2020-12-06
nlp = nlu + nlg
1、应用场景
QA
sentiment analysis:股票价格预测,舆情监控,产品评论,事件监测
Machine translation:机器翻译
text summarization:自动摘要
chatbot
information extraction:信息抽取
2、关键技术
semantic 语义:nlu
syntax 句子结构:句法分析,依存分析
morphology 单词:分词,pos(词性标注),ner
phonoetics 声音
word segmentation(分词)
part of speech(词性)
name entity recognition(命名实体识别)
relation extraction(关系抽取)
3、o(n)时间复杂度
4、node2rec,knowledge graph
5、master theorem
T(n) = 2T(n/2)+n
T(n) = aT(n/b) + f(n)
O() = f(n^logb\a) ? f(n)
16T(n/4)+n
f(n^2) ? f(n)
f(n^2)
o(n^logb\a)>f(n) => o(n^logb\a)
o(n^logb\a)=f(n) => o(n^logb\a logn )
o(n^logb\a)
------------------------------------
问答系统
1、语料库
知识库
1、预处理:拼写纠错;原型处理;停用词过滤;字符过滤;同义词;
2、文本表示:tf-idf;word2vec;seq2seq
3、计算相似度: eurdiso distance;cosin ; jascial ;
4、排序-》过滤-》返回结果
现有方法:文本表示,相似度
知识图谱:实体抽取,关系抽取
2、巴普洛夫的狗(行为主义理论)
狗吃饭的时候放一个固定的声音,狗就对声音有反应了
泛化:过拟合?
分化:辨别,对原有条件细化
3、斯金纳的老鼠
强化学习:环境 《--反馈---》老鼠,老鼠最终学会使用哪些action
对于同一action,环境的反应应该是一致的
4、hubel and wiesel 的猫
5、原始文本
-》分词
-》清洗(无用标签,特殊符号,停用词,大小写转换)
-》标准化(英文需要,中文不大,stemming, lemmazatic)
-》特征提取(tf-idf,word2vec)
-》建模(相似度算法,分类算法)
5.1 word segmentation分词:jieba,snownlp,ltp,hannlp,匹配规则的方法
jieba.lcut("yangjinyong xxxxxxx", cut_all=False)
jieba.add_word("yangjinyong")
jieba.lcut("xxxxxxx", cut_all=False)
前向最大匹配 forward-max matching: max_len = 5窗口最大5
我们经常有意见分歧 -》我们,经常,有意见,分歧
字典:我们,经常,有,有意见,意见,分歧
贪心算法:当前最优解 ?
dp:全局最优 ?
后向最爱匹配:
-》我们,经常,有意见,分歧
匹配优缺点:局部最优,效率低
5.2 incorporate semantic(考虑语义):对生成的分词打分,选择最高分,概率统计方法
经常有意见分歧
词典:有,有意见,意见,分歧,见,意
输入-》生成所有可能的分隔-》选择其中最好的
工具-》语言模型(LM)
p(s1) = 0.3 p(经常,有,意见,分歧)=p(经常).p(有).p(意见).p(分歧)=0.3
p(s2) = 0.35 p(经常,有意见,分歧)=p(经常).p(有意见).p(分歧)=0.35
一般:log p(s1) = log p(经常) + log p(有) + log p(意见) + log p(分歧)
优缺点:复杂度高
5.3 viterbi 算法:本质dp
词典:经常,经, 有,有意见,意见,分歧,见,意,见分歧,分
概率:0.1 0.05 0.1 0.1 0.2 0.2 0.05 0.05 0.05 0.1
-log:2.3 3 2.3 2.3 1.6 1.6 3 3 3 2.3
s 经 3 常 20 有 2.3 意 3 见 3 分 2.3歧 20 end
----2.3-|--------2.3------|------1.6---------|
|------1.6--|
|-------------3--------- |
f(8) 反向动态规划:
f(8) = f(7)+20
f(6) +1.6
f(5)+3
f(7)=f(6)+2.3
f(6)=f(3)+23
f(4)+2.3
f(5)+3
...
6、spell correction(拼写错误纠正)
6.1 编辑距离edit distance ?
therr there replace 1
their repalce 1
thesis repalce 2, add 1
theirs add 2
the del 2
dp算法核心: big problem ->smaller problem
nlpcamp & github
6.2 alternative way
输入
-》生成编辑距离为1,2的字符串, add a char ,del a char, replace a char
-》过滤-》返回
bayes: ?
p(x|y) = p(y|x).p(x)/p(y)
p(x,y)=p(x|y).p(y) = p(y|x).p(x)

p(x) -- 先验概率
p(x|y) -- 条件概率/后验概率
联合概率:P(AB)=P(A)P(B|A)=P(B)P(A|B)
条件概率:P(A|B)=P(AB)|P(B)
贝叶斯公式:P(B|A)=P(A|B)P(B)/P(A)
p(s|c):对于一个字符串c,有百分之多少的人写成s
p(c):unigram probbility
7、filtering words
停用词,出现频率低的词汇过滤掉
英文:the,an,their...
需要考虑场景,比如情感分析(很重要)对 :好,很好
标准化:stemming
went,go,going -> go
fly,flies ->fli
deny,denied,denying->deni
fast,faster,fastest->fast
lemmozation,porter stemmer 规则《-》语言学家
------------------------------------------------------------------------------------
8、word representation(one hot)
词典:我们,去,爬山,今天,你们,昨天,跑步
我们:1,0,0,0,0,0,0 one hot
爬山:0,0,1,0,0,0,0
跑步:0,0,0,0,0,0,1
昨天:0,0,0,0,0,1,0
我们今天去爬山 1,1,1,1,0,0,0 boolean
你们又去爬山又去跑步 0,2,1,0,1,0,1 count 并不是出现的越多就越重要
9、相似度
欧氏距离:d=|s1-s2|
s1=(x1,x2,x3)
s2=(y1,y2,y3)
d=((x1-y1)^2+(x2-y2)^2+(x3-y3)^2)^1/2 = sim(s1,s2 )
s1=我们今天去爬山 = 1,0,1,1,0,0,0,0
s2=你们昨天跑步= 0,0,0,0,1,0,1,1
余铉相似度:d=s1.s2/(|s1|*|s2|) = (x1y1+x2y2+x3y3)/((x1^2+x2^2+x3^2)^1/2 .(y1^2+y2^2+y3^2)^1/2)
内积/normalization
越大越相似
10、tf-idf = tf(d,w)*idf(w)
tf(d,w) 文档d中w的词频 ------ 本文中词语出现次数, conut
idf(w) log(N/N(w)) N:语料库中的文档总数,N(w)词语w出现在多少个文档
词典:今天,上,nlp,课程,的,有,意思,数据,也
今天上Nlp课程
今天的课程有意思
数据课程也有意思
1.log(3/2),1.log(3/1),1.log(3/1),1.log(3/3),0,0,0,0,0
1.log(3/2),0,0,1.log(3/2),1.log(3/1),1.log(3/2),0,0
one-hot:boolean,count,tf-idf
12、one-hot不合适:单词相似度;稀疏性 sparcy
distributed representation 分布式表示:词向量(word vectors)
我们:[0.1,0.2,0.4,0.2]
爬山:[0.2,0.3,0.7,0.1]
运动:[0.2,0.3,0.6,0.2]
昨天:[0.5,0.9,0.1,0.3]
欧氏距离:d(我们,爬山)=(0.1^2+0.1^2+0.3^2+0.1^2)^1/2 = 0.12^1/2
--------------------------------------------------------
深度学习模型 --> 词向量 dim 100/200/300/50
skip-gram
glone
cbow
rnn/lstm
mf
词向量代表单词的意思
句子向量 = 词向量相加的平均值
---------------------------------------------------------------------------------------------------------
12.8
QA system
question ------------相似度匹配-----------------》知识库
《----------返回相似度高的--------------
O(N) ---> 层次过滤思想 ----------> 100*过滤器 + 10*cosinesimlar
输入 ----》 过滤1(快) ----》 过滤2(稍复杂) ----》 cosin simlar
复杂度1《复杂度2《cosin
inverted index(倒排表):
doc1: 我们,今天,运动
doc2: 我们,昨天,运动
doc3:你们,上课
doc4: 你们,上,什么,课
我们:doc1,doc2
今天:doc1
运动:doc1,doc2
昨天:doc2
上: doc3,doc4
课:doc3,doc4
什么:doc4
用户输入:我们上课
过滤1后:doc1,doc2,doc3,doc4
--------------------------------------
noisy channel model
p(text|source) ---》 p(source|text)p(text)
语音识别,机器翻译,拼写纠错,OCR,密码破解
机器翻译: p(中文|英文) p(英文|中文).p(中文)
拼写纠错:p(正确的写法|错误的写法) p(错误的写法|正确的写法).p(正确的写法)
语音识别:p(文本|语音信号) p(语音信号 | 文本).p(文本)
密码破解:p(明文|密文) p(密文|明文).p(明文) 语言模型
Language Model 语言模型:一句话是否通顺
今天是周日 VS 今天周日是
全民AI是趋势 VS 趋势全民AI是
目标:p(s)=p(w1,w2,w3,w4...)
-----------------------------------------------------------------------------------------------
chain rule:
p(a,b,c,d) 联合概率
=p(a)p(b|a)p(c|a,b)p(d|a,b,c)
=p(a,b)p(c|a,b)p(d|a,b,c)
=p(a,b,c)p(d|a,b,c)
=p(a,b,c,d)
p(今天,是,春节,我们,都,休息)
=p(今天)p(是|今天)p(春节|今天,是)p(我们|今天,是,春节)p(都|今天,是,春节,我们)p(休息|今天,是,春节,我们,都)
sparsity -> markov assumption马尔科夫假设
p(休息|今天,是,春节,我们,都)
约= p(休息|都) --- 1st order markov assumpthon
= p(休息|我们,都) --- 2nd order
= p(休息|春节,我么,都) --- 3rd
p(w1,w2,w3,w4,...wn)
= p(w1)p(w2|w1)p(w3|w2)p(w4|w3)...p(wn|w(n-1)) 1st order
= p(w1)p(w2|w1)p(w3|w1,w2)p(w4|w2,w3)...p(wn|wn-2wn-1) 2nd order
LM: unigram 相互独立,不考虑单词的顺序,不好
p(w1,w2,w3,w4,...wn)
=p(w1)p(w2)p(w3)...p(wn)
p(今天,是,春节,我们,都,休息)
=p(今天)p(是)p(春节)p(我们)p(都)p(休息)
bigram: 1st order:考虑一个单词的顺序,较好
p(今天,是,春节,我们,都,休息)
=p(今天)p(是|今天)p(春节|是)p(我们|春节)p(都|我们)p(休息|都)
n-gram: higher order , >2
p(w1,w2,w3,w4,...wn)
= p(w1)p(w2|w1)p(w3|w1,w2)p(w4|w1,w2,w3)...p(wn|w(n-3)w(n-2)w(n-1)) 3 order
-------------------------------------------------------------------------
bigram:
语料库:带有词语顺序
今天,的,天气,很好,啊
我,很,想,出去,运动
但,今天,上午,想,上课
训练营,明天,才,开始
p(今天 上午 想 出去 运动)
=p(今天)p(上午|今天)p(想|上午)p(出去|想)p(运动|出去)
=2/19 * 1/2 * 1* 1/2 * 1 = 1/38
n-gram:
今天,上午,的,天气,很好
我,很,想,出去,运动
但,今天,上午,有,课程
训练营,明天,
p(今天 上午 有 课程)
=p(今天)p(上午|今天)p(有|今天,上午)p(课程|上午,有)
= 1/19 * 1 * 1/2 * 1
--------------------------------------------------------
-----------------------------------------------
评估:x越大越好,perplexity越小越好;
perplexity = 2^(-x) x:average log likelyhood (unsurpressed)
训练好的bigram
p(天气|今天)=0.01 log p(天气|今天)= -2
p(今天)=0.002 log p(今天) = a1
p(很好|天气)=0.1 log p(很好|天气) = -1
p(适合|很好)=0.01 log p(适合|很好) = -2
p(出去|适合)=0.02 log p(出去|适合) = a2
p(运动|出去)=0.1 log p(运动|出去) = -1
x=(a1-2-1-2+a2-1)/6 假设 -2
perplexity= 2^(-x) = 4
------------------------------------------------------------------------------------
add-one smoothing:
Pa1(wi|wi-1) = (c(wi-1,wi)+1)/(c(wi)+v) ---- v 单词总数量
语料库:
今天 上午 的 天气 很好
我 很 想 出去 运动
但 今天 上午 有 课程
训练营 明天 才 开始
pa1(上午|今天) = (2+1)/(2+17)
pa1(的|今天) = (0+1)/(2+17)
add-k smoothing:
pak(wi|wi-1) = (c(wi-1,wi) +k)/(c(wi)+kv) 与上类似
k=3
pa3(上午|今天)= (2+3)/(2+3*17)
选择k: k=1,2,3,4...;优化 f(k)
interpolation: C count ,加权平均,tri-gram : 1gram,2gram
C(in the kitchen)=0
C(the kitchen) = 3 p(kitchen | in the) = ?
C(arboretum)=0 p(arboretum | in the ) = ?
C(ktichen) = 4
p(wn| wn-1, wn-2) = r1p(wn|wn-1,wn-2)
+ r2p(wn| wn-1)
+ r3p(wn)
r1+r2+r3=1
goo-turning smoothing
good-turning smoothing:
调到18条鱼:10鲤鱼,3黑鱼,2刀鱼,1鲨鱼,1草鱼,1鳗鱼
q1:下一次是鲨鱼概率? 1/18
q2:下一条是新鱼种概率? 3/18
q3:重新想一下,下一条是鲨鱼概率?
Nc出现c次的单词的个数
Sam i am i am sam i do not eat
sam 2
i 3
am 2
do 1
not 1
eat 1
-> N3=1,N2=2,N1=3
没有出现过的单词:Pmle = 0, Pgt = N1/N
Pmle(飞鱼) = 0/18
Pgt(飞鱼) = N1/N = 3/18
出现过的单词 : Pmle = c/N, Pgt = (c+1)Nc+1/Nc 出现次数
Pmle(草鱼) = 1/18
Pgt(草鱼) = (1+1)N2/N1N = 2*1/3*18
一般:Pgt < Pmle
q:缺点?怎么解决?
第n次的数据依赖于第n+1次,如果n+1次为0,怎么办?
使用图线平滑的方法把缺失的数据补上
----------------------------
最大子序列
最大增数列
凑零钱
01背包,sv
编辑距离
---------------------------------------------------
word2vec:
cbow,skip-gram,
glove(local, global)
sparse not sparse
0,1,0 (0,1):1
0,0,3 (1,2):3
0,0,0
jupyter
----------------------
spell-correction :
错误输入:s
正确写法:c
max p(c|s) = p(s|c)p(c)/p(s) 约= p(c)p(s|c)
def generate_candidates(word):
letters = 'abcdefghijklmnopqrstuvwxyz'
splite=[(word[:i],wor[i:]) for i in range(len(word)+1)]
i
insets=[l+c+r for l,r in splits for c in letters]
deletes = [l+r[1:] for l,r in splits if r]
replase=[l+c+r[1:] for l,r in splites if r for c in letters]
cand = set(inserts+deletes+replace)
reutrn [word for word in cand if word in vocab]
print(splits)
词典库:
vocab = set([line.rstrip() for line in open('vocab.txt')])
from nltk.corpus import reuters
categories = reuters.categories() 读语料库
corpus= reuters.sents(categories=categories)
语言模型 bigram
term_count={}
for doc in corpus:
doc = [''] + doc 开头标记
for i in range(0,len(doc)-1):
term = doc[i]
bigram = doc[i:i+2]
if term in term_count:
term = doc[i]
bigram= doc[i:i+2]
channel_prob = {}
for line in open('spell-error.txt'):
items = line.split(":")
correct = items[0].strip()
mistakes = [item.striip() for item in items[1].strip().split(",")]
channel_prob[correct] = {}
for mis in mistakes:
channel_prob[correct][mis] = 1/len(mistakes)
print(channel_prob)
v = len(term_count.keys())
file = open("testdata.txt",'r')
for line in file:
items = line.rstrip().split('\t')
line = items[2].split()
// line = {'i', 'like','apple'}
for word in line:
if word not in vobab:
candidates = generate_cand(word)
probs = []
for candi in candidates:
prob = 0
if candi in chanel_prob and word in chanel_prob[candi]
prob += np.log(chanel_prob[cnadi][word])
else:
prob += np.log(0.0001)
idx = items[2].index(word)+1
if items[2][idx-1] in bigram_count and candi in bigram_count[itms[2][idx-1]]
prob += np.log(bigram_count[items[2][idx-1]][candi]+1)/
(term_count[bigram_count[items[2][idx-1]]] +v)
else:
prob += np.log(1/v)
probs.append[prob]
max_idx = probs.index(max(probs))
print(wrod, candistates[max_idx])
i like play football
prob = log (p(plag|like)p(football|play) )= 0.000001
1、语言模型
if prob < threshodl:
xxxxx
2、训练一个分类器
---------------------------------------------------------------------------------------------------------------------------------------------------------------
生成模型:
unigram model
vocab: NLP,I,like, studying,course,yesterday
0.1 0.3 0.2 0.2 0.35 0.05
i studying nlp course i yesterday
bigram nodel
vocal matrix:
nlp i like study corese yesterday .
i
like
study
corese
yesterday
.
矩阵系数决定生成单词顺序的概率,i like studying nlp corese yesterday.
-----------------------------
two main branches of learning
专家系统:符号注意 if condition1: then do sth1
基于概率的系统:连接主义 D={X,Y}, f: x->y
数据量:少,没有 -》专家系统
大量 -》概率设计的系统
--------------------------------
专家系统:
推理引擎 + 知识
全球第一个专家系统 dendral,斯坦福大学开发与70年代
working flow:
专家 -》 输出 经验 -》 知识工程师 -》知识 转化 -》知识库
算法工程师 -》推理 引擎 -》 working storage / 知识库 -》终端用户
搭建金融知识图谱:
金融专家/风控专家 -》 经验(实体,关系。。。) -》知识图谱工程师 -》 构建知识图谱 -》图数据库
AI工程师/nlp工程师 -》 推理层 -》
图数据库 -》 api -> 业务
特点:处理不确定性、知识表示(知识图谱,非结构化-》结构化)、可解释性、可以做知识推理
推理逻辑:
rule1 : if a and c then f
rule2 : if a and e tehn g
b e
g d
证明: if a and b, then d
---------------
forward chaining:
rule3 -> e true
rule2 -> e,g true
e,g,d true
---------------
backward chaining:
d -> a,b
rule4 -> g
rule2 -> a,e
rule3 -> a,e,b
-----------------------------------
缺点:
设计大量规则
需要领域专家来主导
可移植性差
学习能力差
人能考虑的范围有限
-----------------------------------------------------------------------------------------
case study : risk control
问题:根据用户的信息,决定要不要放贷
rule engine:
1. if age < 18,reject -1
2. if wage <3000, reject -2
3. if city = "xxx",reject -0.5
4. if experense < 100, reject -3
--------------------------------
一些难题:
逻辑推理 Logical inference
forward chaining
backward chaining
解决规则冲突 conflict resolution
不同人有不同的规则,甚至同一个人的规则有冲突
选择最小规则的子集 minimum size of rules
规则去重
AI不确定性很高
step1:找出一个类似的 ‘经典’ 问题
ie. minum siz of rule set <--- set cover problem
step2: read papers (about se cover problem)
---------------------------------------------------------------------
基于概率的系统
给定数据 D = {x, y}
学习x到y的映射关系
ML:自动从已有的数据里找出一些规律,然后把学到的这些规律应用到对未来数据的预测中,或者在不确定环境下自动做一些决策
supervised learning unsupervised learning
generative model
生成模型 naive bayes HMM
LDA
GMM
discrminivative
model
判别模型 logistic reposion
conditioned rule field(CRF) X
--------------------------------------
supervised learning
D = {(x1,y1),(x2,y2),...(xn,yn)}
x1:特征向量;
y1:label标签
线性回归 linear regression
逻辑回归 logistic regression
朴素贝叶斯 naive bayes
神经网络 neural network
svm support vector machine
随机森林 random forest
adaboost
CNN convolutional neural network
unsupervised learning
D = {x1,x2...xn}
数据分析
k-means :聚类操作
PCA principal component analysis : 降维
ICA independent component analysis :降维
MF matrix factorization : 矩阵分解,将维
LSA latent semantic analysis :文本分析
LDA latent dirichlet allocation :文本分析
generative model discriminative model
生成模型 p(x)或 p(xy) 判别模型 p(y|x)条件概率
以训练好:图片、音乐、文本 记录对象间的区别,用以判断对象
模型记住对象的特点,用以判断
-------------------------------------------
搭建模型:
数据 -》 清洗clearing -> 特征工程(时间非常高,调参xxx) -》 建模 —>预测
train and test data
------------
naive bayes:
垃圾邮件里经常出现“广告”,“购买”,“产品”这些单词,
也就是 p("广告"|垃圾) 》 p("广告"|正常),p(“购买”|垃圾)》p(“购买”|正常)。。。。
这些概率怎么计算?
正常邮件含有“购买”的概率多少 ? p("购买"|正常) = 3/240 p(“物品”|正常) =
垃圾邮件含有“购买”的概率多少? p("购买"|垃圾) = 7/120 p(“物品”|垃圾) =
概率大的分类就倾向于哪个
prior infomation (先验)
p(x|y) = p(y|x)p(x)/p(y)
p(x,y) = p(x)p(y|x)
conditional independence(条件独立)
p(x,y|z) = p(x|z).p(y|z)
预测:哪个概率大就是哪个
p(正常|内容) = p(内容|正常).p(正常)/p(内容)
p(垃圾|内容) = p(内容|垃圾).p(垃圾)/p(内容)
新邮件: p(内容|正常) = p(购买,物品,不是,广告|正常)
= p(购买|正常).p(物品|正常).p(不是|正常).p(广告|正常)
-------------------------------------------------------
---------------------------------------------------------------------------------
垃圾邮件:
点击 获得 更多 信息
购买最新 产品 获得 优惠
优惠 信息 点击 链接
正常邮件:
明天 一起 开会
开会 信息详见 邮件
最新 竞品 信息
新邮件:
最新 产品 实惠 点击 链接
1、训练模型:
p(垃圾) = 3/6
p(正常) = 3/6
v = {点击,获得,更多,信息,购买,最新,产品,优惠,链接,明天,一起,开会,详见,邮件,竞品}
p(点击|垃圾) = (2+1)/(13+15)
p(点击|正常) = (0+1)/(10+15)
p(获得|垃圾) = (2+1)/(13+15)
p(获得|正常) = (0+1)/(10+15)
p(最新|垃圾) = (1+1)/(13+15)条件概率
p(最新|正常) = (1+1)/(10+15)
p(产品|垃圾) = (1+1)/(13+15)
p(产品|正常) = (0+1)/(10+15)
p(实惠|垃圾) = (2+1)/(13+15)
p(是会|正常) = (0+1)/(10+15)
p(链接|垃圾) = (1+1)/(13+15)
p(连接|正常) = (0+1)/(10+15)
2、预测:
p(垃圾|邮件) ? p(正常|邮件)
p(邮件|垃圾)p(垃圾) ? p(邮件|正常)p(正常)
3/28 1/14 1/14 3/28 1/14 1/2 ? 1/25 2/25 1/25 1/25 1/25 1/2
---------------------------------------
lambda表达式:
def add(x,y):
return x+y
print(add(3,4))
add_lab = lambda x,y: x+y
print(add_lab(3,4))
--------------------------------------
3元运算符:
condition = True
print(1 if condition else 2)
condition = False
print(1 if condition else 2)
--------------------------------------
map函数:函数,迭代器
list1 = {1,2,3,4,5}
r=map(lambda x:x+x, list1)
m1=map(lambda x,y:x+y, [1,2,3,4,5],[1,2,3,4,5])
--------------------------------------
filter过滤器:函数,迭代器
def is_not_none(s):
return s and len(s.strip())>0
list2 = {'',' ','hello','hi',None}
result = filter(is_not_none,list2)
print(list(result))
{'hello','hi'}
----------------------------------------
reduce函数:
from functools import reduce
f=lambda x,y:x+y
r=reduce(f,[1,2,3,4,5])
print(r)
15
r=reduce(f,[1,2,3,4,5],10) // 10是初始化值
----------------------------------------
列表推导式:
list1=【1,2,3,4,5】
f=map(lambda x:x+x, list1)
pirnt(list(f))
[2,4,6,8,10]
list2=【i+i for i in list1】
print(list2)
[2,4,6,8,10]
list3=[i**3 for i in list1]
print(list3)
[1,8,27,64,125]
list4=[i*i for i in list1 if i>3]
pirnt(list4)
[16,25]
-------------------------------
集合推导式:
list1={1,2,3,4,5}
list2={i+i for i in list1}
print(list2)
{2,4,6,8,10}
list3={i**3 for i in list1}
print(list3)
{1,8,27,64,125}
list4={i*i for i in list1 if i>3}
pirnt(list4)
{16,25}
-----------------------------------
字典推导式:
s={
'zhang3':10,
'li4':20
}
s_key = [key for key,value in s.items()]
pirnt(s_key)
['zhang3','li4']
s1={value:key for key,value in s.items()}
print(s1)
{10:'zhang3',20:'li4'}
s2={key:value for key,value in s.items() if key='li4'}
print(s2)
{'li4':20}
---------------------------------------------------
闭包:返回值是函数的函数
import time
def runtime():
def now_time():
print(time.time())
return now_time
f=runtime()
f()
-----------------------
cat data.csv
def make_filter(keep):
def the_filter(file_name):
file=open(file_name)
lines=file.readlines()
file.close
filter_doc=[i for i in lines if keep in i]
return filter_doc
return the_filter
filter1=make_filter('8')
filter_result=filter1('data.csv')
print(filter_result)
----------------------------
装饰器,语法糖,注解
import time
def runtime(func):
def get_time():
print(time.time())
func()
return get_time
@runtime
def student_run():
print("student run")
student_run()
1551451828.123479
student run
有参数的装饰器
def runtime(func):
def get_time(*args,**kwargs):
print(time.time())
func(*args,**kwargs)
return get_time
@runtime
def student_run(*args): 不定参数
print("student run")
@runtime
def student_run1(**kwargs): 字典参数
print('s1 run')
@runtime
def student_run2():
print('s2 run')
@runtime
def student_run3(*args,**kwargs):
print('s3 run')
student_run(1,2)
student_run1(i=1,j=2)
student_run2()
--------------------------------------
numpy:多维数组对象
numpy < pandas (series , dataframe)
numpy < series
import numpy as np
data=[1,2,3,4,5]
n=np.array(data*10)
print(data)
pinrt(n)
[1,2,3,4,5]
[1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 ]
每一个np数组都有一个shape 和 dtype的属性
n.shape 数组维度
(50,)
n.dtype
dtype('int64')
------------------
嵌套序列
arr = [[1,2,3,4],[1,2,3,4]]
arr2 = np.array(arr)
print(arr2)
print(arr2.ndim) 外层维度
print(arr2.shape) 整个维度
[[1 2 3 4]
[1 2 3 4]]
2
(2,4)
arr=[['1','2',3,4],[5,6,7,8]]
arr2=np.array(arr)
print(arr2) 转为字符
print(arr2.dtype) unicode
[['1','2','3','4']
['5','6','7','8']]
arr=[[1,2,3,4],[5,6,7,8]]
arr2=np.array(arr)
print(arr2)
print(arr2.dtype)
[[1 2 3 4]
[5 6 7 8]]
int64
arr=[[1.1,2,3,4],[5,6,7,8]]
arr2=np.array(arr)
print(arr2)
print(arr2.dtype)
[[1.1 2. 3. 4.]
[5. 6. 7. 8.]]
float64
-----------------------
np.zeros(10) array([0.,0.,0.,0.,0.,0.,0.,0.,0.,0.])
np.ones((2,3)) array([[1.,1.,1.],
[1.,1.,1.]])
np.empty((2,3,4)) array([[[0,0,0,0],
[0,0,0,0],
[0,0,0,0]],
[[0,0,0,0],
[0,0,0,0],
[0,0,0,0]]])
np.arange(10) array([0,1,2,3,4,5,6,7,8,9]) range函数对应
arr = np.array([1.2,1.6,1.8,-2.3,-5.8])
pirnt(arr)
print(arr.dtype)
print(arr.astype(np.int32))
[1.2 1.6 1.8 -2.3 -5.8]
float
[1 1 1 -2 -5]
int 类型: 8 16 32 64
float : 16 32 64 128
---------------------------
矢量化运算
arr1=np.array([1,2,3,4])
arr2=np.array([5,6,7,8])
arr2+arr1
array([6,8,10,12])
arr1=np.array([1,2,3,4],[1,2,3,4])
arr2=np.array([5,6,7,8],[9,6,7,8])
arr2/arr1
array([[5.,3.,2.333333, 2. ],
[9.,3.,2.333333,2.]])
arr1=np.array([[1,2,3,4],[10,2,3,4]])
5*arr1
array([[5,10,15,20],[50,10,15,20]])
----------------------
索引,切片
arr=np.arange(10)
print(arr) [0 1 2 3 4 5 6 7 8 9 ]
print(arr[1]) 1
print(arr[4:]) [4 5 6 7 8 9]
arr[0:4]=11 [11 11 11 11 4 5 6 7 8 9]
print(arr)
arrcopy=arr.copy()
print(arrcopy) [11 11 11 11 4 5 6 7 8 9]
arr1=np.array([[1,2,3],[4,5,6]])
print(arr1[0][1]) 2
print(arr1[0,1]) 2
----------------元素比较
names=np.array(['tony','jack','robin'])
print(names=='tony')
True False False
------------------花式索引
arr=np.empty((8,4))
print(arr)
for i in range(8):
arr[i] = i
print(arr[[4,3,0,6]])
[[4. 4. 4. 4.]
[3. 3. 3. 3.]
[0.0.0.0.]
[6. 6. 6. 6.]]
arr=np.arrange(32).reshape((8,4))
print(arr)
[[0 1 2 3]
[4 5 6 7]
[8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
print(arr[[1,5,7,2]])
[[4 5 6 7]
[20 21 22 23]
[28 29 30 31]
[8 9 10 11]]
print(arr[[1,5,7,2],[0,3,1,2]])
[[4 5 6 7]
[20 21 22 23]
[28 29 30 31]
[8 9 10 11]]
[4 23 29 10]
print(arr[[1,5,7,2]][:,[0,3,1,2]])
[[4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[8 11 9 10]]
print(arr[np.ix_([1,5,7,2],[0,3,1,2])]) 同上
--------------------------------------------------------------------------------
数组转置,轴兑换
arr=np.arange(15).reshape((3,5))
print(arr)
pirnt(arr.transpose())
[[0 1 2 3 4]
[5 6 7 8 9]
10 11 12 13 14]]
[[0 5 10]
[1 6 11]
[2 7 12]
[3 8 13]
[4 9 14]]
-----------------------------
arr=np.arrage(24).reshape((2,3,4))
pirnt(arr)
print(arr.transpose((1,2,0)))
[[[0 1 2 3 ]
[4 5 6 7]
[8 9 10 11 12]]
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]]
-------------------------------
xarr=np.array([1.1,1.2,1.3])
yarr=np.array([2.1,2.2,2.3])
condition=np.array([True,False,True])
res=[(x if c else y) for x,y,c in zip(xarr,yarr,condition)]
print(res)
r=np.where(condition,xarr,yarr)
print(r)
[1.1,2.2,1.3]
[1.1 2.2 1.3]
-------------------------------
arr=np.random.randn(2,2)
print(arr)
arr2=np.where(arr>0, 2, -2)
pirnt(arr2)
[[-1.12 0.123] [3.120 -1.210]]
[[-2 2] [2 -2]]
-----------------------------
数学运算
arr=np.random.rand(4,4) 一个或一组服从“0~1”均匀分布的随机样本值,取值范围是[0,1),不包括1
arr=np.random.randn(4,4) 回一个或一组服从标准正态分布的随机样本值。
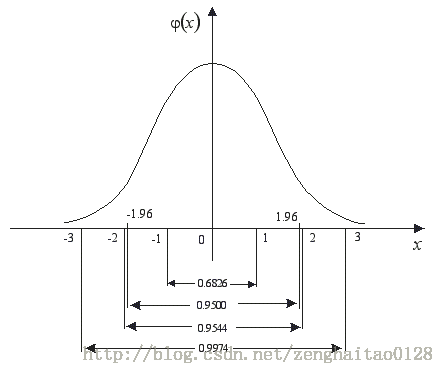
np.random.randint 随机整型数,其范围为[low, high)。如果没有写参数high的值,则返回[0,low)的值

print(arr)
print(arr.mean()) 平均值
print(np.mean(arr)) 平均值
print(arr.sum()) 求和
print(arr.std()) 标准差
print(arr.mean(axis=1)) 轴1平均值
print(arr.sum(0)) 轴0的和
argmin argmax cumsum
arr.sort() 从小到大排序
arr.sort(1) 按轴排序
---------------------------
文件操作:文本,二进制数据
未压缩的原始二进制格式保存在.npy文件中
np.save
np.load
arr=np.array(10)
np.save('any_array',arr)
np.load('any_array.npy')
np.savez('any_array_1',a=arr) 压缩格式
np.load('any_array_1.npz')['a']
np.savetxt('any.txt',arr,delimiter=',')
np.loadtxt('any.txt',delimiter=',')
----------------------------
dot 矩阵乘法运算
x=np.array([1,2,3],[4,5,6])
y=np.array([[1,2],[4,5],[7,8]])
pirnt(x.dot(y))
[[30 36]
[66 81]]
随机漫步
position=0
walk=[position]
steps=1000
for i in range(steps):
step = 1 if np.random.randint(0,2) else -1 随机数0,1
posion+=step
walk.append(position)
plt.plot(walk)
print((np.abs(walk)>10).argmax()) 最大值索引
------------------------------------------------------------------
pos tagging
S = w1 w2 w3 w4 w5
Z = argmax

------------------------
tag2id, id2tag = {}, {}
word2id, id2word = {}, {}
for line in open('train.txt'):
items = line.split('/')
word, tag = items[0], items[1].rstrip()
if word not in wor2id:
word2id[word] = len(word2id)
id2word[leln(id2word)] = word
if tag not in tag2id:
tag2id[tag] = len(tag2id)
id2tag[len(id2tag)] = tag
M = len(word2id)
N = len(tag2id)
import numpy as np
pi = np.zeros(N)
A = np.zeros(N,M))
B = np.zeros(N,N))
prev_tag=''
for line in open('train.txt'):
items = line.split('/')
wordid,tagid = word2id[items[0]],tag2id[[items[1].rstrip]]
if prev_tag == '':
pi[tagid] +=1
A[tagid][wordid] +=1
else:
A[tagid][wordid] +=1
B[tag2id[prev_tag]][tagid] +=1
if items[0] == '.':
prev_tag = ''
else:
prev_tag = items[1].rstrip()
pi = pi/sum(pi)
for i in range(N):
A[i] /= sum(A[i])
B[i] /= sum(B[i])

-----------------------------------
vertily
给定w1w2w3...wt,求出z1z2z3...zt
def viterbi(x,pi,A,B):
x = [word2id[word] for word in x.split(' ')]
T = len(x)
dp = np.zeros((T,N))
ptr = np.array([[0 for x in range(N)] for y in range(T)])
for j in range(N)
dp[0][j] = log(pi[j]) + log(A[j][x[0]])
for i in range(1,T):
for j in range(N):
dp[i][j] = -9999
for k in range(N):
score = dp[i-1][k] + log(B[k][j]) + log(A[j][x[i]])
if score>dp[i][j]:
dp[i][j] = score
ptr[i][j] = k
best_seq = [0]*T
best_seq[T-1] = NP.ARGMAX(dp[T-1])
for i in range(T-2,-1,-1):
best_seq[i] = prt[i+1][best_seq[i+1]]
for i in range(len(best_seq)):
print(id2tag[[best_seq[i]]])
---
------------------------------------------------
pandas:基于numpy构建,数据分析更快、更简单
series:类似于一维数组,由一组数组以及与之相关的标签
import pandas as pd
from pandas import Series,DataFrame
obj=Series([1,2,3,4,5])
print(obj)
0 1
1 2
2 3
3 4
4 5
dtype : int64
print(obj.values)
[1 2 3 4 5]
print(obj.index)
rangeindex(start=0,stop=5,step=1)
obj=Series(['a','b','c','d','e'], index=[1,2,3,4,5])
print(obj)
1 a
2 b
3 c
4 d
5 e
dtype:object
obj[2]
'b'
data={'a':100,'b':200,'c':300}
obj=Series(data)
print(data)
a 100
b 200
c 300
dtype:int64
keys=['a','c']
obj1=Series(data,index=keys)
a 100
c 300
dtype:int64
data={'a':None,'b':200,'c':300}
obj=Series(data)
print(obj)
a NaN
b 200
c 300
dtype:float64
pd.isnull(obj)
a True
b False
c False
dtype:bool
data={'lilei':None,'hanmei':25,'tony':None,'jack':50}
obj=Series(data)
obj.name='NameAge'
obj.index.name='xingming'
print(obj)
xingming
lilei NaN
hanmei 25.0
tony NaN
jack 50.0
Name:NameAge,dtype:float64
-----------------------------------
DataFram:表格型数据结构,含有一组有序的列;本身有行索引,也有类索引;由series组成的字典
data={
'30年代':{‘钩子’‘嘎子’},
'70年代':{‘卫国’,‘建国’},
}
framdata=DataFrame(data)
print(framedata)
print(framdata['70年代'])
30年代 70年代
0 钩子 卫国
1 嘎子 建国
0 卫国
1 建国
name:70年底,dtype:object
dates=pd.date_range('20190301',periods=6)
print(dates)
datetimeindex(['2019-03-01','2019-03-02',.......'2019-03-06'],
dtype='datetime64[ns]',freq='D')
df=pd.DataFrame(np.random.rand(6,4),index=dates,columns=list('ABCD'))
print(df)
A B C D
2019-03-01 0.01 0.125 0.562 0.235
2019-03-02 0.598 0.125 0.5621 0.1245
.
.
.
2019-03-06 0.456 0.124 0.124 0.012
df.T // 转置
df['20190301':'20190303']
a b c d
2019-03-01
2019-03-02 xxx xxx
2019-03-03 xxx xxx
df['20190301':'20190303',['a','b']]
a b
2019-03-01
2019-03-02 xxx xxx
2019-03-03 xxx xxx
df.at[dates[0],'a']
0.12346
df.head(2) 前2行
df.tail(3) 后3行
接受数据类型:
二维numpy array
数组、列表或元祖组成的字典
由Series组成的字典
有字典组成的字典
字典或series的列表
有列表或元祖组成的列表
另一个datafram
-----------------------------------------------------------------------------
obj=Series([4.5,9.8,-1.2],index={'a','b','c'})
print(obj)
obj1=obj.reindex(['a','b','c','e','f'])
print(obj1)
a 4.5
b 9.9
c -1.2
dtype: float64
a 4.5
b 9.8
c -1.2
e Nan
f NaN
dtype: float64
obj=Series([4.5,9.8,-1.2],index={'a','b','c'})
#print(obj)
obj1=obj.reindex(['a','b','c','e','f'],fill_value=1)
a 4.5
b 9.8
c -1.2
e 1.0
f 1.0
dtype: float64
obj=Series([4.5,9.8,-1.2],index={0,2,4}) 数据对其
#print(obj)
obj1=obj.reindex(range(6),method='ffill') // bfile
0 4.5
1 4.5
2 9.8
3 9.8
4 -1.2
5 -1.2
dtype: float64
d1=Series([1.3,1.5,2.6,-3.5],index=['a','b','c','d'])
d2=Series([-1.3,-1.5,-2.6,3.9,9.8],index=['a','b','c','d','e'])
d1+d2
a 0
b 0
c 0
d 0.4
e NaN
dtype: float64
df1=DataFrame(np.arange(9).reshape(3,3), columns=list('abc'), index=[1,2,3])
df2=DataFrame(np.arange(12).reshape(4,3), columns=list('cde'), index=[1,2,3,4])
df1+df2
a b c d e
1 NaN NaN 2. 0 NaN NaN
2 NaN NaN 8. 0 NaN NaN
3 NaN NaN 14. 0 NaN NaN
4 NaN NaN NaN NaN NaN
df1.add(df2,fill_value=0) 不存在的值0
a b c d e
1 0 1 2. 0 1 2
2 3 4 8. 0 4 5
3 6 7 14. 0 7 8
4 NaN NaN 9 10 11
---------------------------------
Datafram 与SERIES的运算
frame=DataFrame(np.arange(12).reshape(4,3),columns=list('bde'),index=[1,2,3,4])
series=frame.loc(1) 索引为1的一行数据
print(frame)
print(series)
b d e
1 0 1 2
2 3 4 5
3 6 7 8
4 9 10 11
b 0
d 1
e 2
Name: 1, dtype:int64
frame-series 向下广播减
b d e
1 0 0 0
2 3 3 3
3 6 6 6
4 9 9 9
series=Series(range(3),index=list('bef'))
farme+seires 没有就合并
b d e f
1 0.0 NaN 3.0 NaN
2 3.0 NaN 6.0 NaN
3 6.0 NaN 9.0 NaN
4 9.0 NaN 12.0 NaN
---------
obj=Series(range(4),index=['d','e','a','b'])
obj.sort_index()
a 2
b 3
d 0
e 1
dtype: int64
obj.sort_values()
d 0
e 1
a 2
b 3
dtype:int64
frame=DateFrame(np.arange(8).reshape(2,4),index=['two','one'],columns=['c','d','a','b'])
frame.sourt_index()
c d a b
one 4 5 6 7
two 0 1 2 3
frame.sort_index(axis=1)
a b c d
two 2 3 0 1
one 6 7 4 5
frame=DataFrame({'b':[4,7,2,-1],'a':[0,4,2,0]})
frame.sourt_values(by='b')
b a
3 -1 0
2 2 2
0 4 0
1 7 4
----------------------------------
层次化索引:一个轴上有多个索引级别
date=Series(np.random.randn(10),index=[['a','a','a','b','b','b'.'c','c','d','d'],[1,2,3,4,5,6,7,8,1,2]])
a 1 0.1
2 0.2
3 0.1
b 4 0.1
5 0.2
6 0.1
c 7 0.2
8 0.1
d 1 0.2
2 0.1
dtype: float64
data.index
multiindex(levels=[['a','b','d','d'],[1,2,3,4,5,6,7,8]],
labels=[[0,0,0,1,1,1,2,2,3,3],[0,1,2,3,4,5,6,7,0,1]])
date['b']
4 0.1
5 0.2
6 0.1
dtype:float64
date['b':'d']
b 4 0.1
5 0.2
6 0.1
c 7 0.2
8 0.1
d 1 0.2
2 0.1
dtype: float64
date[:,2]
a 0.2
d 0.1
dtype:float64
date.unstack() 生成一个新的dataframe
1 2 3 4 5 6 7 8
a 0.1 0.2 0.1 NaN NaN NaN NaN NaN
b NaN NaN NaN 0.1 0.2 0.1 NaN NaN
c NaN NaN NaN NaN NaN NaN 0.2 0.1
d 0.2 0.1 NaN NaN NaN NaN NaN NaN
date.unstack().stack()
a 1 0.1
2 0.2
3 0.1
b 4 0.1
5 0.2
6 0.1
c 7 0.2
8 0.1
d 1 0.2
2 0.1
dtype: float64
frame=DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]],
columns=[['black','yellow','blue'],['green','red','green']])
black yellow blue
green red green
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
fram.index.names=['k1','k2']
black yellow blue
k1 k2 green red green
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
frame.columns.names=['c1','c2']
c1 black yellow blue
c2 green red green
k1 k2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
frame=DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]],
columns=[['black','yellow','black'],['green','red','blue']])
black yellow black
green red blue
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
frame_data['black'] 列
black black
green blue
a 1 0 2
2 3 5
b 1 6 8
2 9 11
frame.loc['a',['black']] 行 列
black
green blue
1 0 2
2 3 5
frame.sum(level='k2')
black yellow black
k2 green red blue
1 6 8 10
2 12 14 16
frame=DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]],
columns=[['black','yellow','black'],['green','red','green']])
fram.index.names=['k1','k2']
frame.columns.names=['c1','c2']
c1 black yellow blue
c2 green red green
k1 k2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
frame.sum(level='c2',axis=1)
c2 green red
k1 k2
a 1 2 1
2 8 4
b 1 14 7
2 20 10
------------------------------------------------------
pandas文本格式
--------------------
read_csv: 从文件、url,文件型对象中加载带分隔符的数据,默认逗号
cat d.csv
a,b,c,d,e
1,2,3,4,5
6,7,8,9,10
pd.read_csv('d.csv')
a b c d e
0 1 2 3 4 5
1 6 7 8 9 10
pd.read_cvs('d.csv',header=None)
0 1 2 3 4
0 a b c d e
1 1 2 3 4 5
2 6 7 8 9 10
pd.read_cvs('d.csv',index_col='c') 索引
a b d e
c
3 1 2 4 5
8 6 7 9 10
pd.read_cvs('d.csv',index_col=['c','d']) 索引
a b e
c d
3 4 1 2 5
8 9 6 7 10
cat d2.csv
a,b,c,d,msg,data
1,2,3,4,5,NA
hello,6,7,8,9,world
NA,hi,10,11,12,14
pd.read_csv('d2.csv')
a b c d msg data
0 1 2 3 4 5 NaN
1 hello 6 7 8 9 world
2 NaN hi 10 11 12 14
pd.read_csv('d2.csv',skiprows=[1]) 跳过行
a b c d msg data
0 hello 6 7 8 9 world
1 NaN hi 10 11 12 14
d=pd.read_csv('d2.csv')
pd.isnull(d)
a b c d msg data
0 False F F F F T
1 False F F F F F
2 True F F F F F
d=pd.read_csv('big.csv',nrows=5) 读取5行
d.to_csv('d2',sep='|') 写入
--------------------
read_table: 从文件、url,文件型对象中加载带分隔符的数据,默认\t
pd.read_table('d.csv',sep=',')
a b c d e
0 1 2 3 4 5
1 6 7 8 9 10
----------------------
read_fwf:读取固定宽列个事数据
read_clipboard:读取剪切板数据,可以看作是read_table的剪切板,在网页中的数据转换为表格中数据时用到
----------------------------------------------------------------
读取excel数据
id age price
1 11 12
2 12 13
3 13 12
pd.read_excel('d.xlsx') 读取默认表
pd.read_excel('d.xlsx',sheet_name='工作表2') 读取表2
excel = pd.read_excel('d.xlsx',sheet_name='工作表2')
pl=excel.plot(kind='scatter',x='age',y='price').get_figure()
pl.savefig('1.png')
d=pd.date_range('20200101',periods=6)
df=pd.DataFrame(np.random.rand(6,4),index=d,columns=list('ABCD'))
p1=df.plot(kind='scatter'x='A',y='B').get_figure()
p1.savefig('2.png')
------------------------------------------------------------------------------------------------
pip install matplot lib
import matplotlib.pyplot as plt
plt.plot(np.arrange(10))
plt.figure()
fig=plt.figure
ax1=fig.add_subplot(2,2,1)
ax2=fig.add_subplot(2,2,2)
ax3=fig.add_subplot(2,2,3)
ax4=fig.add_subplot(2,2,4)
from numpy.random import randn
plt.plot(randn(50).cumsum(),'k--') 灰色
ax1.hist(randn(100),bins=20,color='k',alpha=0.3)
ax2.scatter(np.arange(30),np.arange(30)+3*randn(30))
--------------------------
plt.plot(randn(50).cumsum(),'g--') 绿色
--------------
x=[1,2,3,4,5]
y=[1,2,3,4,5]
plt.plot(x,y,linestype='--',color='#CECECE')
-----------------
from pandas import Series,DataFrame
s=Series(randn(10),cumsum(),index=np.arange(0,100,10))
s.plot()
------------------
df=DataFrame(np.random.randn(10,4).cumsum(0),columns=['a','b','c','d'],index=np.arange(0,100,10))
df.plot()
-----------------
baidu:matplotlib 例子
-----------------------------------------------------------------------------------------------------
python 虚拟环境,环境隔离
pip install virtualenvwrapper
vim ~/.bash_profile
WORKON_HOME=xxx
VIRTUALENVWRAPPER_PYTHON=/usr/xxxxx
source /Library/xxxxxx/xx/virtualenvwrapper.sh
PATH='XXXXXXX'
export PATH
sudo find / -name virtualenvwrapper.sh
source ~/.bash_profile
workon 列出所有
mkvirtualenv spider_1 创建
workon spider_1 在环境下工作
deactive spider_a 推出环境
rmvirtualenv spider_1 删除环境
------------------------------------------------------------------
pip install mysqlclient
pip install Scrapy
cd /home/jin
scrapy startproject my_spider
cd my_spider
scrapy genspider qizha https://tieba.baidu.com/xxxx
cd my_spider
cd spiders
vim qizha.py 调整doman, url
pycharm:
from scrapy.cmdline import execute
import os
import sys
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(['scrapy','crawl','qizha'])
-----------------------------------------------
css 方式 class=xxxxx
source .bash_profile
workon spider
scrapy shell https://tieba.baidu.com/xxsfsd
response.css('.j_th_tit').extract()
response.css('.j_th_tit::attr(href)').extract()
def parse(self.response):
url_list = response.css('.j_th_tit::attr(href)').extract()
for url in url_list:
print(url)
yield scrapy.Requet(url=parse.urljoin(response.url,url),callback=self.parse_detail)
next_url = response.css('.next.pagination-item::attr(href)').extract()[0]
if unext_url:
yield scrapy.Request(url=parse.urljoin(response.url,next_url),callback=self.parse)
def parse_detail(self, response):
title = response.css('.core_title_txt.pull-left.text-overfow::text').extract()
authos= response.css('.p_author_name.j_user_card::text').extract()
contents_list = response.css('.d_post_content.j_d_post_content').extract()
content_list = get_content(contents_list)
bbs_sendtime_list,bbs_floor_list=get_send_time_and_floor(response)
if title: 放入item中
authos= response.css('.p_author_name.j_user_card::text').extract()
contents_list = response.css('.d_post_content.j_d_post_content').extract()
content_list = get_content(contents_list)
for i in range(len(authors)):
tieba_item=TiebaItem()
tieba_item['title']=tiles[0]
tieba_item['author']=authors[0]
tieba_item['content']=contens_list[0]
tieba_item['reply_tiem']=bbs_sendtime_list[0]
tieba_item['floor']=bbs_floor_list[0]
return tieba_item
def get_send_time_and_floor(self,response):
bbs_send_tiem_and_floor_list=response.css('.post-tail-wrap span[class=tail-info]::text').extract()
i = 0
bbs_sendtime_list=[]
bbs_floor_list=[]
for lz in bbs_send_time_and_floor_list:
if lz =='来自':
bbs_send_time_and_floor_list.remove(lz)
for bbs_send_time_and_floor in bbs_send_tiem_and_floor_list:
if i% 2 == 0:
bbs_floor_list.append(bbs_send_time_and_floor)
if i%2==1:
bbs_sendtime_list.append(bbs_send_time_and_floor)
i+=1
return bbs_sendtime_list,bbs_floor_list
def get_content(self,contents):
contetns_list=[]
for content in contents:
reg = ";\">(.*)
result = re.findall(reg,content)[0]
contetns_list.append(result)
return contenst_list
scrapy shell https://tieba.xsofjsof
response.css('.core_title_txt.pull-left.text-overfow').extract()
response.css('.core_title_txt.pull-left.text-overfow::text').extract()
response.css('.p_author_name.j_user_card').extract()
response.css('.p_author_name.j_user_card::text').extract()
response.css('.d_post_content.j_d_post_content').extract()
response.css('.post-tail-wrap').extract()
response.css('.post-tail-wrap span[class=tail-info]::text').extract()
settings.py:
ITEM_PIPELINES={ 'my_spider.pipelines.MysqlTwistedPipline':1,}
MYSQL_HOST='192.168.1.23'
MYSQL_DBNAME='spider'
MYSQL_USER='admin'
MYSQL_PASSWROD='123465'
pipelines.py:
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class MySpiderPipeline(object):
def process_item(self,item,spider):
return item
class MysqlTwistedPipline(object):
def __init__(self,dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls,settings):
dbparms = dict({host=settings['MYSQL_HOST'], db = settings['MYSQL_DBNAME'], user = settings['MYSQL_USER'], passwrd=settings['MYSQL_PASSWORD'],charset='utf8',cursorclass=MySQLdb.cursors.DictCursor, use_unicode=True})
dbpool = adbapi.ConnecttionPool('MySQLdb',**dbparms)
return cls(dbpool)
def process_item(self,item,spider):
query=self.dbpool.runInteraction(self.do_insert,item)
def do_insert(self,cursor,item):
insert_sql,params = itme.get_insert_sql()
cursor.execute(insert_sql,params)
Items.py:
import scrapy
class MySpiderItem(scrapy.Item):
pass
class TiebaItem(scrapy.Item):
tile=scrapy.Field()
author = scrapy.Field()
content=scrapy.Field()
reply_time=scrapy.Field()
floor=scrapy.Field()
def get_insert_sql(self):
insert_sql = 'insert into baidu_tieba(title,author,content,reply_time,floor) values(%s,%s,%s,%s,%s)'
param=(self['title'],self['author'],self['content'],self['reply_time'],self['floor'])
return inset_sql,params
--------------------------------------------------------------------------------------
sampling methods,采样方法
why need:
近似,统计
抽样推断
期望:
p(x)
门特卡罗算法
fair
bias
负采样 negative sampling
NCE noise contrastive estimation: -> 二酚类问题
--------------------------------------------------------------------------------
valuation of classifier
correct not correct
selected 10 tp 8 fp 2
not selected fn tn
1、准确率 correct:
acc= 正确数量/总数量 = tp/(tp+fp)
2、精确率 precision 80%
correct not correct
selected 10 tp 8 fp 2
not selected 990 fn 2 tn 988
3、召回率 80% = tp/(tp+fn)
groud true: N N N T T N N N N T
分类: n n t t n n n n n t
正样本:p=2/3
r= 2/3
groud true: n n n t t n n n n t
n t t t t n n t n t
p=3/6
r=3/3
f1 score:
f1-measure = 2*precision*recall/(precision+recall)
正常邮件: p= 16/18
r = 16/20
f1= 2*8/9*0.8/(p+r) = a
垃圾: p=3/7
r= 3/5
f1=2*p*r/(r+p) = b
整体: p = (8/9+3/7)/2
r = (0.8+0.6)/2
f1= (a+b)/2
-----------------------------------
logistic regression逻辑回归:
二分类问题
f:x->y
-> p(y|x) 条件概率
p(y=1|(20,4000,本科)) ? p(y=0|(20,4000,本科))
p(y|x) = wtx+b ? no
0<=p(y|x)<=1
总和 = 1
y=1/(1+e(-x))
p(y|x)=1/(1+e(-(wtx+b)))
p(y=1|(20,4000,本科)) ? p(y=0|(20,4000,本科))
逻辑回归:线性分类器(决策边界 直线 曲线)
p(y=1|x,w) = p(y=0|x,w)
->wtx+b=0 ->线性边界
--------------------------------------------------------------------------------------------------------------------------------------
目标函数:
w,b = argmax连乘 p(y|x,w,b)
-> argmin- 连和logp(y|x,w,b)
=argmin - 连和logp(y=1|x,w,b)^y log[1.p(y=1|w,w,b)]^(1-y)
=argmin -连和ylogp(y|x,w,b)+(1-y)log[1-p(y=1|x,w,b)]
--------------------------------
最优解:
求f(w)最小的参数w
是否凸函数: global optional vs local optional
最优化算法:
------------------
GD(gradient descent)
初始化w1
for t = 1,2....:
Wt+1 = Wt -hf(Wt) h->learning rate f(wt) -》梯度函数
求解f(w)=4w^2+5w+1
w1=0,梯度=8w+5
w2=w1- 0.1(8*0+5) = -0.5
w3=w2- 0.1(8*(-0.5)+5) = -0.6
w4=w3- 0.1(8*(-0.6)+5)= -0.62
w5=w4-0.1(8*(-0.62)+5) = -0.66
....
=argmin -连和ylogp(y|x,w,b)+(1-y)log[1-p(y=1|x,w,b)]
w求导
=连和(f(x)-y)x
b求导
=连和(f(x)-y)
初始化w1,b1
for t=1,2,3...
Wt+1 = Wt -h连和(f(x)-y)x 更新时每次所有数据
Bt+1 = Bt -h连和(f(x)-y)
停止条件:
f(Xt)-f(Xt-1) < s
|Wt-Wt-1|
validata
fixed iteration
-----------------------
SGD 随机梯度 stochastic gradient desent
fro itr = 1.....T:
shuffle()
for i =1...n
Wnew = Wold - h(f(x)-Y)x 更新时每次一个数据
Bnew = Bold - h(f(x)-y)
Minibatch GD
for t=1,2....
batch =sample()
Wt+1 = Wt-h小连和(f(x)-y)x 更新时每次一个子集
Bt+1 = Bt -h小连和(f(x)-y)
Adamgrad,adam
-----------------------------
现行可分的时候参数会变成无穷大
-------------------------------------------
面试:
自我介绍:特点,记住
发展史:
难点:词义消岐,指代消解,上下文理解,语义语用不对等
应用:医疗,教育,媒体,金融,法律
常见工具:基本工具包,分词器,机器学习,深度学习
自然语言处理与机器学习的关系:逻辑回归,朴素贝叶斯,k,svm(最大间隔,kkt,核),决策树
集成方法
自然语言处理与深度学习:cnn,rnn,attention,self-attenttion,transformer,bert
基本任务:文本预处理
文本获取
流程
数据不平衡,冲采样,上采样,下采样
文本表示
tf-idf,word2vec cbow skip-gram,fasttext,glove,elmo
句子方面向量:
sif,
序列标注:
基于概率模型的方法:hmm,memm,crf
基于深度学习:bi-lstm+crf
关系抽取:
bootstrap,深度学习方法
文本聚类:
方法:划分法,层次发,基于密度,基于网络
应用:数据整理,用户画像,数据可视化
文本分类:
机器学习,模型融合,深度学习
二分类,多酚类,多标签多分类
文本摘要:
抽取式,压缩式,重组发
语言生成:
语言模型,深度学习
写诗机器人,聊天任务
机器翻译:
发展史
技术:编码器,解码器,attention,self-attention,bert
聊天系统:
类型:闲聊,知识问答,任务型(多伦对话:意图识别,词槽,对话管理,数据库,对话生成,强化学习)
问题种类:
常规问题
项目问题:懂写
应用场景:实际业务
私人信息:
如何选择:
人员:领导,技术储备
项目:专业公司,业余公司,资金投入
工作强度:研究,重复
-----------------------------------
Native bayes
求最优解(closed-form)
1、求极值,一介倒数=0
2、GD算法
t = 0时 x0
t=1,2,3...
Xt=Xt-1 -hf`(x)
3、newon method
MLE
lagragion 拉格朗日
f(x,y) = x+y
s.t. x^2+y^2=1
-----------------------------------------------------------------------------
凸优化
拉格朗日惩罚项
max l = x+y +r(x^2+y^2-1)
对 x,y,r求导=0
-》x=-1/(2r) y = -1/(2r) r1=1.414/2 r2=-1.414/2
minimise f(x)
st. g(x)=0 i=1,2,3...
h(x)<=0 j=1,2,3...
------------------------------
构建目标函数
MLE maxinum likelihood estimate最大似然估计:根据样本数计算
coin: 正面 4/6 H正面 T反面
反面
D={H,T,T,H,H,H}
max p(D) = p(htthhh)
= x.(1-x)(1-x)xxx
=x^4(1-x)^2
对x求导 = 0, -》 x=2/3
-----------------------------------
MAP:带有先验概率
Bayse
----------------------------------------------------
模型 -》 模型实例化 ->模型的实例 -》明确的目标函数f(x) -> 优化
ann
svm
深度学习 -》 layers
第一层 100 cents
... 第二次 50
抽象层 ...
最后一层 softmax
loss: cross-engory
----------------------------------
模型 vs 目标函数 vs 优化
抽象 实例 求解
-----------------------------------------------
native bayes
MLE -> 目标 -> 优化
D={(x1,y1),...(xn,yn)}