1、概述
HBase的存储结构和关系型数据库不一样,HBase面向半结构化数据进行存储。所以,对于结构化的SQL语言查询,HBase自身并没有接口支持。在大数据应用中,虽然也有SQL查询引擎可以查询HBase,比如Phoenix、Drill这类。但是阅读这类SQL查询引擎的底层实现,依然是调用了HBase的Java API来实现查询,写入等操作。这类查询引擎在业务层创建Schema来映射HBase表结构,然后通过解析SQL语法数,最后底层在调用HBase的Java API实现。
本篇内容笔者并不是给大家来介绍HBase的SQL引擎,我们来关注HBase更低层的东西,那就是HBase的存储实现。以及跨集群的HBase集群数据迁移。
2、内容
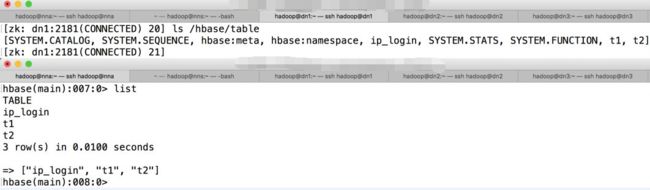
HBase数据库是唯一索引就是RowKey,所有的数据分布和查询均依赖RowKey。所以,HBase数据库在表的设计上会有很严格的要求,从存储架构上来看,HBase是基于分布式来实现的,通过Zookeeper集群来管理HBase元数据信息,比如表名就存放在Zookeeper的/hbase/table目录下。如下图所示
Architecture
HBase是一个分布式存储系统,底层数据存储依赖Hadoop的分布式存储系统(HDFS)。HBase架构分三部分来组成,它们分别是:ZooKeeper、HMaster和HRegionServer。
ZooKeeper
HBase的元数据信息、HMaster进程的地址、Master和RegionServer的监控维护(节点之间的心跳,判断节点是否下线)等内容均需要依赖ZooKeeper来完成。是HBase集群中不可缺少的核心之一。
HMaster
HMaster进程在HBase中承担Master的责任,负责一些管理操作,比如给表分配Region、和数据节点的心跳维持等。一般客户端的读写数据的请求操作不会经过Master,所以在分配JVM内存的适合,一般32GB大小即可。
HRegionServer
HRegionServer进程在HBase中承担RegionServer的责任,负责数据的存储。每个RegionServer由多个Region组成,一个Region维护一定区间的RowKey的数据。如下图所示

图中Region(dn2:16030)维护的RowKey范围为0001~0002。
HBase为了保证高可用性(HA),一般都会部署两个Master节点,其中一个作为主,另一个作为Backup节点。这里谁是主,谁是Backup取决于那个HMaster进程能从Zookeeper上对应的Master目录中竞争到Lock,持有该目录Lock的HMaster进程为主Master,而另外一个为Backup,当主Master发生意外或者宕机时,Backup的Master会立刻竞争到Master目录下的Lock从而接管服务,成为主Master对外提供服务,保证HBase集群的高可用性。
RegionServer
HBase负责数据存储的就是RegionServer,简称RS。在HBase集群中,如果只有一份副本时,整个HBase集群中的数据都是唯一的,没有冗余的数据存在,也就是说HBase集群中的每个RegionServer节点上保存的数据都是不一样的,这种模式由于副本数只有一份,即是配置多个RegionServer组成集群,也并不是高可用的。这样的RegionServer是存在单点问题的。虽然,HBase集群内部数据有Region存储和Region迁移机制,RegionServer服务的单点问题可能花费很小的代价可以恢复,但是一旦停止RegionServre上含有ROOT或者META表的Region,那这个问题就严重,由于数据节点RegionServer停止,该节点的数据将在短期内无法访问,需要等待该节点的HRegionServer进程重新启动才能访问其数据。这样HBase的数据读写请求如果恰好指向该节点将会收到影响,比如:抛出连接异常、RegionServer不可用等异常。
3、日志信息
HBase在实现WAL方式时会产生日志信息,即HLog。每一个RegionServer节点上都有一个HLog,所有该RegionServer节点上的Region写入数据均会被记录到该HLog中。HLog的主要职责就是当遇到RegionServer异常时,能够尽量的恢复数据。
在HBase运行的过程当中,HLog的容量会随着数据的写入越来越大,HBase会通过HLog过期策略来进行定期清理HLog,每个RegionServer内部均有一个HLog的监控线程。HLog数据从MemStore Flush到底层存储(HDFS)上后,说明该时间段的HLog已经不需要了,就会被移到“oldlogs”这个目录中,HLog监控线程监控该目录下的HLog,当该文件夹中的HLog达到“hbase.master.logcleaner.ttl”(单位是毫秒)属性所配置的阀值后,监控线程会立即删除过期的HLog数据。
4、数据存储
HBase通过MemStore来缓存Region数据,大小可以通过“hbase.hregion.memstore.flush.size”(单位byte)属性来进行设置。RegionServer在写完HLog后,数据会接着写入到Region的MemStore。由于MemStore的存在,HBase的数据写入并非是同步的,不需要立刻响应客户端。由于是异步操作,具有高性能和高资源利用率等优秀的特性。数据在写入到MemStore中的数据后都是预先按照RowKey的值来进行排序的,这样便于查询的时候查找数据。
5、Region分割
在HBase存储中,通过把数据分配到一定数量的Region来达到负载均衡。一个HBase表会被分配到一个或者多个Region,这些Region会被分配到一个或者多个RegionServer中。在自动分割策略中,当一个Region中的数据量达到阀值就会被自动分割成两个Region。HBase的表中的Region按照RowKey来进行排序,并且一个RowKey所对应的Region只有一个,保证了HBase的一致性。
一个Region中由一个或者多个Store组成,每个Store对应一个列族。一个Store中包含一个MemStore和多个Store Files,每个列族是分开存放以及分开访问的。自动分割有三种策略,分别是
ConstantSizeRegionSplitPolicy
在HBase-0.94版本之前是默认和唯一的分割策略。当某一个Store的大小超过阀值时(hbase.hregion.max.filesize,默认时10G),Region会自动分割。
IncreasingToUpperBoundRegionSplitPolicy
在HBase-0.94中,这个策略分割大小和表的RegionServer中的Region有关系。分割计算公式为:Min(RR'hbase.hregion.memstore.flush.size','hbase.hregion.max.filesize'),其中,R表示RegionServer中的Region数。
比如:hbase.hregion.memstore.flush.size=256MB,hbase.hregion.max.filesize=20GB,那么第一次分割的大小为Min(11256,20GB)=256MB,也就是在第一次大到256MB会分割成2个Region,后续以此公式类推计算。
KeyPrefixRegionSplitPolicy
可以保证相同前缀的RowKey存放在同一个Region中,可以通过hbase.regionserver.region.split.policy属性来指定分割策略。
6、磁盘合理规划
部署HBase集群时,磁盘和内存的规划是有计算公式的。随意分配可能造成集群资源利用率不高导致存在浪费的情况。公式如下:
#通过磁盘维度的Region数和Java Heap维度的Region数来推导
Disk Size/(RegionSize*ReplicationFactor)=Java Heap*HeapFractionForMemstore/(MemstoreSize/2)
公式中对应的hbase-site.xml文件中的属性中,见下表
| Key | Property |
|---|---|
| Disk Size | 磁盘容量大小,一般一台服务器有多块磁盘 |
| RegionSize | hbase.hregion.max.filesize默认10G,推荐范围在10GB~30GB |
| ReplicationFactor | dfs.replication默认为3 |
| Java Heap | 分配给HBase JVM的内存大小 |
| HeapFractionForMemstore | hbase.regionserver.global.memstore.lowerLimit默认为0.4 |
| MemstoreSize | hbase.hregion.memstore.flush.size默认为128M |
在实际使用中,MemstoreSize空间打下只使用了一半(1/2)的容量。 举个例子,一个RegionServer的副本数配置为3,RegionSize为10G,HBase的JVM内存分配45G,HBase的MemstoreSize为128M,那此时根据公式计算得出理想的磁盘容量为45G10240.4210G10243/128M=8.5T左右磁盘空间。如果此时,分配一个节点中挂载10个可用盘,共27T。那将有两倍的磁盘空间不匹配造成浪费。 为了提升磁盘匹配度,可以将RegionSize值提升至30G,磁盘空间计算得出25.5T,基本和27T磁盘容量匹配。
7、数据迁移
对HBase集群做跨集群数据迁移时,可以使用Distcp方案来进行迁移。该方案需要依赖MapReduce任务来完成,所以在执行迁移命令之前确保新集群的ResourceManager、NodeManager进程已启动。同时,为了查看迁移进度,推荐开启proxyserver进程和historyserver进程,开启这2个进程可以方便在ResourceManager业务查看MapReduce任务进行的进度。 迁移的步骤并不复杂,在新集群中执行distcp命令即可。具体操作命令如下所示
# 在新集群的NameNode节点执行命令
[hadoop@nna ~]$ hadoop distcp \
-Dmapreduce.job.queue.name=queue_0001_01 \
-update -skipcrccheck \
-m 100 hdfs://old_hbase:9000/hbase/data/tabname /hbase/data/tabname
为了迁移方便,可以将上述命令封装成一个Shell脚本。具体实现如下所示
#! /bin/bash
for i in `cat /home/hadoop/hbase/tbl`
do
echo $i
hadoop distcp -Dmapreduce.job.queue.name=queue_0001_01 -update -skipcrccheck -m 100 hdfs://old_hbase:9000/hbase/data/$i /hbase/data/$i
done
hbase hbck -repairHoles
将待迁移的表名记录在/home/hadoop/hbase/tbl文件中,一行代表一个表。内容如下所示:
[hadoop@nna ~]$ vi /home/hadoop/hbase/tbl
# 表名列表
tbl1
tbl2
tbl3
tbl4
最后,在循环迭代迁移完成后,执行HBase命令“hbase hbck -repairHoles”来修复HBase表的元数据,如表名、表结构等内容,会从新注册到新集群的Zookeeper中。
修复HBase表的元数据
[hadoop@nna ~]$ hbase hbck -repairHoles
8、总结
HBase集群中如果RegionServer上的Region数量很大,可以适当调整“hbase.hregion.max.filesize”属性值的大小,来减少Region分割的次数。在执行HBase跨集群数据迁移时,使用Distcp方案来进行,需要保证HBase集群中的表是静态数据,换言之,需要停止业务表的写入。如果在执行HBase表中数据迁移时,表持续有数据写入,导致迁移异常,抛出某些文件找不到。