
声明:沃贝签到网站已经在10月初归西, 但技术是不过时的哦。
前言叨B叨
我不知道有多少同学知道沃贝,用联通的同学也不见得都知道, 因为我也是后来别人科普给我才知道联通旗下有这么个网站, 每天签到,一个月到头可以得950M流量. 对于我这种14块月租套餐的用户来说,还是很不错的福利. 但是, 问题来了, 每天签到, 很烦躁的说, 于是就想着做个自动签到, 顺便以 python 机器学习 的名义, 废话路上说, 来不及了, 快上车!
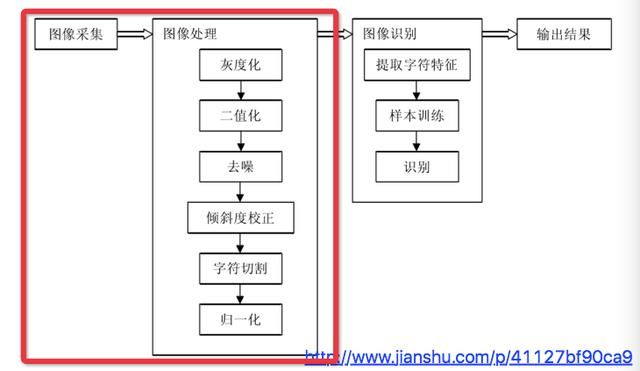
如下图所示, 验证码识别一般分为如下几个步骤, 今天我们主要说下红框部分, 图像采集和处理.
一. 采集图像
先去到网站上的登录窗口, 找到二维码的地址, 然后写个循环把图片下载下来做样本, 多多益善,我这只下了50张.
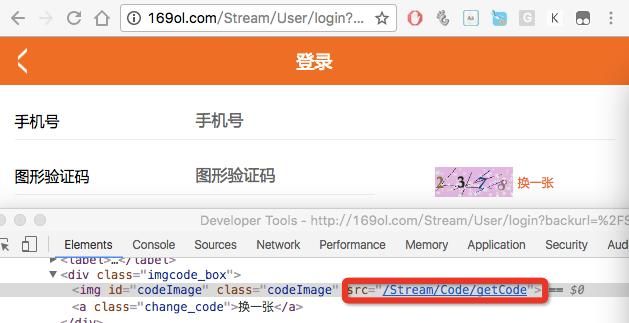

在截图中可以看到, 这个验证码还不是个一般的验证码, 是个二般的. 特征为: 纯数字, 字体有旋转, 背景有杂色, 还有干扰线. 所有这些特征, 除了纯数字以外, 全部是来阻止程序自动识别的绊脚石. 接下来, 我们就来一步一步地扫清障碍, 还我4个清纯的数字s.
二.图像处理
处理图像之前, 先把pillow装上:
pip install pillow
2. 首先来灰度化,二值化, 就是把背景杂色过滤掉变得非黑即白.这里的阈值设置的是170, 可根据不同的验证码设置不同的值.
然后图像会变成这样:

3. 接下来去噪. 这个去噪不比ps里, 用橡皮擦擦就没了, 里面还是有些门道(算法)的. 比如[邻域像素算法]:
即对于像素值>245的邻域像素,判别为属于背景色,如果一个像素上下左右4各像素值有超过2个像素属于背景色,那么该像素就是噪声。这里还需要考虑到边界问题.
去噪后, 效果如下图. 对于以上邻域算法仅仅是针对像素为1的干扰线, 对于像素大于一的干扰线没做处理. 不过这个对于机器学习的话问题不大, 因为我们最后生成的样本会有很多种类, 然后让程序去推测当前识别的对象的可信度.

4. 接下来应该是切割验证码(开始那个流程图感觉不太对, 应该是先分割后再校正倾斜度)
切割验证码用的是投影算法, 即坐标从上到下, 从左到右遍历, 如果发现是空白,就跳过,直到扫描到像素值为255的点,开始输出, 输出到纵坐标上没有像素值为255的点,如下图所示:
相关代码呢, 太长了, 贴上来估计你也不愿意看. 我在后面把所有代码上传到GitHub(地址附在文章底部), 大家有兴趣就down下来研究研究.
5. 校正倾斜度, 然后重新调整大小. 校正倾斜度这里用的是旋转卡壳算法, 如下图所示, 当两条平行线之间的举例最短的时候, 就认为是字符正确的方向.

代码如下:

这里在旋转的时候是从-60度到60度, 是依据当前验证码倾斜规律设定的. 调整完后效果如图. 可以发现有些字符并不是很正, 但是将就吧

其实如果是用机器学习的去识别字符的话, 校正倾斜度可做可不做, 因为机器学习是靠大量样本来对比识别的, 如果你的歪歪扭扭的样本足够多, 一样可以识别.
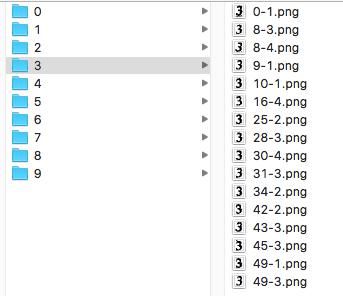
6. 归一化. 把以上的几个步骤写到一个循环里, 跑他个N遍, 这时候, 我们就有了好多好多的数字图片, 这时苦力活来了...我们需要将每张数字图片归类, 在本地创建0-9十个文件夹, 将数字图片按显示值放入相应的文件夹里.
其实这里在我们校正倾斜度的时候可以先使用tesseract先识别一下数字, 然后将其存放在相应文件夹里, 这样可以减轻一部分工作量, 但是有时候识别的不准确,或者是无法识别, 所以还得我们手工去检查一下.
pip install pytessearct
Pytessearct说明:
a、Python-tesseract是一个基于google's Tesseract-OCR的独立封装包;
b、Python-tesseract功能是识别图片文件中文字,并作为返回参数返回识别结果;
c、Python-tesseract默认支持tiff、bmp格式图片,只有在安装PIL之后,才能支持jpeg、gif、png等其他图片格式;
使用如下python 语句识别字符后,存入对应文件夹
recNum = pytesseract.image_to_string(cur_img,config='-psm 10 outputbase digits')
最后整理完揍是这个样子
结语
至此, 识别验证码的第一部分港完了, 得到了一堆小小的数字图片.
后面将会进一步讲讲验证码识别部分. 敬请期待.
说好的GitHub链接
https://github.com/shark526/WowSign
参考链接:
