连接层,最后通过一个Softmax进行分类。其中倒数第二层被用作图像描述算子。整个网络先在ImageNet图像集上进行预训练(这里2D的好处就体现出来了,利用规模更大的数据集帮助加快特征学习和收敛),之后用之前采集到的多视角图像进行微调。实验表明,微调能够显著的改善性能。相比较于当时比较流行的3D形状描述算子(如:SPH、LFD)以及3D ShapeNets,CNN在分类与检索任务上都能够取得更优异的表现。
在分类部分,文章使用了线性核SVM,一对多的方式去结合图像特征分类3D形状。在测试阶段,文章使用的是取特征值最大的那个
作为最后的分类,同时作者也尝试了取平均特征值但是效果不好。
检索任务需要定义一种距离、相似度的度量方式。对于3D形状 X X X,其图像描述子为: n x n_x nx,对于3D形状 Y Y Y,其图像描述子为: n y n_y ny,这两者之间的“距离”定义如下式。注意,两者之间的距离度量是用它们的特征向量的 l 2 l_2 l2距离定义来计算的,例如 ∣ ∣ x i − y j ∣ ∣ 2 ||x_i−y_j||_2 ∣∣xi−yj∣∣2。
d ( x , y ) = ∑ j m i n i ∣ ∣ x i − y i ∣ ∣ 2 2 n y + ∑ i m i n j ∣ ∣ x i − y i ∣ ∣ 2 2 n x d(x, y) =\frac{\sum _{j}min_i||x_i-y_i||_2}{2n_y} + \frac{\sum _{i}min_j||x_i-y_i||_2}{2n_x} d(x,y)=2ny∑jmini∣∣xi−yi∣∣2+2nx∑iminj∣∣xi−yi∣∣2
虽然对于3D形状,上面的多重的描述子相比较于现存的3D形状特征描述子,效果要好,但是在许多情况下,这种算法是低效的。因为在上式中,我们要衡量两个3D形状之间的距离,需要计算 n x ∗ n y n_x*n_y nx∗ny个距离(在3D形状对应的视角2D图像下计算),这本身需要大量的计算。
如前面所说,简单的求一个3D形状的多视角图像的特征描述子的平均值,或者简单的将这些特征描述子做“连接”(这地方可以想象成将特征简单的“串联”),会导致不好的效果。所以在这一部分,作者集中于融合多视角2D图像产生的特征,以便综合这些信息,形成一个简单、高效的3D形状描述子。
因此,作者设计了Multi-view CNN(MVCNN),放在基础的2D图像CNN之中。如图一所示,同一个3D形状的 每一张视角图像各自独立地经过第一段的CNN1卷积网络,在一个叫做View-pooling层进行“聚合”。之后,再送入剩下的CNN2卷积网络。整张网络第一部分的所有分支,共享相同的 CNN1里的参数。在View-pooling层中,逐元素取最大值操作。实际上这个View-pooling层,可以放在网络中的任何位置。经过作者的实验,这一层最好放在最后的卷积层(Conv5),以最优化的执行分类与检索的任务。
View-pooling优点类似于max-pooling layer与maxout layer,不同点在于进行max操作时的维度不同。这里应该指的是普通MaxPooling是在一个图像的像素矩阵上进行的,是在二维上的一个操作,而这里的ViewPooling应该是对于三维的一个取最大值操作,因为有12个视角的数据所以应该是在这12个视角上取某一块的最大值作为特征。
在MVCNN中,用倒数第二作为一种聚合的3D形状特征描述符,得到了比用基础的CNN卷积网络从单独的图像中提取到的图像描述符,有更好表现的描述符,特别是在检索实验中,从62.8%提高到了70.1%.这种描述符可以直接用来进行其他3D形状的任务了,如分类、检索。
文章使用了普林斯顿大学的ModelNet40数据集作为验证数据集,其包含40种共12311个3D的CAD模型。具体的数据比较见下图:

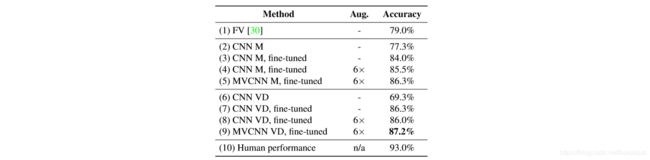
在文章最后,作者进一步扩展了MVCNN的应用场景,既然它在3D物体的不同视角下拥有很好的准确率,那么是否可以将其扩展到2D?聚合一个2D图像的多个视图是否也可以提高性能?作者采用了人类素描集作为测试数据集,利用现成的VGG-M,可以得到77.3%的分类精度,无需任何网络微调。通过对训练集的微调,可以进一步提高训练精度至84.0%,显著超过其他传统方法。通过更深入的网络结构(VGG-VD,含有16层网络),获得了87.2%的准确率,进一步提高了分类性能,并且接近人类的分辨精度。具体测试结果见下图。
讨论
本文其实其实还有更多的idea可以继续做下去,比如在多视角的2D图像表示3D特征时,哪一张视角图像是最重要的?是否可以根据权重来找出是哪一个视角影响了最后的分类?或者说哪一张图像包含了主要的特征信息?多少张视角图像可以满足给定的精度要求?
另一个重要的问题就是,本文的实验都是在“虚拟的”3D形状上的,那么,这篇文章提出的MVCNN能够对于真实世界的3D物体(或者视频、而不仅仅是3D多边形网格模型),也能够建立简洁的特征描述子吗?这类问题研究清楚了,MVCNN才能运用于实际问题,如现实中广泛使用的物体识别与人脸识别技术。
参考文献
- 本文参考了这篇博客
- 本文讨论文章
- 本文讨论文章的代码