睿智的seq2seq模型2——利用seq2seq模型实现英文到法文的翻译
睿智的seq2seq模型2——利用seq2seq模型实现英文到法文的翻译
- 学习前言
- seq2seq简要介绍
- 英文翻译到法文的思路
-
- 1、对英文进行特征提取
- 2、将提取到的特征传入到decoder
- 3、将"\t"作为起始符预测第一个字母
- 4、逐个字母向后传递进行预测
- 全部代码实现
学习前言
快乐学习新知识,seq2seq还是很重要的!

seq2seq简要介绍
seq2seq属于encoder-decoder结构的一种。
seq2seq的encoder是一个常见的循环神经网络,可以使用LSTM或者RNN,当输入一个字符串的时候,可以对其进行特征提取,获得语义编码C。
而decoder则将encoder得到的编码C作为初始状态输入到decoder的RNN中,得到输出序列。
语义编码C是输入内容的特征集合体,decoder可以讲这个特征集合体解码成输出序列。

英文翻译到法文的思路
1、对英文进行特征提取
将英文按顺序输入到LSTM中,LSTM会对英文进行特征提取。
我们知道LSTM存在两个重要的内容
一个是单元状态c、一个是输出值h。
LSTM对英文进行特征提取后,便会得到单元状态c和输出值h,这两者代表了输入英文的特征。
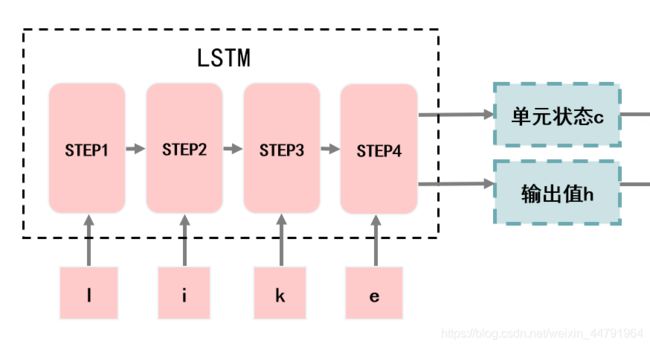
实现代码为:
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder_outputs, state_h, state_c = LSTM(latent_dim, return_state=True)(encoder_inputs)
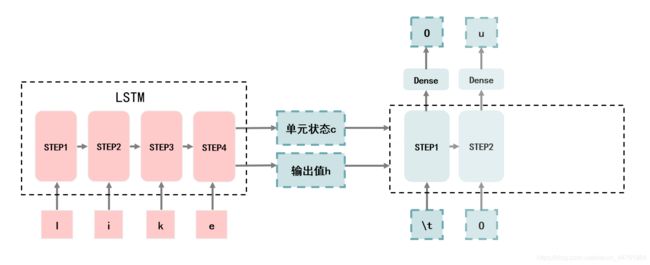
2、将提取到的特征传入到decoder
通过第一步,我们可以获取到单元状态c和输出值h,这两者代表了输入英文的特征。
这两者会作为decoder的初始状态传入到decoder的LSTM中。

3、将"\t"作为起始符预测第一个字母
当我们将单元状态c和输出值h作为初始值传入到decoder的LSTM中时。
seq2seq实现翻译的话需要一个字母接着一个字母往下预测,一般来说起始的符号是"\t",通过"\t"预测出第一个字母。

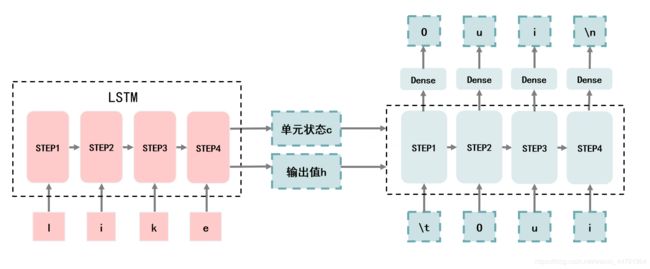
4、逐个字母向后传递进行预测
接下来就是将O作为下一个输入,将STEP1获得的单元状态h和输出值h作为初始状态传入到下一次的预测中,完成预测。
以此类推。
 以此类推,当出现"\n"的时候,表示结尾了!
以此类推,当出现"\n"的时候,表示结尾了!
全部代码实现
训练集在这里下载:
http://www.manythings.org/anki/fra-eng.zip
英文到法文的翻译可通过如下的代码实现。
from __future__ import print_function
from keras.models import Model
from keras.layers import Input, LSTM, Dense,TimeDistributed
import numpy as np
import keras.backend as K
def get_dataset(data_path, num_samples):
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
for line in lines[: min(num_samples, len(lines) - 1)]:
input_text, target_text, _ = line.split('\t')
# 用tab作用序列的开始,用\n作为序列的结束
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
return input_texts,target_texts,input_characters,target_characters
#------------------------------------------#
# init初始化部分
#------------------------------------------#
# 每一次输入64个batch
batch_size = 64
# 训练一百个世代
epochs = 100
# 256维特征向量
latent_dim = 256
# 一共10000个样本
num_samples = 10000
# 读取数据集
data_path = 'fra.txt'
# 获取数据集
# 其中input_texts为输入的英文字符串
# target_texts为对应的法文字符串
# input_characters用到的所有输入字符,如a,b,c,d,e,……,.,!等
# target_characters用到的所有输出字符
input_texts,target_texts,input_characters,target_characters = get_dataset(data_path, num_samples)
# 对字符进行排序
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
# 计算共用到了什么字符
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
# 计算出最长的序列是多长
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print('一共有多少训练样本:', len(input_texts))
print('多少个英文字母:', num_encoder_tokens)
print('多少个法文字母:', num_decoder_tokens)
print('最大英文序列:', max_encoder_seq_length)
print('最大法文序列:', max_decoder_seq_length)
# 建立字母到数字的映射
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
#---------------------------------------------------------------------------#
#--------------------------------------#
# 改变数据集的格式
#--------------------------------------#
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
# 为末尾加上" "空格
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
encoder_input_data[i, t + 1:, input_token_index[' ']] = 1.
# 相当于前一个内容的识别结果,作为输入,传入到解码网络中
for t, char in enumerate(target_text):
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data不包括第一个tab
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
decoder_input_data[i, t + 1:, target_token_index[' ']] = 1.
decoder_target_data[i, t:, target_token_index[' ']] = 1.
#---------------------------------------------------------------------------#
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder_outputs, state_h, state_c = LSTM(latent_dim, return_state=True)(encoder_inputs)
encoder_states = [state_h, state_c]
decoder_inputs = Input(shape=(None, num_decoder_tokens))
decoder_outputs, _, _ = LSTM(latent_dim, return_sequences=True, return_state=True)(decoder_inputs,initial_state=encoder_states)
decoder_outputs = TimeDistributed(Dense(num_decoder_tokens, activation='softmax'))(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# 开始训练
model.compile(optimizer='rmsprop', loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
# 保存模型
model.save('out.h5')
K.clear_session()
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder_outputs, state_h, state_c = LSTM(latent_dim, return_state=True)(encoder_inputs)
encoder_states = [state_h, state_c]
encoder_model = Model(encoder_inputs, encoder_states)
encoder_model.load_weights("out.h5",by_name=True)
encoder_model.summary()
decoder_inputs = Input(shape=(None, num_decoder_tokens))
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = LSTM(latent_dim, return_sequences=True,
return_state=True)(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = TimeDistributed(Dense(num_decoder_tokens, activation='softmax'))(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
decoder_model.load_weights("out.h5",by_name=True)
# 建立序号到字母的映射
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq):
states_value = encoder_model.predict(input_seq)
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, target_token_index['\t']] = 1.
stop_condition = False
decoded_sentence = ''
while not stop_condition:
# 以\t为开头,一个一个向后预测
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# 如果达到结尾
if (sampled_char == '\n' or len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
states_value = [h, c]
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
return decoded_sentence
for seq_index in range(100):
input_seq = np.expand_dims(encoder_input_data[seq_index],axis=0)
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
实现效果:
Input sentence: Call us.
Decoded sentence: Appellez-le.
-
Input sentence: Call us.
Decoded sentence: Appellez-le.
-
Input sentence: Come in.
Decoded sentence: Viens siti !
-
Input sentence: Come in.
Decoded sentence: Viens siti !