经验 | 深度学习中常见的损失函数(loss function)总结
点上方蓝字计算机视觉联盟获取更多干货
在右上方 ··· 设为星标 ★,与你不见不散
仅作分享,不代表本公众号立场,侵权联系删除
转载于:机器学习算法与自然语言处理出品 单位 | 哈工大SCIR实验室
AI博士笔记系列推荐
周志华《机器学习》手推笔记正式开源!可打印版本附pdf下载链接
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
常见的损失函数以及其优缺点如下:
0-1损失函数(zero-one loss)
0-1损失是指预测值和目标值不相等为1, 否则为0:
特点:
(1)0-1损失函数直接对应分类判断错误的个数,但是它是一个非凸函数,不太适用.
(2)感知机就是用的这种损失函数。但是相等这个条件太过严格,因此可以放宽条件,即满足 时认为相等,
2. 绝对值损失函数
绝对值损失函数是计算预测值与目标值的差的绝对值:
3. log对数损失函数
log对数损失函数的标准形式如下:
特点:
(1) log对数损失函数能非常好的表征概率分布,在很多场景尤其是多分类,如果需要知道结果属于每个类别的置信度,那它非常适合。
(2)健壮性不强,相比于hinge loss对噪声更敏感。
(3)逻辑回归的损失函数就是log对数损失函数。
4. 平方损失函数
平方损失函数标准形式如下:
特点:
(1)经常应用与回归问题
5. 指数损失函数(exponential loss)
指数损失函数的标准形式如下:
特点:
(1)对离群点、噪声非常敏感。经常用在AdaBoost算法中。
6. Hinge 损失函数
Hinge损失函数标准形式如下:
特点:
(1)hinge损失函数表示如果被分类正确,损失为0,否则损失就为 。SVM就是使用这个损失函数。
(2)一般的 是预测值,在-1到1之间, 是目标值(-1或1)。其含义是, 的值在-1和+1之间就可以了,并不鼓励 ,即并不鼓励分类器过度自信,让某个正确分类的样本距离分割线超过1并不会有任何奖励,从而使分类器可以更专注于整体的误差。
(3) 健壮性相对较高,对异常点、噪声不敏感,但它没太好的概率解释。
7. 感知损失(perceptron loss)函数
感知损失函数的标准形式如下:
特点:
(1)是Hinge损失函数的一个变种,Hinge loss对判定边界附近的点(正确端)惩罚力度很高。而perceptron loss只要样本的判定类别正确的话,它就满意,不管其判定边界的距离。它比Hinge loss简单,因为不是max-margin boundary,所以模型的泛化能力没 hinge loss强。
8. 交叉熵损失函数 (Cross-entropy loss function)
交叉熵损失函数的标准形式如下:
注意公式中 表示样本, 表示实际的标签, 表示预测的输出, 表示样本总数量。
特点:
(1)本质上也是一种对数似然函数,可用于二分类和多分类任务中。
二分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出):
多分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出):
(2)当使用sigmoid作为激活函数的时候,常用交叉熵损失函数而不用均方误差损失函数,因为它可以完美解决平方损失函数权重更新过慢的问题,具有“误差大的时候,权重更新快;误差小的时候,权重更新慢”的良好性质。
最后奉献上交叉熵损失函数的实现代码:cross_entropy.
这里需要更正一点,对数损失函数和交叉熵损失函数应该是等价的!!!(此处感谢
@Areshyy
的指正,下面说明也是由他提供)
下面来具体说明:

相关高频问题:
1.交叉熵函数与最大似然函数的联系和区别?
区别:交叉熵函数使用来描述模型预测值和真实值的差距大小,越大代表越不相近;似然函数的本质就是衡量在某个参数下,整体的估计和真实的情况一样的概率,越大代表越相近。
联系:交叉熵函数可以由最大似然函数在伯努利分布的条件下推导出来,或者说最小化交叉熵函数的本质就是对数似然函数的最大化。
怎么推导的呢?我们具体来看一下。
设一个随机变量 满足伯努利分布,
则 的概率密度函数为:
因为我们只有一组采样数据 ,我们可以统计得到 和 的值,但是 的概率是未知的,接下来我们就用极大似然估计的方法来估计这个 值。
对于采样数据 ,其对数似然函数为:
可以看到上式和交叉熵函数的形式几乎相同,极大似然估计就是要求这个式子的最大值。而由于上面函数的值总是小于0,一般像神经网络等对于损失函数会用最小化的方法进行优化,所以一般会在前面加一个负号,得到交叉熵函数(或交叉熵损失函数):
这个式子揭示了交叉熵函数与极大似然估计的联系,最小化交叉熵函数的本质就是对数似然函数的最大化。
现在我们可以用求导得到极大值点的方法来求其极大似然估计,首先将对数似然函数对 进行求导,并令导数为0,得到
消去分母,得:
所以:
这就是伯努利分布下最大似然估计求出的概率 。
2. 在用sigmoid作为激活函数的时候,为什么要用交叉熵损失函数,而不用均方误差损失函数?
其实这个问题求个导,分析一下两个误差函数的参数更新过程就会发现原因了。
对于均方误差损失函数,常常定义为:
其中 是我们期望的输出, 为神经元的实际输出( )。在训练神经网络的时候我们使用梯度下降的方法来更新 和 ,因此需要计算代价函数对 和 的导数:
然后更新参数 和 :
因为sigmoid的性质,导致 在 取大部分值时会很小(如下图标出来的两端,几乎接近于平坦),这样会使得 很小,导致参数 和 更新非常慢。
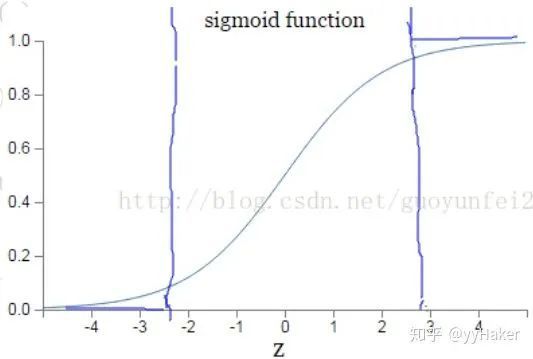
那么为什么交叉熵损失函数就会比较好了呢?同样的对于交叉熵损失函数,计算一下参数更新的梯度公式就会发现原因。交叉熵损失函数一般定义为:
其中 是我们期望的输出, 为神经元的实际输出( )。同样可以看看它的导数:
另外,
所以有:
所以参数更新公式为:
可以看到参数更新公式中没有 这一项,权重的更新受 影响,受到误差的影响,所以当误差大的时候,权重更新快;当误差小的时候,权重更新慢。这是一个很好的性质。
所以当使用sigmoid作为激活函数的时候,常用交叉熵损失函数而不用均方误差损失函数。
end
这是我的私人微信,还有少量坑位,可与相关学者研究人员交流学习
目前开设有人工智能、机器学习、计算机视觉、自动驾驶(含SLAM)、Python、求职面经、综合交流群扫描添加CV联盟微信拉你进群,备注:CV联盟

王博的公众号,欢迎关注,干货多多

王博的系列手推笔记(附高清PDF下载):
博士笔记 | 周志华《机器学习》手推笔记第一章思维导图
博士笔记 | 周志华《机器学习》手推笔记第二章“模型评估与选择”
博士笔记 | 周志华《机器学习》手推笔记第三章“线性模型”
博士笔记 | 周志华《机器学习》手推笔记第四章“决策树”
博士笔记 | 周志华《机器学习》手推笔记第五章“神经网络”
博士笔记 | 周志华《机器学习》手推笔记第六章支持向量机(上)
博士笔记 | 周志华《机器学习》手推笔记第六章支持向量机(下)
博士笔记 | 周志华《机器学习》手推笔记第七章贝叶斯分类(上)
博士笔记 | 周志华《机器学习》手推笔记第七章贝叶斯分类(下)
博士笔记 | 周志华《机器学习》手推笔记第八章(上)
博士笔记 | 周志华《机器学习》手推笔记第八章(下)
博士笔记 | 周志华《机器学习》手推笔记第九章
点个在看支持一下吧