图神经网络七日打卡营学习心得
图神经网络七日打卡营学习心得
- 1、学习内容总结
-
- Day1:图学习出印象
-
- 1.1、图学习背景介绍
- 1.2、 图学习任务分类
- 1.3、图学习算法分类
- 1.4、配置环境实例
- Day2:图游走类算法
-
- 2.1目标
- 2.2引入——Word2vec介绍
-
- Skip—Gram
- Negative sampling
- Word2ve:整体框架
- 2.3图游走模型
-
- 2.3.1 DeepWalk
- 2.3.2、node2vec
- 2.3.4 meatpath2vec
- Day3:图神经网络算法(一)
-
- 3.1图卷积神经网络(GCN)
-
- 3.1.1图结构卷积
- 3.1.2图卷积神经网络总结
- 3.1.3计算公式
- 3.2图注意力网络(GCN)
- 3.3消息传递(Message Passing)
- Day4:图神经网络算法(二)
-
- 4.1图采样(邻居采样)
-
- 4.1.1进行图采样的原因
- 4.1.2图采样算法
-
- 4.1.2.1GraphSage
- 4.1.2.2PinSage
- 4.1.3图采样的优点
- 4.2图采样之后-邻居聚合
-
- 4.2.1常用聚合函数
- 4.2.2基于单射的GIN模型
- Day5:GNN进阶模型
-
- 5.1ERNIESage模型
-
- 5.1.1模型提出背景
- 5.1.2ERNIESage Node
- 5.1.3ERNIESage Edge
- 5.1.4ERNIESage 1-Neighbor
- 5.2UniMp
- 2、总结
- 3、附录
1、学习内容总结
Day1:图学习出印象
1.1、图学习背景介绍
随着AI的推广,深度学习已经成为了当下最热的一个研究领域,推出了许多神经网络模型比如CNN(卷积神经网络),RNN(递归神经网络等),但是这些网络处理的数据都是规则的欧氏空间的数据,而且默认数据之间互相独立。但是现实生活中的应用场景有许多数据都是不规则的,并且数据与数据之间有很多的联系,这样就给传统的神经网络模型引入了很大的挑战,因为这对于它们来说数据过于复杂,并且无法利用数据之间的关系。因此图神经网络的提出就很好的解决了这一问题,它可以很方便的处理不规则数据,并且能够很充分利用图结构。
1.2、 图学习任务分类
图学习的任务呢可以主要分为三类:
1、节点级别任务:例:金融诈骗检测(节点分类)
2、边级别任务:例:推荐系统(边预测任务)
3、图级别任务:例:气味识别
1.3、图学习算法分类
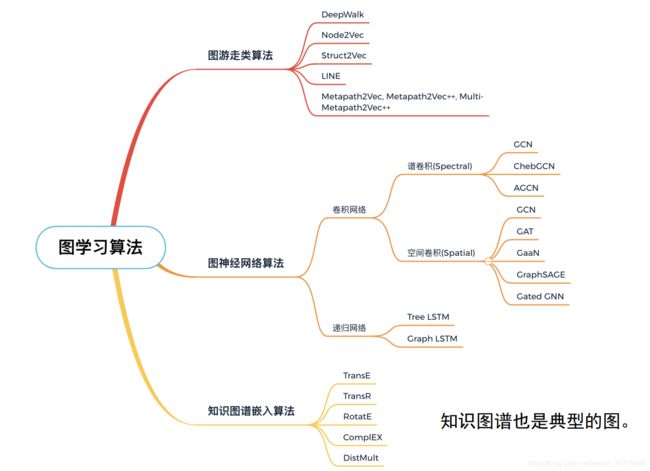
此图片来源于:https://baidu-pgl.gz.bcebos.com/pgl-course/lesson_1.pdf
1.4、配置环境实例
因为本身自己不是计算机专业的人,所以在进行本地的paddlepaddle框架配置时,着实费了很大的功夫,多亏了学习群中答疑老师以及同学的帮忙才配置成功,这里贴一个paddle框架的配置网址,以及常见问题及解决方法的文档:
- paddle框架安装及教程
- 配置环境常见问题整理
Day2:图游走类算法
2.1目标
通过图游走类算法主要的目标就是:Node embeddings(得出每个节点的向量表示),得出向量表示后,便可以将其作为输入,用于进行下游任务(如:节点分类)
2.2引入——Word2vec介绍
NLP领域—Word2vec:使用一层神经网络将one-hot(独热编码)形式的词向量映射成为分布形式的词向量。最后使用Hierarchical softmax,negative sampling等技巧进行训练速度上的优化
图游走模型最开始参考的就是NLP领域的Word2vec算法
Skip—Gram
word2vec主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式,这里我们主要用的是第二种,Skip-Gram—根据中心词来预测上下文。
Negative sampling
因为word2vec模型运用时,数据很庞大,为了加速模型,可以通过**Negative sampling(负采样)**算法来加速。
Word2ve:整体框架
sentences——> Skip-Gram +Negative sampling
注意:我们最重要的其实是这个模型运算的副产物—词的向量表示
这部分当时看的时候较为粗略,大家可以认真看一下这部分,它是图随机游走模型的基础,这里有个Word2vec介绍:word2vec的通俗理解
2.3图游走模型
2.3.1 DeepWalk
选择下一个节点的方法——均匀随机采样
用公式表示:

相比较于Word2vec ,此模型多加了一个步骤,即句子本身就是一个序列,而DeepWalk要通过随机游走来形成一个个序列用于输入
整体框架
Graph——> Random Walk+Skip-Gram +Negative sampling
2.3.2、node2vec
bias random walk:在考虑游走时,加入了两个超参数p,q来使得可以对较为复杂的图有个较好的节点表示
公式表示

整体框架
Graph——> BIas Random Walk+Skip-Gram +Negative sampling
2.3.4 meatpath2vec
对异构图的一个随机游走模型,随机游走时,以meta path(元路径)为输入序列
整体框架
Graph——>Meta path based Random Walk+Skip-Gram +Negative sampling
Day3:图神经网络算法(一)
3.1图卷积神经网络(GCN)
3.1.1图结构卷积
将一个节点周围的邻居按照不同的权重叠加起来。
3.1.2图卷积神经网络总结
图卷积神经网络其实就是,通过消息传递的机制,对邻居节点的信息的接受和加权聚合来更新当前节点的表示,而这个权重取决于邻居节点的度,其值越大,权重越小,即对当前节点的影响越小。
3.1.3计算公式

A-邻接矩阵(带自环边)
D-度矩阵
H^l-每一层的节点表示
3.2图注意力网络(GCN)
与GCN不同的点在于:1、进行消息传递时,节点的权重变成了节点之间的函数;2、权重与两个节点的相关性有关;3、权重可学习
公式表示:

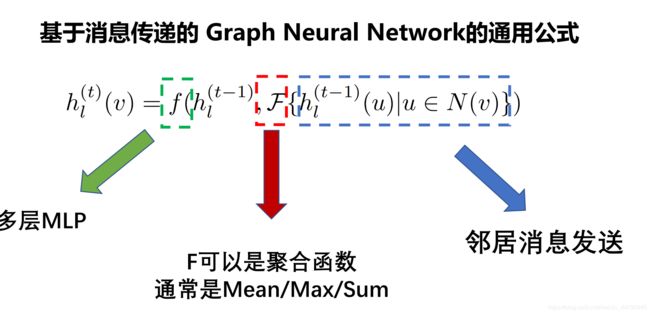
3.3消息传递(Message Passing)
消息传递是图神经网络的一个很重要的机制,它包括了邻居节点对当前节点的消息的发送(Send),以及当前节点对邻居节点所发送消息的接受(Recv),并且对其聚合
当前主流的图神经网络模型都是基于消息传递机制的,因此得对这部分了解透彻。
公式表示
Day4:图神经网络算法(二)
4.1图采样(邻居采样)
定义:在一张复杂的图中进行采样,得到一张子图。(子图采样,不是随机采样)
4.1.1进行图采样的原因
当前图数据量级太大,而我们的计算资源有限。无法一次性全图送入计算资源,而且图结构数据的节点表示的更新都要通过其邻居节点的信息,随着神经网络的加深,迭代次数增多,每次处理的数据的batch size会指数性增长,因此需要通过图采样,来对数据进行Mini-Batch的处理。
4.1.2图采样算法
4.1.2.1GraphSage
从中心节点开始,先对一阶邻居节点进行随机采样。然后以被采样的一阶邻居节点为新的中心节点,对二阶邻居节点进行采样,以此类推,因此邻居采样是由中心节点出发逐渐向外层邻居节点采样的。
4.1.2.2PinSage
与GraphSage的区别是:它是通过随机游走,按游走经过的频率来选择邻居节点。(采样得到的邻居节点可以是虚拟邻居)
4.1.3图采样的优点
- 极大地减少了训练计算量
- 允许泛化到新的连接关系(泛化能力加强)
4.2图采样之后-邻居聚合
4.2.1常用聚合函数
- Mean-倾向学分布-非单射
- Max-倾向于忽略重复值-非单射
- Sum-可以保留完整信息-单射
评估聚合表达能力的指标-单射(一对一映射)
单射可以保证聚合后的记过可以区分
4.2.2基于单射的GIN模型

GIN模型的优点:当中心节点与邻居节点互换时聚合结果仍然可以区分:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2X9129XN-1606555218262)(https://img-blog.csdnim文本图g.cn/20201128171839781.PNG?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDc5Njk0NQ==,size_16,color_FFFFFF,t_70#pic_center)]
Day5:GNN进阶模型
5.1ERNIESage模型
5.1.1模型提出背景
背景介绍:当前很多的实际应用场景的图结构都是Text Graph(文本图),即节点和边都带有文本的特殊图。
对这种图进行建模时,用GraphSage只能对其结构进行建模,却忽略了节点和边所带的文本信息,而如果通过ERNIE模型(百度提出的语义理解模型)只能对其文本信息进行理解,运用任何一种模型建模都是不完善的,因此提出了一种新的模型ERNIR Sage模型(图语义理解模型)
5.1.2ERNIESage Node
定义:将ERNIE 作用于Text Graph的Node上
过程以及表示

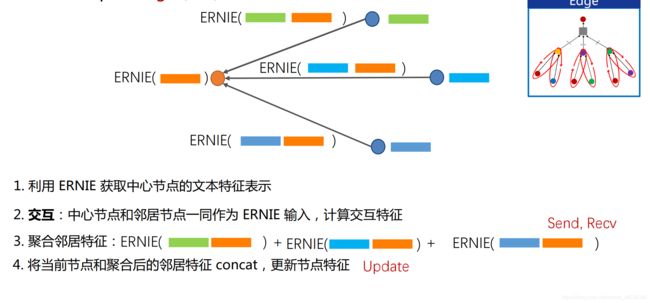
5.1.3ERNIESage Edge
定义:将ERNIE 作用于Text Graph的Edge上。
过程以及表示
5.1.4ERNIESage 1-Neighbor
定义:将ERNIE 聚合节点的 **1-Neighbor(一阶邻居)**信息
过程:将中心节点的文本于所有一阶邻居节点的文本进行单塔拼接,再利用ERNIE做消息聚合
5.2UniMp
具体介绍可以看PGL团队的GitHub中的介绍,后边放上链接。
2、总结
作为硬件专业的学生,由于课题原因第一次接触图神经网络,在进行打卡学习之前加班学习了两天Python,因此整个学习过程对我来说还是颇为困难的。但是经过这几天的打卡学习呢,确实对图神经网络有了一些初步的认识,因为不仅有理论上的介绍,还可以在AI stdio中进行实战演练,对图神经网络的认识就会更加深刻一些。虽然课程完结了,但是对于我自己来说仅仅是有了一个入门了解,通过这次学习我也发现了自己在有些方面的知识的缺失,后续会慢慢补过来。
这次是我第一次写一个博客,写得十分粗糙,本来只是想对七日打卡的学习进行一个总结,结果繁琐却又粗略的介绍了一下自己这几天的所学内容,后边我会继续深入学习图神经网络的相关知识,等到有一定的知识储备之后,希望能基于此次学习的基础上,可以以自己一个完全小白的视角写一篇入门图神经网络的学习经验贴,以及自己的一些感悟,希望可以帮助到其他像我一样的人。
3、附录
所有的图片都来自于七日打卡营的课程的ppt:
https://github.com/PaddlePaddle/PGL/tree/main/course
课程相关的实战学习,以及一些模型的代码(基于paddlepaddle框架,具体下载以及环境配置可看上文):https://github.com/PaddlePaddle/PGL