笔记内容:
和Python相关的一些,无法分类的内容。用于日常记录。介于放个假回来就以惊人的速度忘掉很多以前会的东西。所以做个记录以备“可能哪天会忘记”。
- 似乎有些笔记用python2,有些用python3...=_= 一般来说应该2和3都能用,除非特殊注明。
-
[u'OTU1', u'OTU2', u'OTU3'] ----> ['OTU1', 'OTU2', 'OTU3']
去掉list中的u。u即其unicode。在Python中使用ok,但是当导出字符型的list在R中操作时会出现问题。
两个方法:
a = [u'OTU1', u'OTU2', u'OTU3']
test = [str(item) for item in a]
test_ = [item.encode('utf-8') for item in a]
用pycharm install packages(不能再忘了)
File --> Settings --> project:XXXX (project settings) --> project interpreter --> 右上角加号
命令行:
sudo pip install package-name把list和list名称完整的写到txt里
比方说要把a写入txt文档,a = ['OTU1', 'OTU2', 'OTU3']
打开这个txt文档,就看见:a = ['OTU1', 'OTU2', 'OTU3']
...查看Ubuntu系统版本
打开terminal,
lsb_release -astring.startswith('a')
返回True或False, 查看一个String是否由a起头windows下安装python并且修改环境变量
在python官网上https://www.python.org/downloads/下载.exe然后双击打开,一路next,在命令行里输入
C:\Users\username>path=%path%;C:\Python27
(C:\Python27是python的安装路径)查看一个模块的版本
在ipython里:
import pandas as pd
pd.__version__快速浏览一下数据状况:
df.head()查看前5行
df.shape查看行列数
df['colname'].value_counts()或df.colname.value_counts()对多分类变量,列出每一类的counts数目。如果是数值型,会把每个数值当作分类变量
df.colname.count()给出该列non-NaN的个数。在df.count()中使用时,可以指定axis=
df.describe()只作用于数值型变量,会罗列出其数目,平均值,标准差,极大极小值及四分位间距。os 的常规用法
os.getcwd()类似R里的getwd()
os.chdir("XXX/XXX/XXX")改变当前工作目录的路径
os.path.join("XX/", "XXX.doc")得到XX/XXX.doc
os.path.expanduser('~')得到home目录
os.path.split("XX/XXX/test.doc")得到两个变量,分别是XX/XXX和test.doc,即路径及其文件名(带有扩展名)
os.path.splitext("test.doc")得到文件名及其扩展名两个变量,即test和.doc
os.path.realpath('XX.doc')返回该文件的绝对路径(将该文件和当前工作目录join在一起)
乱入一个glob.glob("*.csv")把工作目录中所有以.csv结尾的文件名称列出来,并放进一个List里,返回值为一个List把dictionary的key和value对调
{value:key for key, value in a_dict.items()}.format和占位符%s
"{0} 's password is {1}".format(a,b)
"%s 's password is %s" % (a,b)
两者output是一样的:"username 's password is password"要输入多行string:
a = '''
XXXXX
XXX
XX
'''
print a
'\nXXXXX\nXXX\nXX\n'
-
re正则
e.g. 1
pattern = '^M(b|cd|pp)[abc]N$'
^以M为开头;$以N为结尾,中间的()内为一个part,为b或者cd或者pp.(必须是exactly为b或者cd或者pp)
[abc]方括号的意思为“其中任意一个字符”。即abc中任意一个字母。
e.g. 2
pattern = '^M{0,3}(\d{3})$'
{}代表了它前面那个字符可以出现多少次数。{0,3}表示M可以出现0,1,2,3次。如果是{3}那就是exactly3次
\d{3}为任何一个数字(0到9),出现3次
e.g. 3
pattern = '^\d{3}\D+(cd|df)\D*(cd)$'
\D为任何一个不是数字(不是0到9的字符,比方说字母或者符号)的字符。+为一个或者多个。*为0个或者多个。所以\D+可以用于匹配连接符号等。\D*可以用于匹配没有或有连接符。
e.g. 4
如下所示:.groups()和.group()的差别。.groups()返回一个tuple, 里面是与pattern里所有()匹配上的东西。pattern里有多少个()这里tuple里就有多少个元素。
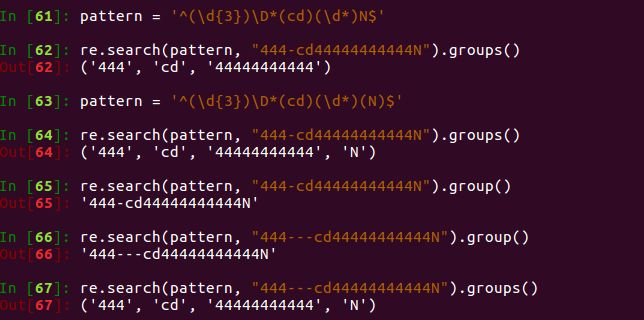
e.g. 5
如下所示:r'string'的意思为“raw string”, 即一些符号如换行符,tab符都会被当作string来对待。在pattern去掉了^,表明(\d{3})不一定是一个字符串的开头,中间开始也算数。(...用'''XXX'''没有什么意义,只是试一下而已。)

e.g. 6
在Verbose正则中,可以忽略空格换行tab及注释,从而让正则可读性更强。如下所示。string的多行输入用'''XXX'''。但是一定要在pattern中指定re.VERBOSE。使用re.compile()把这些信息整合起来。
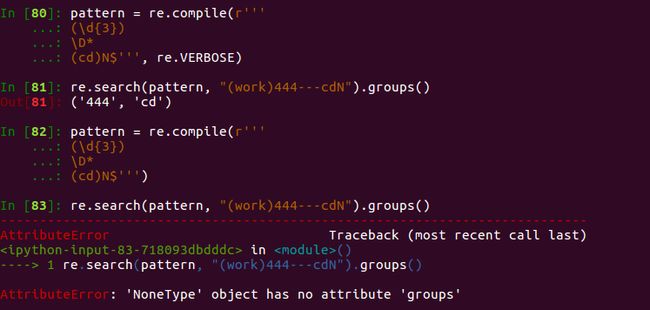
e.g. 7
re.sub的用法:
re.sub('要换掉的字符','要换成的字符', '字符串')将字符串指定的部分替换掉。它会替换掉字符串中
所有匹配到的字符。
一个注意:
^[]``^在
[]外的时候,为“以...为开头”的意思;
[^]
^在
[]内时,为排除的意思。
[^abc]即除了abc以外的
任何一个字符。
>>> import re
>>> test = 'bus'
>>> test
'bus'
>>> re.search('[sxz]$',test) # []为[]中任意一个字符,即以x或s或z结尾的词
<_sre.SRE_Match object at 0x0000000003D1E988>
>>> re.sub('$', 'es', test)
'buses'
>>> re.sub('[abc]', 'o', 'aaabbbccc9999')
'ooooooooo9999'
>>> pattern = '[^abc]N$' # N前面那一个字符,需要是除了abc以外任何一个字符
>>> re.search(pattern, 'oooN')
<_sre.SRE_Match object at 0x0000000003D1E9F0>
- 获取一个array/list/字符串中每个element的Index
enumerate():枚举,数数。如果是重复出现的elements,可以给出多个index
好用!
for i,j in enumerate(['a','b','c','d']):
print [i,j]
[i for i,j in enumerate(['a','b','c','d','d']) if j == 'd']

- ipython里的magic commands
In [1]: %history -n 1-4
In [2]: %run yourscript.py
In [3]: %cpaste
%history在ipython中查看历史命令,-n 1-4是看前4个
%run 在ipython中运行脚本。运行后脚本中定义的函数都会被记录在环境中。
在ipython中复制多行代码会有tab的问题,一个一个手动修改很麻烦,使用%cpaste可以复制粘贴的时候自动正确缩进。且可以粘贴多个代码块。在末尾打--回车,即完成粘贴并运行
.unique()
用于Serise,相当于set(df['colname'])只是其output为一个array,而不是set在pandas格式的数据中检查缺失值
.isnull(),.notnull(),.dropna(),.fillna()
df.isnull().any()看dataframe中每一列是否存在缺失值。
df.dropna(axis=..., thresh=)去除含有缺失值的整行或整列,可以设置留下最少多少个NA的行/列
df.fillna(0)缺失值都填充为0['a', 'b', 'c', 'c', 'd'...]中'c'的个数,即计数一个List中各个element的counts数目
list.count(element)比方说list.count('c')
如果带有条件的计数,比方说所有大于2的elements:
sum(1 for i in test if i > 2)sum()里是1!!!相当于计数。根据一个dictionary,使用
map()给一个dataframe添加一列。
比方说:
df = pd.DataFrame(np.random.randint(40,size=(3,4)),index=['a','b','c'],columns=['col'+ str(i) for i in range(0,4)])
df = df.reset_index()
print df
index col0 col1 col2 col3
0 a 14 18 39 1
1 b 9 4 10 16
2 c 11 9 30 33
# 根据{'a':'A','b':'B','c':'C'},给df添一列
dic = {'a':'A','b':'B','c':'C'}
df['new'] = df['index'].map(dic)
print df
index col0 col1 col2 col3 new
0 a 14 18 39 1 A
1 b 9 4 10 16 B
2 c 11 9 30 33 C
如果是将一列转化为二分类变量,则
可以使用df['new'] = df.eval("col1 <5 and col2>5")
及df['new'] = np.where(df.eval("col1 <5 and col2>5"), 'positive', 'negative')
- 把
range(1,n)转化为['d001', 'd002', 'd003',...'d00n-1']
test = []
for i in range(1,6):
test.append("{0}{1:03}".format('d',i))
print test
['d001', 'd002', 'd003', 'd004', 'd005']
- 对一个dataframe的每行遍历
print df
index col0 col1 col2 col3 new
0 a 14 18 39 1 A
1 b 9 4 10 16 B
2 c 11 9 30 33 C
for ind, row in df.iterrows():
print {ind:(row['col0'], row['new'])} # ind 就是每行的index, row就是每行的内容,可以用row['colname']来选取每行的哪一列
{'a': (14, 'A')}
{'b': (9, 'B')}
{'c': (11, 'C')}
dataframe中判断一列是否有重复
df.index.is_unique
df['colname'].is_unique
返回True/False.isin()选择一个col中的value,都在一个List中的行
...甚为绕口,举个例子:
In [6]: df
Out[6]:
value1 value2 value3 class
a 66 54 53 class1
b 91 21 35 class1
c 75 34 68 class2
d 31 50 31 class2
e 77 28 49 class3
In [8]: se = ['class1','class2']
In [9]: se
Out[9]: ['class1', 'class2']
In [10]: df.loc[df['class'].isin(se),:]
Out[10]:
value1 value2 value3 class
a 66 54 53 class1
b 91 21 35 class1
c 75 34 68 class2
d 31 50 31 class2
groupby
按照某列分组求和:df.groupby(['colname']).sum()
每列求和(整列相加):df.sum(axis=0)
每行求和(整行相加):df.sum(axis=1)
按照index来drop掉特殊的一行:df = df.drop('index_name')把内容一行一行的写到某个文件里(...早就该记住了)
test = ["a","b","c"]
with open("XXXX.txt","w") as f1:
for i in range(0,len(test)+1):
f1.write(str(i) + "," + ",".join(test) + '\n')
# 得到XXXX.txt:
0,a,b,c
1,a,b,c
2,a,b,c
3,a,b,c
快速把一个数据集随机分成1/4,3/4两个部分,用于指定训练集和测试集
df['is_train'] = np.randomuniform(0,1,len(df)) <= .75dictionary.get(key,[])
通过给定key来获取values, 如果给出的key不存在,则用[]中的表示在用于List时,append和extend的区别
a = ['a', 'b']
a.append(['c', 'd'])
print a # 得到 ['a', 'b', ['c', 'd']]
a.extend(['c', 'd'])
print a # 得到['a', 'b', 'c', 'd']
filter rows: col列中每行中包含指定string则filter出来
df[df['col'].str.contains('string')]
有可能因为df['col']中含有NA值报错,则先去掉df['col']中的NA行:
df = df[df['col'].notnull()]在win10(pycharm)上使用matplotlib出现的一个问题
使用seaborn和matplotlib可能会出现以下报错:
RuntimeError: Cannot get window extent w/o renderer
需要check一下backend:
print matplotlib.get_backend()
如果不是'agg',则加上:matplotlib.use('agg')
'agg'后台似乎不能把图片show出来,直接保存就好。
虽然这好像是个matplotlib在Mac OS X系统上的bug,我这边用win10也有。
参考:
https://github.com/mwaskom/seaborn/issues/545
https://github.com/matplotlib/matplotlib/issues/10874在pycharm里切换python2和python3
File ----> Settings ----> project interpreter的选择条 ----> 选择你要的version
如果你要的version不在里面,比如python3, 在终端里输入which python3找到它的安装目录,然后点击选择条旁边的设置按钮(那个小齿轮),选择add Local找到安装目录下你要的python版本, apply即可。你安装了pip3, 基于python3的。但是
pip3 --version显示是基于python2.7的。
可以每次使用Pip的时候都这样:
python3.5 -m pip ...
....不利索的解决办法,也是解决办法。pandas读excel(这么简单的东西不要再忘了好吗)
pd.read_excel(infilepath, sheet_name='XXX'...)pandas: 把categorical的column转化为多列的one-hot-encoding
import pandas as pd
df['category'] = pd.Categorical(df['category'])
dummy_df = pd.get_dummies(df['category'], prefix = 'category_前缀')
# dummy_df就是category转化为one-hot-encoding后的结果
- argparse参数解析
以后再忘记,直接用这个照葫芦画瓢。
# 保存这个脚本为test_arg.py
import argparse
import numpy as np
import os
import pandas as pd
# 做一个这样的dataframe, 将其某一列抽出来存为ttt.csv
# df = pd.DataFrame(np.random.randint(40, size=(3,4)),
# index=['a', 'b', 'c'],
# columns=['col1','col2','col3','col4'])
def test_fun(df, colname, path):
df = pd.read_csv(df)
df[colname].to_csv(os.path.join(path, 'ttt.csv'))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-i', dest='df', required=True)
parser.add_argument('-col', dest='column', required=True)
parser.add_argument('-o', dest='path')
args = parser.parse_args()
# 在terminal中我们要传3个参数,-i的df, -col的column name,以及-o的output path
df = args.df
column = args.column
path = args.path
test_fun(df=df, colname=column, path=path)
#在终端这么用:
$ python3.5 test_arg.py -i XXXX.csv -col 'col2' -o 'usrname/Desktop'
jupyter-lab(或者notebook)报错
--NotebookApp.iopub_data_rate_limit即IOPub data rate exceeded
在命令行中:
$ jupyter-lab --LabApp.iopub_data_rate_limit=2147483647
是jupyter notebook则
$ jupyter notebook --NotebookApp.iopub_data_rate_limit=2147483647to_csv()保存内容中有中文,出现乱码
试试XX.to_csv(encoding='utf-8')
不行再试试XX.to_csv(encoding='utf_8_sig')jupyter-lab里用Plotly画图报错:
No renderer could be found for output. It has the following MIME types: application/vnd.plotly.v1+json,没有图显示
参考这里,需要安装一些JupyterLab Supportpython2和python3的一些区别

df.query()
查询:行使一个filter的功能。格式是:
df.query("colname == 'value' and colname2 == 'value2'")
注意colname中不可以用空格把dataframe的colnames中的空格换成“_”
df.columns = df.columns.str.replace(' ', '_')用
df.groupby('colname').size()来计数多分类变量的value频率
df = pd.DataFrame({'a' : ['u','l','y','y'],'b' : ['u','u','l','y'],'c':['l','y','u','y']})
df
a b c
0 u u l
1 l u y
2 y l u
3 y y y
df.groupby('a').size()
a
l 1
u 1
y 2
dtype: int64
df.groupby('a').size()['y']
2
- 记一个Pands导入数据的坑:
我们有一份数据大概是这样的:
samples-ID是列(有重复ID),行是features

导入的时候:
test = pd.read_excel("c:/Users/XXX/Desktop/test_file.xlsx",sheet_name='Sheet1')
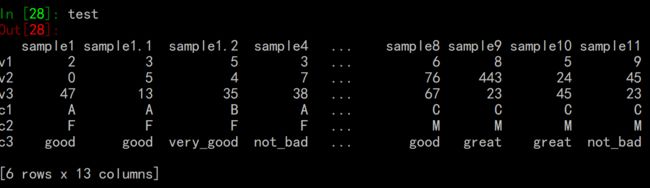
要小心如果导入的数据列有重复名,pandas会自动给加上
.1
.2等标记以区别。导入数据行有重复名则不会。pandas要求列名必须是唯一的。
- 在python3里运行python2的脚本
比方说你要把lefse的步骤整成一个Python3的脚本,但是lefse是python2写的。比方说如下所示,format_input.py是python2的脚本。
shell = True相当于独立一个shell窗口运行python3cmd。如果没有的话可能会调用到什么奇怪的地方。
另外最好把python的绝对路径写明。
import subprocess
python3cmd = '/user/bin/python format_input.py prepared.csv prepared.in -c 2 -u 1'
subprocess.Popen(python3cmd, shell=True)
如果中间有output,则
proce = subprocess.Popen(python3cmd, shell=True, stdout=subprocess.PIPE)
output = proce.communicate()
print(output)
如果有一系列脚本需要运行:
cmd1 = 'XXX.py -in XXX.csv -o XXX.txt'
cmd2 = 'XXXX.py -in XXX.txt -o XXX.pdf'
cmd3 = 'XX.py -in XXX.txt -o XXX_1.pdf'
cmd = ';'.join([cmd1, cmd2, cmd3])
process = subproess.Popen(cmd, stdout=subprocess.PIPE, ...) # 不用split出来
参考链接:
https://blog.csdn.net/bcfdsagbfcisbg/article/details/78134172
记一个小坑
linux系统上有python2也有python3, 试图在在Python2.7里安装rpy2模块,反复报错
ERROR: Command "python setup.py egg_info" failed with error code 1 in...
参考https://github.com/facebook/prophet/issues/418
更新pip2
sudo python2 -m pip install --upgrade pip
更新setuptools
sudo python2 -m pip install --upgrade setuptools
指定rpy2的版本pip
sudo python2 -m pip install rpy2==2.8.6判断一个file是否为空
os.stat('file').st_size == 0筛选某列非空/空的行
df[df['col'].notnull()]
df[df['col'].isnull()]
47.python做correlation
from scipy.stats.stats import pearsonr
# from scipy.stats.stats import spearmanr 或者spearman系数
pearsonr(list1, list2)
# 返回一个tuple: (r,p)
去除加和为0的行/列
df.sum(axis=1) != 0)即去掉加和为0的行,下同:
df.loc[(df.sum(axis=1) != 0), (df.sum(axis=0) != 0)]在Python里fdr矫正P值
from statsmodels.stats.multitest import fdrcorrection
a_list_of_p = [0.5,0.000000000001,0.000000000009,0.05,0.000003,0.4] # 你要矫正的P值
fdrcorrection(a_list_of_p)
# 得到:
(array([False, True, True, False, True, False]),
array([5.0e-01, 6.0e-12, 2.7e-11, 7.5e-02, 6.0e-06, 4.8e-01]))
- 将一个flat list(一维List) 转化为 list of lists; 将list of lists 转化为flat list
import itertools
# 把list of lists 合并为 flat list
itertools.chain.from_iterable(list_of_lists)
# 把flat list 拆成一行n个的list of lists
zip(*[iter(flat_list)] * n)
一个查漏补缺:tuple, list 和 set的异同
list: [] elements有序可index,可改写,
tuple: () elements有序可index, 不可改写
set: {} elements无序不可index, 可改写,只包含不重复的elementslist[::2]间隔2个elements
A = [1,2,3,4,5,6]
A[::2] # [1,3,5]sort list
B = [2,3,4,1,6]
sorted(B) # [1,2,3,4,6]
或者
B.sort()
print(B)zip(*iterablelist)
S = ['cba','daf','ghi']
for col in zip(*S):
print(col)
# got:
('c', 'd', 'g')
('b', 'a', 'h')
('a', 'f', 'i')
或者不用iteration:
A = ['abfc','sdtf','dfoe']
for i in range(len(A[0])):
col = [A[j][i] for j in range(len(A))]
print(col)
# [['a', 's', 'd'],
# ['b', 'd', 'f'],
# ['f', 't', 'o'],
# ['c', 'f', 'e']]
-
collections.Counter
collections是python build-in的模块
arr1 = [2, 3, 1, 3, 2, 4, 6, 7, 9, 2, 19]
collections.Counter(arr1)
# 返回一个字典,key为list中不重复的各elements, value为其计数
# Counter({2: 3, 3: 2, 1: 1, 4: 1, 6: 1, 7: 1, 9: 1, 19: 1})
collections.Counter(arr1)[20]
# 返回0, 因为这里面20的count是0. 不会像普通字典那样,没有key则会报错
- 给定年月日信息,查是星期几?
import datetime
we = datetime.datetime(year,month,day).weekday()
we_day = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday","Sunday"][we]
生成26个字母:
[chr(ord('a')+i) for i in range(26)]找多个字典的intersection
即k,v均相同的对子
a_list = [{'c': 1, 'o': 2, 'l': 1},
{'l': 1, 'o': 1, 'c': 1, 'k': 1},
{'c': 1, 'o': 2, 'k': 1}]
dict(set.intersection(*(set(d.items()) for d in a_list)))
- 比如一个fasta文件,读取某一行的后N行
with open('XX/XX/XX.txt') as f:
for line in f:
if line.startswith('>'):
print([next(f) for index in range(N)])
apply lambda x:不要再忘了
df['newcol'] = df['col'].apply(x: 'value if condition met' if x condition else 'value if condition not met')with open fastq.gz 文件,一顿操作之后保存成 .fastq
在操作的时候要注意bytes和string之间的转化
有空去找找怎么直接对.gz操作,保存成.gz!
bytes objdect:b'XXX'
string to bytes:XXX.encode()
bytes to strint:XXX.decode()
test_in = 'XXX.fastq.gz'
test_out = 'XXX.fastq'
barcode_list = ['ATGCTC','ATCCGT'....]
with gzip.open(test_in, 'rb') as f, open(test_out, 'w') as data_out:
#..就算'rb'换成'r'都是以bytes形式打开,因为gzip.open打开后就是一个二进制的文件
for line in f:
line = line.decode()
if line.startswith("@HWI"):
seqs = next(f).decode() #注意.decode(),这里将bytes转化为string
sign = next(f).decode()
quality = next(f).decode()
for i in barcode_list:
if i in seq:
seq = i + seq.split(i)[1]
data_out.write("{}{}{}{}".format(line,seq,sign,quality))
如果要write到.gz文件,则:
data_out = 'XXXX.fastq.gz'
with open(test_out,'wt') as data_out:
data_out.write("XXXXXXX") # "XXXXXXXX"是string就可以
- 通过绝对路径来import模块
import sys
sys.path.append('XX/XXX/XXX/XXXX')
from XXXX.XX import any_function