前言
流式计算对稳定性敏感,所以我们在编写作业时一定会做好防御性编程,如各种判空、边界条件、安全的类型转换、格式判断、异常捕获等。但是墨菲定律说得好:
Anything that can go wrong will go wrong.
换言之,我们写再多的防御性代码,也无法覆盖所有非法数据的可能性,何况外部环境(网络、磁盘等)也会出现不可预知的波动,所以作业在遇到意外情况时最好能自己“复活”,而不是每次都要靠人工手动拉起来。针对这个问题,Flink提供了重启策略(restart strategy)使Job从最近一次checkpoint自动恢复现场。本文先简要介绍一下3种Job重启策略。
Job重启策略
固定延时重启(fixed-delay)
flink-conf.yaml中的配置:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 10
restart-strategy.fixed-delay.delay: 15s
或者在代码里对每个Job进行配置,优先级比flink-conf.yaml高:
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
10, // attempts
Time.seconds(15) // delay
));
在Flink Job失败时,该策略按照restart-strategy.fixed-delay.delay参数给出的固定间隔试图重启Job。如果重启次数达到restart-strategy.fixed-delay.attempts参数规定的阈值之后还没有成功,就停止Job。
若我们的Job中启用了检查点机制,并且没有对重启策略做任何设置的话,Flink就会fallback到此策略,但是同时会将重启次数设定为Integer.MAX_VALUE,间隔为10秒。带来的风险是如果Job始终无法恢复,就会无限重试,造成长时间不可用以及日志泛滥(之前在Flink社区群内见到过,如下图)。

所以,当启用检查点时,最好手动设定重启策略的参数。
按失败率重启(failure-rate)
flink-conf.yaml中的配置:
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 10
restart-strategy.failure-rate.failure-rate-interval: 300s
restart-strategy.failure-rate.delay: 15s
或者在代码里对每个Job进行配置:
env.setRestartStrategy(RestartStrategies.failureRateRestart(
10, // max-failures-per-interval
Time.minutes(5), // failure-rate-interval
Time.seconds(15) // delay
));
在Flink Job失败时,该策略按照restart-strategy.failure-rate.delay参数给出的固定间隔试图重启Job。如果重启次数在restart-strategy.failure-rate.failure-rate-interval的时间周期内达到restart-strategy.failure-rate.max-failures-per-interval参数规定的阈值之后还没有成功,就停止Job。
如果启用了failure-rate重启策略,但没设定参数的话,Flink默认会将3个参数的值分别设定为1次、1分钟和akka.ask.timeout参数指定的超时时间。
无重启(none)
顾名思义,Job出现意外时直接失败。配置方法分别如下:
restart-strategy: none
env.setRestartStrategy(RestartStrategies.noRestart());
当Job内没有启用检查点机制并没有设置重启策略的话,默认会fallback到此策略。
三种Job重启策略说完了。当然,只有它是不够的,还得配合适当的作业监控来为我们提供异常告警,以便及时提醒我们进行检查。笔者不是专业负责监控系统的,就不班门弄斧了。
Flink Job的细粒度组成是Task,Job的失败与重启总是可以追溯到Task级别,所以下面我们来看看Task恢复策略。
Task恢复策略
官方为了与Job重启做区分,将Task的重启策略叫做故障恢复策略(failover strategy),简单的介绍见文档。它由flink-conf.yaml中的jobmanager.execution.failover-strategy参数指定,有两个可选项:
- full:重启Job中所有的Task,即重置整个ExecutionGraph,简单粗暴。
- region:只重启ExecutionGraph中对应的Region包含的Task,更加智能,降低overhead。
full策略没什么好说的,下面我们根据FLIP-1(Fine Grained Recovery from Task Failures)中给出的设计思想简单分析一下region策略。
根据图论知识,如果我们的ExecutionGraph是一个非连通图(即可以划分为多个独立的依赖pipeline),那么当某个Task失败时,就可以只回溯到该Task所在的连通分量的Source,并重启该连通分量涉及到的所有Task,而其他Task不受影响,如下图所示。此时一个连通分量就是一个Region。
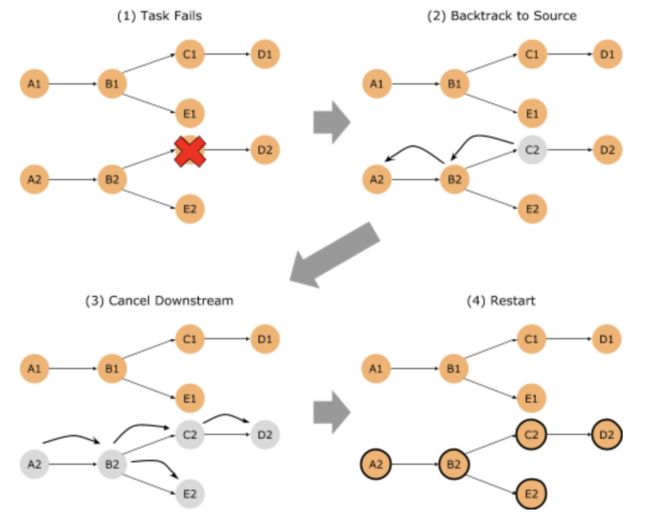
这个思路很容易理解,但是对于ExecutionGraph本身就是连通图的情况就不高效了,因为还是要重启所有Task,如下图所示。
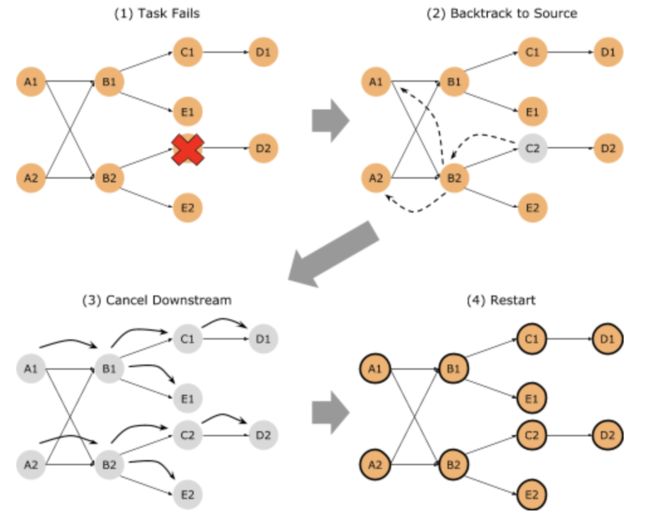
所以Flink对这种情况又做了一个优化:在发生一对多依赖的Task后面缓存计算出来的中间结果(intermediate result)。当下游的Task失败重启时,就可以不必回溯到Source,而是回溯到中间结果就行了,重启的Task数进一步减少。此时从中间结果缓存起计的所有下游Task形成一个Region。用语言描述可能有些不直观,一张图就能说明白了。

当然,如果是靠近Source一端的Task出了问题,或者中间结果缓存失效,这种方法就行不通了,老老实实从Source重启吧。
篇幅所限(其实是笔者犯懒),本文就不再分析源码了。Job重启策略的相关源码在o.a.f.runtime.executiongraph.restart包,Task重启策略的相关源码在o.a.f.runtime.executiongraph.failover包,看官可以自行找来阅读。
The End
民那晚安咯。