[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation
基于上下文的语义分割串联网络
论文地址
摘要
上下文信息已经被证明是语义分割中的强大线索。本工作提出了一种新型的基于上下文的串联网络(CTNet),通过交互挖掘空间上下文信息和通道上下文信息,来发现用于语义分割的上下文语义。具体来说,空间上下文模块(SCM)过探索像素和类别之间的相关性来揭示像素之间的空间上下文相关性。同时引入通道上下文模块(CCM),通过建模通道之间的长距离语义依赖关系来学习语义特征,包括语义特征映射和类特定特征。利用学习到的语义特征作为先验知识指导供应SCM的学习,使供SCM获得更准确的长距离空间依赖关系。最后,为了进一步提高学习到的语义分割表示的性能,对两个上下文模块的结果进行自适应集成,以获得更好的语义分割结果。
存在的问题及解决方案
语义分割的目标是预测图像中每个像素的语义标签。主要的挑战来自于难以准确区分一些外观相似的令人困惑的类别。例如,如图1所示,“椅子”的物体与“沙发”的物体颜色相同,“水”和“地面”的区域在视觉上颜色和形状相似。仅从外观上很难区分这些区域。因此,为了提高分割性能,上下文信息被广泛用于语义切分。
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第1张图片](http://img.e-com-net.com/image/info8/359475a8cb4f462cb5458d455060a6ac.jpg)
基于全卷积网络(FCN)框架的空间上下文信息挖掘方法已经被提出。空间上下文描述像素之间的关系,因为一个图像中的每个对象是由多个像素描述的。为了探索空间依赖性,人们对拓展网络感知域进行了研究。Deeplabv3和PSPNet都使用多尺度特征提取方案来扩展空间感知域。然而,这些方案只关注局部特征关系,产生的上下文信息是有限的。最近,自注意力方案带来了新的想法来捕捉长距离依赖。但计算量和存储空间的消耗较大,不适合进行语义分割。因此,一些工作旨在提高自注意力语义分割,例如CCNet和EMANet采用稀疏注意机制,在不降低网络性能的前提下降低了模型的计算复杂度。这些方法证明了同类别像素对空间上下文的贡献最大。但是,它们并没有考虑像素与类别之间的关系来直接构建空间上下文信息。这些关系不仅有助于减少语境中的噪声信息,而且有助于提高空间语境的可解释性。 同时,这些基于空间上下文的方法容易在分割过程中引入不存在于图像中的类别信息,如图1中第三幅图像所示,图像中没有属于‘sky’的区域,但是在分割过程中属于‘ground’的像素被识别为‘sky’。这种现象的出现说明空间语境中不包含图像的类别信息。因此,基于空间上下文的方法容易在图像的类别维度上失去域,这一问题可以称为类别域缺失。
实际上,每个通道的特征图对应于特定的语义响应。不同的语义响应相互关联。因此,应该探索通道上下文以增强有用的特征,并抑制对当前任务不太有用的特征。SENet采用挤压激励操作获取通道上下文信息。SKNet利用注意机制获得了更丰富的通道上下文。EncNet通过编码器层获得全局特性,通过完全连接层获得通道上下文。这些方法平等地对待每个通道,只考虑所有通道之间的交互信息。仅基于通道上下文的图像分割容易混淆这些类别。如图1的第三张图片所示,‘ground’和‘water’属于图像的范畴,但是属于‘ground’的区域被错误地划分为‘water’。因此,基于通道上下文的方法容易在图像的像素维度上失去场,这个问题可以称为像素域缺失。
目前的工作表明,通道语境和空间语境对于分割是非常重要的,因此如何合理地利用它们是一个迫切需要解决的问题。过往的工作认为通道上下文与空间上下文是相互独立的,并不探究它们之间的互补性。为此,本工作提出了一种新的基于上下文的串联网络(CTNet),利用通道上下文模块(CCM)和空间上下文模块(SCM),如图2所示,以交互地探索通道和空间上下文信息。提出的CTNet利用通道高级特征图中编码的丰富语义信息来指导空间依赖性的学习。该方法可以保证CTNet同时捕获像素间的空间上下文相关性和通道间的语义相关性。
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第2张图片](http://img.e-com-net.com/image/info8/4b11659d58964b1082bd2196d72dd3e3.jpg)
CCM设计了多局部通道激励(Multi-local Channel Excitation–MCE)块,通过学习多局部通道特征映射之间的语义依赖性来探索通道上下文,因为不同尺度的局部通道上下文信息是互补的。此外,我们还提出了一种新的类概率损失来规范训练,使网络能够更好地捕捉信道上下文信息,准确地预测图像中类的概率。CCM通过预测每个类别在图像中出现的概率为每个类别生成一个语义表示向量(称为类特征),并通过更新每个通道特征图生成一个新的特征图(称为中间特征)。对于SCM,提出了一种新的自注意机制来捕获空间上下文。基于中间特征和类特征学习所有像素之间的全局依赖关系,基于像素和类别之间的相关性聚合类别特征来更新特征。实际上,CCM学习到的特征可以作为先验知识来指导SCM学习,这可以改进SCM学习到的特征。因此,CCM和SCM是交互训练而不是独立训练的。最后,将CCM和SCM学习到的特征映射自适应融合,进行语义分割。所提出的CTNet可以通过交互考虑空间和通道关系来发现完整的长距离依赖关系。
方法
CCM Module
每个通道特征映射对应于高级特征中的一个特定语义响应,不同的语义响应相互关联。使用通道上下文,即通道之间的依赖关系,可以改进特定语义的特征表示,并重新校准特征映射。
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第3张图片](http://img.e-com-net.com/image/info8/541739ebc0e6491c800892eac1cb6ade.jpg)
现有方法通过设计不同的块来提取通道上下文,如图3所示。SE块、GC块和Encoding块通过捕获全局通道交互信息,提高了模型的表示能力。但是,由于每个通道只与相邻的通道紧密相关,这些交互信息是冗余的。
为此,通过融合多尺度局部通道上下文,提出了多局部通道激励(MCE)块,其中不同的尺度表示与当前通道相关联的不同数量的邻居通道。MCE块的结构如图3(d)所示。给定一个特征映射 X ∈ R C × H × W X \in R^{C \times H \times W} X∈RC×H×W作为输入,采用全局池化操作将每个二维特征通道转化为实数,在某种程度上这表示一个全局性的感知域。即得到一个粗糙的全局信息 P x ∈ R C × 1 × 1 P_{x} \in R^{C \times 1 \times 1} Px∈RC×1×1表示特征通道上响应的全局分布,然后MCE块引入一维卷积从粗糙的全局信息中捕获局部信道上下文。
为了获取更全面的信道上下文信息,MCE块首先通过采用不同卷积核的多个一维卷积来探索不同尺度的局部信道上下文,然后聚合得到多尺度局部通道上下文映射 C c ∈ R C × s × 1 C_{c} \in R^{C \times s \times 1} Cc∈RC×s×1:
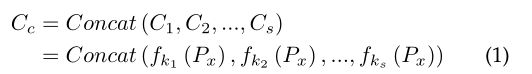
其中 s s s是一维卷积的个数,Concat表示特征连接操作, f k i f_{k_i} fki表示带有卷积核 k i ( i = 1 , . . . , s ) k_i(i=1,...,s) ki(i=1,...,s)的不同一维卷积,然后,MEC块采用全连接层从聚合的通道映射 C c C_c Cc提取最终的通道上下文 C m ∈ R C × 1 × 1 C_{m} \in R^{C \times 1 \times 1} Cm∈RC×1×1:
![]()
其中σ是sigmoid激活函数。
CCM是基于MCE块开发的,通过通道上下文更新特征图的表示,得到图像的类特征,如图4所示。
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第4张图片](http://img.e-com-net.com/image/info8/c57c68f1c38b47f3b376fe21e1f788c9.jpg)
即,通过命令 C m C_m Cm与原始特征映射 X X X之间的通道级乘法生成一个新的特征映射,称为中间特征 X c ∈ R C × H × W X_{c} \in R^{C \times H \times W} Xc∈RC×H×W:
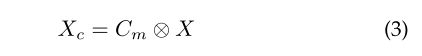
高阶特征往往会丢失图像中小目标的信息,使得语义分割任务难以识别小目标。同时,CCM需要学习每幅图像中类别之间的差异,从而得到类特征图。为此,本文提出了一种新的损失函数(Class Probability loss, CP-Loss),通过CCM预测图像中目标类别的出现概率来实现训练的正则化。CP-Loss的定义如下:
![]()
其中 P p P_p Pp表示图像类别的预测概率, P g t P_{gt} Pgt表示目标概率, w n w_n wn表示当前batch的权重, C m C_m Cm通过一个参数为 C × N C × N C×N的全连接层学习 P p P_p Pp,其中 N N N为数据集中所有类别的数量。实际上,并没有关于物体类别出现在图像中的目标概率的信息。因此, P g t P_{gt} Pgt计算基于ground-truth标签。通过 P g t i = P i ∑ i = 1 N P i P_{g t}^{i}=\frac{P^{i}}{\sum_{i=1}^{N} P^{i}} Pgti=∑i=1NPiPi得到图像中第 i i i类目标概率。其中 P i P^i Pi为第 i i i类像素在当前图像中出现的概率。CP-Loss保证了通道上下文不仅可以包含图像中的所有类别,还可以包含图像中所有类别的出现概率。
根据通道上下文 C m C_m Cm和每个类别的概率 P p P_p Pp,可以得到由图像中所有目标特征向量组成的类别特征矩阵:
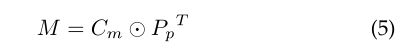
将中间特征映射 X c X_c Xc和类特征映射 M M M输入到SCM模块中。CCM提供的特征映射可以作为先验知识指导SCM学习,可以提高SCM学习的特征。同时,类特征矩阵为图像中的每个类别提供了独立的特征表示,可以帮助SCM更准确地捕获空间上下文信息。
SCM Moudle
为了提高分割性能,需要在空间维度上捕获长距离依赖的上下文信息。基于自注意的方法通过扩大模型的感知域来捕获全局空间上下文信息。如图5 (a)所示,非局部块直接计算像素之间的相关性来捕获空间上下文,计算复杂度高,占用内存大。cross - attention block,如图5 (b)所示,通过反复计算cross方向上像素的相关性来改进非局部块。然而,它仍然基于像素之间的相关性来描述空间上下文。为此,在SCM模块中提出了一种新的自注意方案,如图5 ©所示。所提出的SCM模块通过计算特征映射和图像中更高层次语义表示(如类特征)之间的关系来探索空间上下文。
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第5张图片](http://img.e-com-net.com/image/info8/c30b96acb87d44adb0f3d269fb278b2f.jpg)
为了在不影响性能的前提下有效地降低计算复杂度,SCM将空间上下文的学习问题转化为特征图上每个像素的类别匹配问题,然后利用像素与类别之间的相关性来描述全局空间上下文信息。SCM模块的结构如图6所示。为使空间上下文信息与通道上下文信息交互,在SCM模块中输入中间特征图 X c X_c Xc和类别特征表示矩阵 M M M。首先分别在 X c X_c Xc和 M M M的基础上使用卷积层进一步降低计算代价,其中 s s s表示降低比率,得到两个新的特征表示 B ∈ R C / s × H × W B \in R^{C / s \times H \times W} B∈RC/s×H×W和 C ∈ R C / s × N C \in R^{C / s \times N} C∈RC/s×N。然后 B B B转换成 R C / s × H W R^{C / s \times H W} RC/s×HW。空间上下文映射 E ∈ R H W × N E \in R^{H W \times N} E∈RHW×N通过一个softmax层来获取:
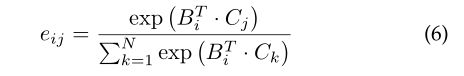
其中 e i j e_{ij} eij表示第 i i i个像素和第 j j j个语义类的相关性得分。它不仅获取像素与类别之间的匹配关系,而且聚合具有相同匹配关系的像素,间接获取像素之间的相关性。
为了进一步改进像素的特征表示,我们使用类特征表示矩阵 M M M重新校准像素的特征表示。将M输入到新的1 × 1卷积层中,生成新的特征图 D ∈ R C / s × N D \in R^{C / s \times N} D∈RC/s×N。然后通过1 × 1卷积更新空间上下文得到特征图 X s ∈ R C × H × W X_{s} \in R^{C \times H \times W} Xs∈RC×H×W:
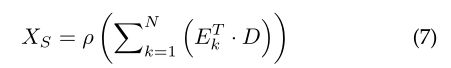
可以推断, X S X_S XS的每个位置表示空间上下文矩阵和类别特征矩阵的加权和。因此,相似的语义特征通过类别特征矩阵实现相互增益。
实验结果
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第6张图片](http://img.e-com-net.com/image/info8/312a5441e0c442e0b240c818496f4fff.jpg)
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第7张图片](http://img.e-com-net.com/image/info8/e6db7bf80d0e4348ba6c500d0aa20042.jpg)
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第8张图片](http://img.e-com-net.com/image/info8/a95c7304d1524a9483737e54e2a1835d.jpg)
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第9张图片](http://img.e-com-net.com/image/info8/64313966310e406d957c0d3c56bdc4f9.jpg)
![[语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation_第10张图片](http://img.e-com-net.com/image/info8/94fe9886c3c349a4a366f10483e35c11.jpg)
总结
本文提出了一种基于上下文的语义分割串联网络(CTNet),该网络充分利用了图像中通道和空间两个重要维度上的上下文信息。具体地,分别开发了通道上下文模型(CCM)和空间上下文模型(SCM)来探索通道上下文和空间上下文信息。同时,我们将这两个模块串联起来进行互动训练,实现两个维度之间的上下文信息相互沟通。CCM学习到的特征可以作为先验知识指导SCM学习,从而改善SCM学习的特征。单片机模块引入了一种新的自注意力机制,在不影响模型性能的情况下提高了模型的效率。