【9】一些经典CNN结构的pytorch实现
以下实现各种经典的神经网络结构,以处理Cifar10数据集来设置网络中的参数,有关卷积吃操作以及卷积神经网络的具体介绍可以参考这篇:【6】卷积神经网络的介绍:
对于卷积之后的输出size的计算公式:
outsize = (insize - filtersize + 2*padding)/stride + 1
文章目录
-
-
- 1.LeNet-5
- 2.AlexNet
- 3.VGG
- 4.GoogLeNet
- 5.ResNet
-
导入主要的包
import math
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
1.LeNet-5

# 设置批训练大小
batch_size = 10
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5,self).__init__()
# 卷积层
self.conv_layer = nn.Sequential(
# input:torch.Size([batch_size, 3, 32, 32])
nn.Conv2d(in_channels=3,out_channels=6,kernel_size=5,stride=1,padding=0), # output:torch.Size([batch_size, 6, 28, 28])
nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # output:torch.Size([batch_size, 6, 14, 14])
nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5,stride=1,padding=0), # output:torch.Size([batch_size, 16, 10, 10])
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # output:torch.Size([batch_size, 16, 5, 5])
)
# output:torch.Size([batch_size, 16, 5, 5])
# 全连接层
self.fullconn_layer = nn.Sequential(
# input:torch.Size([batch_size, 16*5*5])
nn.Linear(16*5*5,120),
nn.ReLU(),
# input:torch.Size([batch_size, 120])
nn.Linear(120,84),
nn.ReLU(),
# input:torch.Size([batch_size, 84])
nn.Linear(84,10),
)
# output:torch.Size([10, 10])
def forward(self,x):
output = self.conv_layer(x) # output:torch.Size([batch_size, 16, 5, 5])
# output = output.view(batch_size,-1) # output:torch.Size([10, 16*5*5])
output = output.view(x.size(0),-1)
output = self.fullconn_layer(output) # output:torch.Size([10, 10])
return output
net = LeNet5()
如果是逻辑回归,需要对每一张图片输出数值进行softmax操作,将神经网络的数值变成一个概率,然后通过相关的操作,就可以得到每一张图片最大概率的那个索引就是实际上图片的预测分类标签值
# 假设x就是需要预测的batch_size张图像
x = torch.randn(batch_size,3,32,32)
# 得到神经网络输出后的数值
output = net(x)
# 将数值变成概率
output = F.softmax(output)
# 希望得到最大概率值及其索引
values,index = output.max(dim=1)
# 其中values是每一维的输出最大值
# tensor([0.1120, 0.1110, 0.1096, 0.1108, 0.1110, 0.1104, 0.1109, 0.1127, 0.1097,
# 0.1135], grad_fn=)
# index是输出最大值的索引,也就是预测分类的标签
# tensor([4, 8, 8, 4, 8, 4, 8, 4, 8, 8])
# 此时获得了最大的分类标签便可以预测出其是哪一类
2.AlexNet

# 设置批训练大小
batch_size = 10
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet,self).__init__()
# 五层卷积层
self.conv_layer = nn.Sequential(
# input:torch.Size([batch_size, 3, 32, 32])
# C1层: 卷积-->ReLU-->池化-->归一化
nn.Conv2d(in_channels=3,out_channels=48,kernel_size=3,stride=1,padding=1), # torch.Size([batch_size, 48, 32, 32])
nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # torch.Size([batch_size, 48, 16, 16])
nn.ReLU(),
nn.BatchNorm2d(48),
# C2层: 卷积-->ReLU-->池化-->归一化
nn.Conv2d(in_channels=48,out_channels=128,kernel_size=3,stride=1,padding=1), # torch.Size([batch_size, 128, 16, 16])
nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # torch.Size([batch_size, 128, 8, 8])
nn.ReLU(),
nn.BatchNorm2d(128),
# C3层: 卷积-->ReLU
nn.Conv2d(in_channels=128,out_channels=192,kernel_size=3,stride=1,padding=1), # torch.Size([batch_size, 192, 8, 8])
nn.ReLU(),
# C4层: 卷积-->ReLU
nn.Conv2d(in_channels=192,out_channels=192,kernel_size=3,stride=1,padding=1), # torch.Size([batch_size, 192, 8, 8])
nn.ReLU(),
# C5层: 卷积-->ReLU-->池化
nn.Conv2d(in_channels=192,out_channels=128,kernel_size=3,stride=1,padding=1), # torch.Size([batch_size, 128, 8, 8])
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # torch.Size([batch_size, 128, 4, 4])
)
# output:torch.Size([batch_size, 128, 4, 4])
# 两层全连接层
self.fullconn_layer = nn.Sequential(
# input:torch.Size([batch_size, 2048])
# 全连接层FC6:全连接 -->ReLU -->Dropout
nn.Linear(128*4*4,2048),
nn.ReLU(),
nn.Dropout(p=0.5),
# 全连接层FC7:全连接 -->ReLU -->Dropout
nn.Linear(2048,2048),
nn.ReLU(),
nn.Dropout(p=0.5),
# 输出层
nn.Linear(2048,10),
)
def forward(self,x):
output = self.conv_layer(x) # output:torch.Size([batch_size, 128, 4, 4])
# output = output.view(batch_size,-1) # output:torch.Size([batch_size, 128*4*4])
output = output.view(x.size(0),-1)
output = self.fullconn_layer(output) # output:torch.Size([batch_size, 10])
return output
net = AlexNet()
其中,原始paper中的输入图像是224*224,所以以上的Alexnet是改写的,原始的处理过程如下:
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential( #打包
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55] 自动舍去小数点后
nn.ReLU(inplace=True), #inplace 可以载入更大模型
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27] kernel_num为原论文一半
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
#全链接
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1) #展平 或者view()
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') #何教授方法
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) #正态分布赋值
nn.init.constant_(m.bias, 0)
3.VGG

由于VGG网络有许多个版本,这里以VGG16层版本为例,也就是图中的版本D。
其中ABCDE表示不同深度的网络配置,convx-y中x表示卷积核尺寸,y表示特征通道数,比如conv3-256表示3x3的卷积核并且通道数为256;同理conv1-512表示卷积核3x3通道数为512。
batch_size = 10
class VGG16(nn.Module):
def __init__(self):
super(VGG16,self).__init__()
# 卷积层,含有5大块
self.conv_layer = nn.Sequential(
# block1
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1), # torch.Size([batch_size, 64, 32, 32])
nn.ReLU(),
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1), # torch.Size([batch_size, 64, 32, 32])
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # torch.Size([batch_size, 64, 16, 16])
# block2
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=1), # torch.Size([10, 128, 16, 16])
nn.ReLU(),
nn.Conv2d(in_channels=128,out_channels=128,kernel_size=3,stride=1,padding=1), # torch.Size([10, 128, 16, 16])
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # torch.Size([10, 128, 8, 8])
# block3
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1), # torch.Size([10, 256, 8, 8])
nn.ReLU(),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1), # torch.Size([10, 256, 8, 8])
nn.ReLU(),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1), # torch.Size([10, 256, 8, 8])
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # torch.Size([10, 256, 4, 4])
# block4
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), # torch.Size([10, 512, 4, 4])
nn.ReLU(),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), # torch.Size([10, 512, 4, 4])
nn.ReLU(),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), # torch.Size([10, 512, 4, 4])
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # torch.Size([10, 512, 2, 2])
# block5
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), # torch.Size([10, 512, 2, 2])
nn.ReLU(),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), # torch.Size([10, 512, 2, 2])
nn.ReLU(),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), # torch.Size([10, 512, 2, 2])
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # torch.Size([10, 512, 1, 1])
)
# 全连接层
self.fullconn_layer = nn.Sequential(
# input:torch.Size([10, 512])
# 全连接层FC6:全连接 -->ReLU -->Dropout
nn.Linear(512,4096),
nn.ReLU(),
nn.Dropout(p=0.5),
# 全连接层FC7:全连接 -->ReLU -->Dropout
nn.Linear(4096,4096),
nn.ReLU(),
nn.Dropout(p=0.5),
# 输出层
nn.Linear(4096,10),
)
def forward(self,x):
output = self.conv_layer(x) # output:torch.Size([10, 512, 1, 1])
output = output.view(x.size(0), -1) # output:torch.Size([10, 512])
output = self.fullconn_layer(output) # output:torch.Size([10, 10])
return output
net = VGG16()
# 测试代码
x = torch.randn(batch_size,3,32,32)
output = net(x)
output.shape
其中,原始的输入图像是224*224,所以以上的VGG16是改写的,原始的处理过程为:
参考:https://zhuanlan.zhihu.com/p/87555358
import torch.nn as nn
import torch
class SE_VGG(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
# define an empty for Conv_ReLU_MaxPool
net = []
# block 1
net.append(nn.Conv2d(in_channels=3, out_channels=64, padding=1, kernel_size=3, stride=1))
net.append(nn.ReLU())
net.append(nn.Conv2d(in_channels=64, out_channels=64, padding=1, kernel_size=3, stride=1))
net.append(nn.ReLU())
net.append(nn.MaxPool2d(kernel_size=2, stride=2))
# block 2
net.append(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1))
net.append(nn.ReLU())
net.append(nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1))
net.append(nn.ReLU())
net.append(nn.MaxPool2d(kernel_size=2, stride=2))
# block 3
net.append(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1, stride=1))
net.append(nn.ReLU())
net.append(nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1, stride=1))
net.append(nn.ReLU())
net.append(nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1, stride=1))
net.append(nn.ReLU())
net.append(nn.MaxPool2d(kernel_size=2, stride=2))
# block 4
net.append(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1, stride=1))
net.append(nn.ReLU())
net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))
net.append(nn.ReLU())
net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))
net.append(nn.ReLU())
net.append(nn.MaxPool2d(kernel_size=2, stride=2))
# block 5
net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))
net.append(nn.ReLU())
net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))
net.append(nn.ReLU())
net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))
net.append(nn.ReLU())
net.append(nn.MaxPool2d(kernel_size=2, stride=2))
# add net into class property
self.extract_feature = nn.Sequential(*net)
# define an empty container for Linear operations
classifier = []
classifier.append(nn.Linear(in_features=512*7*7, out_features=4096))
classifier.append(nn.ReLU())
classifier.append(nn.Dropout(p=0.5))
classifier.append(nn.Linear(in_features=4096, out_features=4096))
classifier.append(nn.ReLU())
classifier.append(nn.Dropout(p=0.5))
classifier.append(nn.Linear(in_features=4096, out_features=self.num_classes))
# add classifier into class property
self.classifier = nn.Sequential(*classifier)
def forward(self, x):
feature = self.extract_feature(x)
feature = feature.view(x.size(0), -1)
classify_result = self.classifier(feature)
return classify_result
4.GoogLeNet
亮点:
- 引入了Inception结构(融合不同尺度的特征信息)
- 使用1x1的卷积核进行降维以及映射处理
- 添加两个辅助分类器帮助训练
- 丢弃全连接层,使用平均池化层(大大减少模型 参数)
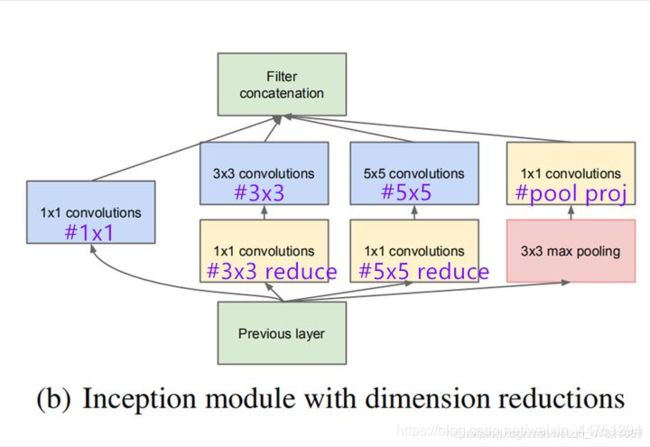

注意:每个分支所得的特征矩阵高和宽必须相同
batch_size = 10
# 定义一个卷积-ReLU结构
class Conv_ReLU(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(Conv_ReLU,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels, out_channels, **kwargs),
nn.ReLU()
)
def forward(self, x):
output = self.model(x)
return output
# 定义incepion结构
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1,ch3x3rd, ch3x3, ch5x5rd, ch5x5, poolproj):
super(Inception,self).__init__()
# 其中Conv_ReLU的stride默认为1,kernel_size根据图标得出,再根据输出的size计算出padding的取值
# 以下4个分支的长宽必须一致
# 分支1
self.branch1 = Conv_ReLU(in_channels, ch1x1, kernel_size=1)
# 分支2
self.branch2 = nn.Sequential(
Conv_ReLU(in_channels, ch3x3rd, kernel_size=1),
Conv_ReLU(ch3x3rd, ch3x3, kernel_size=3, padding=1)
)
# 分支3
self.branch3 = nn.Sequential(
Conv_ReLU(in_channels, ch5x5rd, kernel_size=1),
Conv_ReLU(ch5x5rd, ch5x5, kernel_size=5, padding=2),
)
# 分支4
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
Conv_ReLU(in_channels, poolproj, kernel_size=1)
)
def forward(self,x):
# 以Inception(3a)层为例
output_b1 = self.branch1(x) # torch.Size([10, 64, 4, 4])
output_b2 = self.branch2(x) # torch.Size([10, 128, 4, 4])
output_b3 = self.branch3(x) # torch.Size([10, 32, 4, 4])
output_b4 = self.branch4(x) # torch.Size([10, 32, 4, 4])
# 根据第一个维度进行合并
output = torch.cat([output_b1, output_b2, output_b3, output_b4], dim=1) # torch.Size([10, 256, 4, 4])
return output
# 定义GoogLeNet卷积神经网络(忽略辅助分类器)
class GoogLeNet(nn.Module):
def __init__(self, ):
super(GoogLeNet, self).__init__()
# 卷积层
self.conv_layer = nn.Sequential(
# Conv-Maxpool(忽略LocalRespNorm)
Conv_ReLU(3, 64, kernel_size=7, stride=2, padding=3), # torch.Size([10, 64, 16, 16])
nn.MaxPool2d(kernel_size=3, stride=2, padding=0), # torch.Size([10, 64, 7, 7])
# Conv-Conv-Maxpool(忽略LocalRespNorm)
Conv_ReLU(64, 64, kernel_size=1),
Conv_ReLU(64, 192, kernel_size=3, stride=1, padding=1), # torch.Size([10, 192, 7, 7])
nn.MaxPool2d(kernel_size=3, stride=2, padding=1), # torch.Size([10, 192, 4, 4])
# Inception(3a)
Inception(192, 64, 96, 128, 16, 32, 32), # torch.Size([10, 256, 4, 4])
# Inception(3b)
Inception(256, 128, 128, 192, 32, 96, 64), # torch.Size([10, 480, 4, 4])
nn.MaxPool2d(kernel_size=3, stride=2, padding=1), # torch.Size([10, 480, 2, 2])
# Inception(4a)
Inception(480, 192, 96, 208, 16, 48, 64), # torch.Size([10, 512, 2, 2])
# Inception(4b)
Inception(512, 160, 112, 224, 24, 64, 64), # torch.Size([10, 512, 2, 2])
# Inception(4c)
Inception(512, 128, 128, 256, 24, 64, 64), # torch.Size([10, 512, 2, 2])
# Inception(4d)
Inception(512, 112, 144, 288, 32, 64, 64), # torch.Size([10, 528, 2, 2])
# Inception(4e)
Inception(528, 256, 160, 320, 32, 128, 128), # torch.Size([10, 832, 2, 2])
nn.MaxPool2d(kernel_size=3, stride=2, padding=1), # torch.Size([10, 832, 1, 1])
# Inception(5a)
Inception(832, 256, 160, 320, 32, 128, 128), # torch.Size([10, 832, 1, 1])
# Inception(5b)
Inception(832, 384, 182, 384, 48, 128, 128), # torch.Size([10, 1024, 1, 1])
# 自适应层,无论维度多少都可以通过AdaptiveAvgPool2d变成长宽比为1:1
nn.AdaptiveAvgPool2d((1,1)), # torch.Size([10, 1024, 1, 1])
)
# 全连接层
self.fullconn_layer = nn.Sequential(
nn.Dropout2d(p=0.4),
nn.Linear(1024, 10) # torch.Size([10, 10])
)
def forward(self,x):
output = self.conv_layer(x) # output:torch.Size([10, 1024, 1, 1])
output = output.view(x.size(0), -1) # output:torch.Size([10, 1024])
output = self.fullconn_layer(output) # output:torch.Size([10, 10])
return output
# 测试shape代码
net = GoogLeNet()
x = torch.randn(batch_size,3,32,32)
output = net(x)
output.shape
以上的GoogLeNet为32*32的的图像分类网络所搭建,没有辅助分类器。可以参考https://www.jianshu.com/p/a0bdab69b423 或 https://zhuanlan.zhihu.com/p/185025947
以1000分类为例,原始的GoogLeNet网络结构,含辅助分类器结构如下代码:
# GoogLeNet网络结构
class GoogLeNet(nn.Module):
# 其中aux_logits表示是否使用辅助分类器,init_weights表示是否进行权重初始化
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
# 如果开启辅助分类器会进行如下操作
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
# 如果开启初始化权重会进行如下操作
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
# 权重初始化操作
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# Inception结构
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
# 辅助分类器
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
# 卷积ReLu函数
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
5.ResNet
亮点:
-
超深的网络结构
-
提出resiual模块
-
使用Batch Normalization加速训练(丢弃dropout)
ResNet中两种基本的残差快结构:
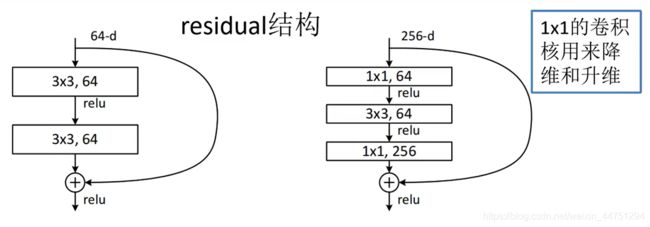
左边的结构使用与50层以下的网络;右边的结构使用与50层以上的网络


以下以实现Res18为例:
batch_size = 10
# 定义一个残差模块基本结构
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(ResBlock,self).__init__()
# 两层卷积输出
self.model = nn.Sequential(
nn.Conv2d(in_channels, in_channels, stride=2, **kwargs),
nn.BatchNorm2d(in_channels), # torch.Size([10, 64, 8, 8])
nn.ReLU(),
nn.Conv2d(in_channels ,out_channels, stride=1, **kwargs),
nn.BatchNorm2d(out_channels), # torch.Size([10, 128, 8, 8])
)
# 直接来至输入的一个卷积
self.extra = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2, bias=False),
nn.BatchNorm2d(out_channels) # torch.Size([10, 128, 8, 8])
)
def forward(self, x):
# 首先得到一个基本卷积后的输出
output = self.model(x)
# 将卷积后的输出与输入进行一个残差相加
output += self.extra(x)
# 再通过激活函数
output = F.relu(output) # torch.Size([10, 128, 8, 8])
return output
# 残差网络
class ResNet(nn.Module):
def __init__(self):
super(ResNet,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64), # # torch.Size([10, 64, 16, 16])
ResBlock(64, 128, kernel_size=3, padding=1, bias=False), # torch.Size([10, 128, 8, 8])
ResBlock(128, 256, kernel_size=3, padding=1, bias=False), # torch.Size([10, 256, 4, 4])
ResBlock(256, 512, kernel_size=3, padding=1, bias=False), # torch.Size([10, 512, 2, 2])
ResBlock(512, 512, kernel_size=3, padding=1, bias=False), # torch.Size([10, 512, 1, 1])
nn.AdaptiveAvgPool2d((1,1))
)
self.outlayer = nn.Linear(512, 10)
def forward(self, x):
output = self.model(x) # torch.Size([10, 512, 1, 1])
output = output.view(x.size(0), -1) # torch.Size([10, 512])
output = self.outlayer(output) # torch.Size([10, 10])
return output
# 测试代码
net = ResNet()
x = torch.randn(batch_size,3,32,32)
output = net(x)
output.shape