基于maskrcnn_benchmark框架的Faster RCNN实现(3)
环境 ubantu16.04+cudnn7.0+cuda_9.0.176
Pytorch1.0+python3.6.5+ anaconda3
一、数据准备:
1、 我一般使用的是Pascal voc风格的数据集,当用COCO数据集风格时需要做转化。
首先把数据集分为train和val两类分别用以下代码生成instances_train2014.json和instances_val2014.json
把XML文件转化成json文件的python代码:
见博客:
https://blog.csdn.net/yx868yx/article/details/105557105
2、数据集文件夹的形式为:
为了方便继续沿用了COCO数据集默认的名字instances_train2014.json和instances_val2014.json
| annotations放置instances_train2014.json和instances_val2014.json | ||
|---|---|---|
| datasets | coco | train2014放置训练的图片 |
| val2014放置验证图片 |
3、 数据集文件夹名称和路径都可以通过maskrcnn-benchmark-master-ap/maskrcnn_benchmark/config/paths_catalog.py来修改,训练之前一定要检查数据路径是否正确。

二、训练
1、编译
下载工程:
https://github.com/facebookresearch/maskrcnn-benchmark
$ python setup.py build develop
2、修改配置文件
新建experiment文件夹 存放cfg和result
模型配置文件:
提取configs/e2e_faster_rcnn_R_50_FPN_1x.yaml
e2e_faster_rcnn_R_50_FPN_1x.yaml文件:
MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
WEIGHT: "catalog://ImageNetPretrained/MSRA/R-50"
#可以新建个weights文件夹,存放预训练模型R-50.pkl,此处修改为
#WEIGHT: "maskrcnn-benchmark-master-ap/weights/R-50.pkl"
BACKBONE:
CONV_BODY: "R-50-FPN"
RESNETS:
BACKBONE_OUT_CHANNELS: 256
RPN:
USE_FPN: True #是否使用FPN,也就是特征金字塔结构,选择True将在不同的特征图提取候选区域
ANCHOR_STRIDE: (4, 8, 16, 32, 64)# anchor的步长
PRE_NMS_TOP_N_TRAIN: 2000 #训练中nms之前的候选区的数量
PRE_NMS_TOP_N_TEST: 1000 #测试时,nms之后的候选框数量
POST_NMS_TOP_N_TEST: 1000
FPN_POST_NMS_TOP_N_TEST: 1000
ROI_HEADS:
USE_FPN: True
ROI_BOX_HEAD:
POOLER_RESOLUTION: 7
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
POOLER_SAMPLING_RATIO: 2
FEATURE_EXTRACTOR: "FPN2MLPFeatureExtractor"
PREDICTOR: "FPNPredictor"
DATASETS:
TRAIN: ("coco_2014_train", )#训练的数据文件
TEST: ("coco_2014_val",)#测试的数据文件,和paths_catalog.py中DATASETS相对应
DATALOADER:
SIZE_DIVISIBILITY: 32
SOLVER:
BASE_LR: 0.02 #起始学习率,学习率的调整有多种策略,訪框架自定义了一种策略
WEIGHT_DECAY: 0.0001
STEPS: (5000, 8000)
MAX_ITER: 10000
OUTPUT_DIR : /home/yuxin/maskrcnn-benchmark-master-ap/experiment/result #设置的输出目录
3、修改 MaskRCNN-Benchmark框架配置文件:
maskrcnn_benchmark-master-ap/config/defaults.py
①使用预训练模型需要修改部分代码,主要由于自己的数据集类别和预训练的81类对不上。
_C.MODEL.ROI_BOX_HEAD.NUM_CLASSES修改为自己的数据集类别加1
②_C.SOLVER.CHECKPOINT_PERIOD修改为10000(可选),设置大点是为了减少保存的模型数
③MODEL.RPN.FPN_POST_NMS_TOP_N_TRAIN 2000
这里的2000是每个batch在NMS之后选取2000个锚框,而不是每张图片选取2000个,这个参数的设置规则:1000 × images_per_GPU。
通常来说这个是不用更改的,我们只需要根据自己的GPU数量设置
_C.SOLVER.IMS_PER_BATCH = 16 (16是2×8),即有8个GPU
_C.TEST.IMS_PER_BATCH = 8 (1×8)
④调整图片大小图片太大会训练不起来,报错OOM
_C.INPUT.MIN_SIZE_TRAIN = 480 #训练集图片最小尺寸
_C.INPUT.MAX_SIZE_TRAIN = 800 #训练集图片最大尺寸
_C.INPUT.MIN_SIZE_TEST = 480
_C.INPUT.MAX_SIZE_TEST = 800
⑤ _C.OUTPUT_DIR = “output” #主要作为checkpoint和inference的输出目录 (当没有在配置文件中设置目录时默认会读取output文件夹作为输出)4、在demo文件中更改predictor.py为自己的类别(背景类加预测类)如果不修改,也可以训练测试,但是结果显示出来的标签将会是coco数据集中对应的标签。

我修改的类别:背景类+apple
class COCODemo(object):
# COCO categories for pretty print
CATEGORIES = [
"__background",
"apple"
]
5、开始训练
$ python tools/train_net.py --config-file experiment/cfg/e2e_faster_rcnn_R_50_FPN_1x.yaml
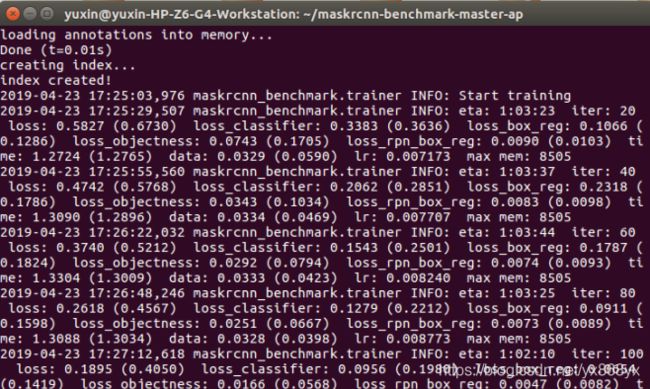
三、验证结果
$ python tools/test_net.py --config-file experiment/cfg/e2e_faster_rcnn_R_50_FPN_1x.yaml

四、验证demo结果:
修改webcam.py代码:
#!--*-- coding:utf-8 --*--
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import requests
from io import BytesIO
from PIL import Image
import numpy as np
pylab.rcParams['figure.figsize'] = 20, 12
from maskrcnn_benchmark.config import cfg
from predictor import COCODemo
# 参数配置文件
config_file = "/home/yuxin/maskrcnn-benchmark-master-ap/experiment/cfg/e2e_faster_rcnn_R_50_FPN_1x.yaml"#自己配置的cfg文件
cfg.merge_from_file(config_file)
cfg.merge_from_list(["MODEL.DEVICE", "cpu"])
coco_demo = COCODemo(cfg, min_image_size=800, confidence_threshold=0.7, )
imgfile = '/home/yuxin/maskrcnn-benchmark-master-ap/demo/timg8.jpg'
pil_image = Image.open(imgfile).convert("RGB")
image = np.array(pil_image)[:, :, [2, 1, 0]]
# forward predict
predictions = coco_demo.run_on_opencv_image(image)
# vis
'''
plt.subplot(1, 2, 1)
plt.imshow(image[:, :, ::-1])
plt.axis('off')
'''
plt.subplot(1, 1, 1)
plt.imshow(predictions[:, :, ::-1])
plt.axis('off')
plt.show()
运行命令:
$ python webcam.py --min-image-size 800
五、增加可视化
1、修改maskrcnn_benchmark/config/defaults.py在最后添加
_C.TENSORBOARD_EXPERIMENT = "logs/maskrcnn-benchmark" # tensorboard experiment location
2、修改maskrcnn_benchmark/engine/trainer.py更改如下
from maskrcnn_benchmark.utils.comm import get_world_size
#from maskrcnn_benchmark.utils.metric_logger import MetricLogger #注释掉
.........
def do_train(
model,
data_loader,
optimizer,
scheduler,
checkpointer,
device,
checkpoint_period,
arguments,
meters #添加的参数
):
logger = logging.getLogger("maskrcnn_benchmark.trainer")
logger.info("Start training")
#meters = MetricLogger(delimiter=" ") #注释掉
3、修改maskrcnn_benchmark/utils/metric_logger.py
import time #添加
from collections import defaultdict
from collections import deque
from datetime import datetime #添加
import torch
from .comm import is_main_process #添加
def __str__(self):
loss_str = []
for name, meter in self.meters.items():
loss_str.append(
"{}: {:.4f} ({:.4f})".format(name, meter.median, meter.global_avg)
)
return self.delimiter.join(loss_str)
############添加以下代码
class TensorboardLogger(MetricLogger):
def __init__(self,
log_dir,
start_iter=0,
delimiter='\t'):
super(TensorboardLogger, self).__init__(delimiter)
self.iteration = start_iter
self.writer = self._get_tensorboard_writer(log_dir)
@staticmethod
def _get_tensorboard_writer(log_dir):
try:
from tensorboardX import SummaryWriter
except ImportError:
raise ImportError(
'To use tensorboard please install tensorboardX '
'[ pip install tensorflow tensorboardX ].'
)
if is_main_process():
timestamp = datetime.fromtimestamp(time.time()).strftime('%Y%m%d-%H:%M')
tb_logger = SummaryWriter('{}-{}'.format(log_dir, timestamp))
return tb_logger
else:
return None
def update(self, ** kwargs):
super(TensorboardLogger, self).update(**kwargs)
if self.writer:
for k, v in kwargs.items():
if isinstance(v, torch.Tensor):
v = v.item()
assert isinstance(v, (float, int))
self.writer.add_scalar(k, v, self.iteration)
self.iteration += 1
4、修改tools/train_net.py
import os
import torch
from maskrcnn_benchmark.config import cfg
from maskrcnn_benchmark.data import make_data_loader
#from maskrcnn_benchmark.solver import make_lr_scheduler #注释掉
#from maskrcnn_benchmark.solver import make_optimizer #注释掉
from maskrcnn_benchmark.engine.inference import inference
from maskrcnn_benchmark.engine.trainer import do_train
from maskrcnn_benchmark.modeling.detector import build_detection_model
from maskrcnn_benchmark.solver import make_lr_scheduler #添加
from maskrcnn_benchmark.solver import make_optimizer #添加
from maskrcnn_benchmark.utils.checkpoint import DetectronCheckpointer
from maskrcnn_benchmark.utils.collect_env import collect_env_info
from maskrcnn_benchmark.utils.comm import synchronize, get_rank
from maskrcnn_benchmark.utils.imports import import_file
from maskrcnn_benchmark.utils.logger import setup_logger
from maskrcnn_benchmark.utils.metric_logger import (
MetricLogger, TensorboardLogger) #添加
from maskrcnn_benchmark.utils.miscellaneous import mkdir
#def train(cfg, local_rank, distributed): # 注释掉换成下面的定义方式
def train(cfg, local_rank, distributed, use_tensorboard=False):
model = build_detection_model(cfg)
device = torch.device(cfg.MODEL.DEVICE)
model.to(device)
checkpoint_period = cfg.SOLVER.CHECKPOINT_PERIOD #在checkpoint_period 添加以下函数
if use_tensorboard:
meters = TensorboardLogger(
log_dir=cfg.TENSORBOARD_EXPERIMENT,
start_iter=arguments['iteration'],
delimiter=" ")
else:
meters = MetricLogger(delimiter=" ")
do_train(
model,
data_loader,
optimizer,
scheduler,
checkpointer,
device,
checkpoint_period,
arguments,
meters #添加meters
)
help="Do not test the final model",
action="store_true",
)#添加下面的函数
parser.add_argument(
"--use-tensorboard",
dest="use_tensorboard",
help="Use tensorboardX logger (Requires tensorboardX installed)",
action="store_true",
default=False
)
# model = train(cfg, args.local_rank, args.distributed) 注释掉换成以下函数
model = train(
cfg=cfg,
local_rank=args.local_rank,
distributed=args.distributed,
use_tensorboard=args.use_tensorboard
)
六、增加可视化重新训练
1、输入训练命令:
$ python tools/train_net.py --use-tensorboard --config-file experiment/cfg/e2e_faster_rcnn_R_50_FPN_1x.yaml
2、可视化
$ tensorboard --logdir=logs

注:
开始训练的时候遇到一个问题就是改变学习率的参数重新开始训练时,加载的还是上次训练设置的参数。这个问题是由于pytorch在加载checkpoint的时候会把之前训练的optimizer和scheduler一起加载进来。所以如果要重新设置学习率的话,需要在加载state_dict的时候不启用上次训练保存的optimizer和scheduler参数。把utils/checkpoint.py文件中用于load optimizer和scheduler的两行代码注掉就可以了:
if "optimizer" in checkpoint and self.optimizer:
self.logger.info("Loading optimizer from {}".format(f))
# self.optimizer.load_state_dict(checkpoint.pop("optimizer"))if "scheduler" in checkpoint and self.scheduler:
self.logger.info("Loading scheduler from {}".format(f))
# self.scheduler.load_state_dict(checkpoint.pop("scheduler"))
参考博客:
https://ihaoming.top/archives/623a7632.html
https://blog.csdn.net/qq_34795071/article/details/88913717
https://blog.csdn.net/qq_34795071/article/details/88949195
https://blog.csdn.net/x572722344/article/details/84934188
https://blog.csdn.net/qq_41648043/article/details/86362169
https://blog.csdn.net/qq_35608277/article/details/88865574
https://zhuanlan.zhihu.com/p/57603975