iframe大小自适应_CVPR 2020丨ADSCNet: 自纠正自适应膨胀率计数网络解读

编者按:在CVPR 2020上,商汤团队提出的自纠正自适应膨胀率计数网络,针对计数任务中点标注位置不一致和透视现象造成巨大的尺度变化的问题提出了有效的网络设计和监督方法。在监督方式方面,ADSCNet利用网络学习的结果来纠正不一致的人工标注从而更有效的训练;在网络设计方面,ADSCNet提出自适应膨胀率的卷积结构,不同位置采用不同的膨胀率来适应尺度的变化。ADSCNet在四个公开数据集上均有显著的提升。
论文名称:
《Adaptive Dilated Network with Self-Correction Supervision for Counting》
问题和挑战
目标计数作为计算机视觉的一个重要方向。在工业界有着广泛的应用,例如交通场景下的拥堵判断,视频监视下的流量统计以及地铁中的人流分析等。近年来,使用卷积神经网络(CNN)的方法取得了显著的进展。但是,这项任务仍然具有挑战:
a. 由于密集的场景,对于目标多采用点标注的方式,这就带来标注位置不一致的问题,如下图(a)的黄点,点的位置可能在嘴上,眼睛,耳朵等。那么究竟哪里才是更有利于网络学习的位置呢?
b. 如下图(b)在监控的密集的场景下,不但在不同的场景中目标的尺度差异大,而且在同一张图中也有由于透视现象造成目标会有巨大的尺度变化。

方法介绍
针对以上提出的问题,我们提出了一个新颖的计数框架,如下图所示。它由自适应膨胀卷积网络和自校正监督组成。在这一部分,我们首先会从高斯混合模型(GMM)的角度理解传统的目标密度图,然后我们将介绍如何利用一种期望最大化(EM)的方式进行自纠正更新标签,最后将介绍自适应膨胀率卷积的网络结构和实现细节。

1. 自纠正的监督方式
动机:随着模型的训练的进行,不一致的点标注会影响网络学习的上限。通过观察发现学习一定时间以后,网络预测的密度在响应位置一致性上好于人工标注。所以我们希望通过利用网络的预测来纠正标注的位置,从而得到更一致同时更有利于网络学习的密度图标签。
方法:
将高斯密度图看作一个高斯混合模型(GMM):
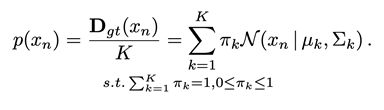
其中D表示高斯密度图,K表示目标个数,x表示图中的位置
这里可以用人工标注的点作为均值,固定值为方差,生成高斯混合模型的初始分布,而网络预测的密度图可以近似看作网络根据图像特征预测的一个目标分布。我们的方法就是利用网络预测来以一种类似期望值最大化(EM)的方式更新高斯混合模型从而得到适合的标签。
具体方式如下:
E步骤:

M步骤:
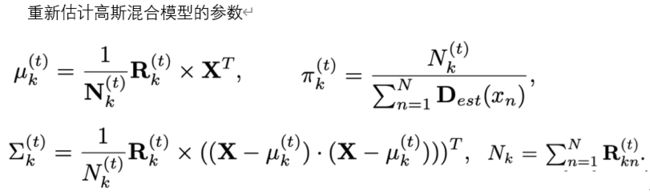
其中X表示位置矩阵随着E和M交替执行,我们会得到更一致响应的标签。在更新的过程,由于已知每个目标对于整体的分布是相同的,所以对于重新估计的权重系数π我们会固定为1/K.
自纠正损失函数:
提出的自纠正损失函数包含两个部分,一个部分是直接全图和纠正后密度图比较L1距离,这部分关注整图数量上的误差,第二部分为权重系数的监督,主要关注个体,保证对于整体的贡献一致
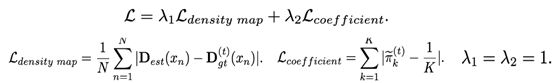
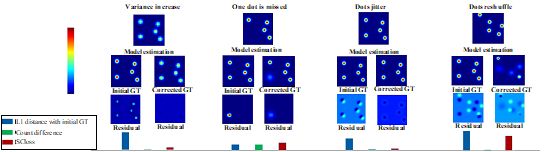
总体而言,提出的自纠正监督具有许多理想的属性。 首先,它能够容忍标注偏差。 动态更新目标密度图可以纠正某些标签的偏差,以帮助模型学习到一致的特征表达。 其次,对于方差的变化是鲁棒的。 可以根据图像特征采用迭代调整方差以适应响应区域。 第三,它对象数量的变化很敏感。 混合系数的波动有效地反映了漏检和误检。 下面展示了密度图估计中的四种常见情况(抖动,方差增加和高斯核的变化)自纠正的对比。
2. 自适应膨胀率网络结构
我们从两个角度设计了自适应膨胀卷积
- 从尺度变化方面,我们使用连续的感受野也来匹配连续的尺度变化。
- 为了学习空间感知,不同的位置回采用不同的膨胀率来进行采样。
下图为我们的自适应膨胀卷积的过程:
步骤1:以相同特征为输入,通过标准3×3卷积层得到一张与原图相同大小的单通道的膨胀率图。特别地,我们添加了一个ReLU层来保证膨胀率图上值都为非负数。
步骤2:对特征进行自适应感受野的采样,不同位置的采样网格大小为膨胀率图对应位置的值,这个值可能会是小数,这里我们采用了双线性插值进行采样
步骤3:对采样值进行加权求和得到新的特征
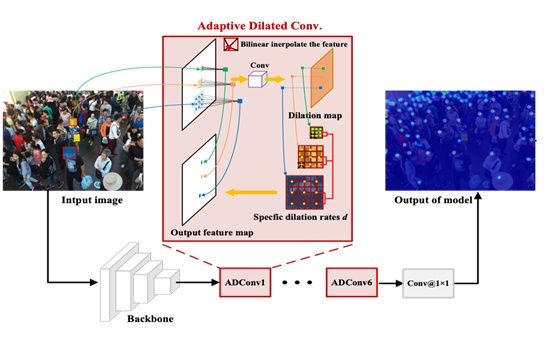
我们的自适应膨胀率卷积不需要额外的尺度标签,只需要最后的密度标签就可以让网络自己学习适应不同尺度的目标。同时相比较形变卷积[1],我们的采样网格中是完全对称的,采样的特征不会有相对目标位置上的偏差,和最终目标的位置有更好的一致性,更加适合计数这种位置敏感性的任务。
实验结果
下图为可视效果的对比,可以看出,ADSCNet相比较传统的监督预测的密度图主要有两方面的优势:1.不同目标更一致的响应强度 2.不同目标响应的位置更加一致。响应点主要集中头部的左上角轮廓处,表明了相对于人工标注的眼睛,鼻子等,头部轮廓是相对更不容易遮挡,更适合计数任务的特征点。通过下图第四列可以看到整体上大的目标需要更大感受野,一些有语义的背景目标也需要更大的感受野去区分。

同时我们也进行消融实验的对比,首先我尝试了有效的数据增加方式,加入BN和增大batchsize来确立新的Baseline。我们这里复现了CSRNet[2]和MCNN[3]作为Baseline方法进行比较,如下图首先是自纠正监督的效果。自适应监督在三个baseline上取得了一致的提升。 他们相对的MAE提升分别为6.19%,8.57%,8.72%。

而自适应膨胀卷积方面,我对比了不同的固定膨胀率和多列网络组合以及形变卷积的效果。相比较固定的膨胀率,我们只增加了有限的运算,却取得了明显的提升。

最后和当前SOTA的对比,ADSCNet在四个公开数据集取得更优的表现,并有着明显的提升,表明了我们方法的有效性。

结语
在本文中,我们为计数问题提出了一种新颖的监督学习框架。它利用模型估计来迭代地纠正GT,并提出自纠正损失函数同时监督整体的数量和个体的分布。同时这种方法可以应用到所有基于CNN的方法中。另一方面,我们提出了自适应膨胀卷积,它通过每个位置的动态地学习不同的膨胀率以适应目标巨大的尺度变化。在四个数据集上进行的实验表明,它可以显著提升计数网络的性能。 同时也说明了利用模型从图像特征上学习的信息能够被用于纠正标注来提升性能。
References
[1] Dai, Jifeng, et al. Deformable convolutional networks. In ICCV, 2017.
[2] Li, Yuhong, Xiaofan Zhang, and Deming Chen. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In CVPR, 2018.
[3] Zhang, Yingying, et al. Single-image crowd counting via multi-column convolutional neural network. In CVPR, 2016