文章-宫颈长度与双胎自发性早产的相关性研究
文章中的统计学方法描述如下:
计量资料采用 (珚x ± s) 进行统计描述 , 定性资料采用频数和构成比描述 , 采用 t 检验或单因素方差分析比较不同组间的宫颈长度 , 采用 Pearson 相关分析孕周和宫颈长度的相关性 , 采用受试者工作曲线 (ROC) 分析宫颈长度预测早产的风险 ;上述统计学分析均采用 S P S S 2 3. 0 统计软件进行分析 ; 检验 水准 α = 0. 0 5 。
下面是分步解读
- 研究对象的基本特征
计量资料采用 (x ± s) 进行统计描述 , 定性资料采用频数和构成比描述 ,103 例研究对象的基本特征。 平均年龄为 (32.44 ± 4.31) 岁 ,平均孕周为 (35.11 ± 2.15) 周 , 早产史和分娩时的孕周比例 。
1.计量资料以 x±s 表示(x:均值;s:标准差)
2.数据类型
在医学论文中,数据分为三种类型:计数,计量和等级。
计数数据是定性观察的结果, 例如患者的性别、职业等等。统计指标是各个属性或类别的计数,率,结构百分比等等。
计量数据是定量观察的结果, 通常有度量单位,例如患者的年龄 、血压、心率等等。统计指标常用平均数±标准差来表示。
等级数据介于定性观察和定量观察之间。观察结果有等级或程度上的差别, 但不能用数量表示,例如疗效评价(包括无效,有效,显著等)。
http://www.datasoldier.net/archives/1408
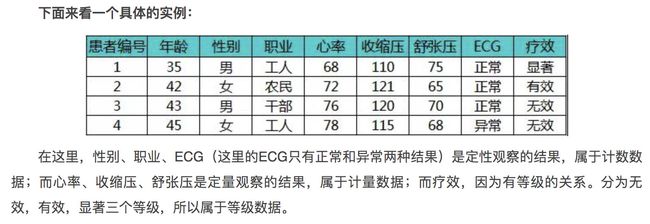
==所以文章中的计量资料表示方式如下图==

若是计数资料,就涉及到率的可信区间、单个率的比较、多个率的比较。
若是计量资料,就涉及到均值的可信区间、单个均值的比较、多个均值的比较。
上图中可见标注绿色的是计量资料,就是用的 (x ± s) 进行描述的,其他未标注绿色的是计数资料,用的是就是构成比例%进行描述。
http://paper.dxy.cn/article/278773
3.描述性统计
描述性统计包含多种基本描述统计量,让用户对于数据结构可以有一个初步的认识。
在此所提供之统计量包含:
基本信息:样本数、总和
集中趋势:均值、中位数、众数
离散趋势:方差(标准差)、变异系数、全距(最小值、最大值)、内四分位距(25%分位数、75%分位数)
-
分布描述:峰度系数、偏度系数
https://www.cnblogs.com/tychyg/p/5277156.html
均数mean
中位数median
方差var
标准差sd
变异系数(Coefficient of Variation):sd(Nile)/mean(Nile)
4.采用 t 检验或单因素方差
- 不同孕周的产妇的宫颈长度
经单因素方差分析 , 四组研究对象的宫颈长度具有统计学差异 (F=62.797,P<0.0001);经 LSD 两两比较 , 各组之间均具有统计学差异 (31 ~ 32 周 vs 28 ~ 30 周除外)
比较两个独立分组在单一变量上的均值,可以使用独立样本t检验,也可以使用单因素方差分析。
如果比较三个或三个以上分组时就会使用方差分析。
两者的结论是一样的,t检验得到 t 值,方差分析得到 F 比率, F 比率是t 值的平方。
进行单因素方差分析时,需要一个分类(或名义)变量作为自变量,以及一个连续变量(例如考试成绩)作为因变量,自变量至少分出两个独立的组别。
------参考《白话统计学》第10章-单因子方差分析
F值:组均值之间的平均差异于各组内部的平均变异之比,即表明整体而言组均值之间是否存在显著差异。但不能止于F值,接下来进行事后检验可以确定哪几组不同,就用可以用多重比较法。
==F值的计算公式如下==

==关于F值的计算过程举例如下图==



- 这篇文章中算出的F值是62.797,==对应着附录表pdf文档的附表五:F 分布临界值表(α=0.05),因此分子分子自由度为4(总共5组,5-1=4),5组共有103例研究对象,分母自由度是103-5=98,对应着附录表5中的α值=0.05时,F临界值是2.47和2.46之间,而本文算出的F值是62.797,远大于2.47,所以对应的p值是<0.0001,这个结论认为结果是统计显著的。(这里的α和p值的含义是差不多的,都是代表统计结果是否显著的)==
5.多重比较
LSD: 方差分析主要是用于多组均值比较的,方差分析的结果是多组均值之间是否有显著性差异,但是这个显著性差异是整体的显著性差异,可是我们并不知道具体是哪些组之间有显著性差异。所以就有了多重比较,目的就是为了获取具体哪些组之间有显著差异。其中有一个方法称为“Fisher 氏最小显著差检验(Fisher's least significant difference, 简称LSD 检验)”
下面的这个链接中举了一个很好的例子,有助于理解老师的文章中的一句描述就是------经 LSD 两两比较 , 各组之间均具有统计学差异 (31 ~ 32 周 vs 28 ~ 30 周除外)
https://blog.csdn.net/junhongzhang/article/details/102774432
- 宫颈长度与孕周的相关性
采用 Preason 相关分析宫颈长度与孕周间的相关性 ,分析结果显示 ,宫颈长度与孕周呈负相关关系 , 具有统计学意义 (r= -0.745,P<0.0001),提示: 宫颈长度对孕周的增大而降低

6.相关性分析
对两个或两个以上变量的关系的研究就是相关性分析,变量间关联的最基本测度之一是相关系数,科学研究中最常用的就是皮尔逊积差相关系数( Preason ),对于计算皮尔逊相关系数而言,要求两个变量必须是定距或定比的连续变量。相关性有正相关和负相关,分别用正和负号表示。“-” 表示负相关。相关系数绝对值>0.5(或正或负),表示强相关。Preason相关系数的符号==用r表示==,当计算相关性系数时,如果想知道检验相关系数是否统计显著,常用==t分布检验==来检验相关系数是否统计显著。
==下面是t值的计算公式==

老师的文章中的r是0.745,N是103,自由度就是103-2=101,计算后t值是11.22,去附录表pdf文档的附表三: t 分布临界值表得到df自由度是100时对应的t值是2.626,这是的p值是0.005,我们计算的11.22要远大于2.626,所以显著性p值要更加小,就是更显著(但是我没找到更全面的对应表,意思大概是这样的)
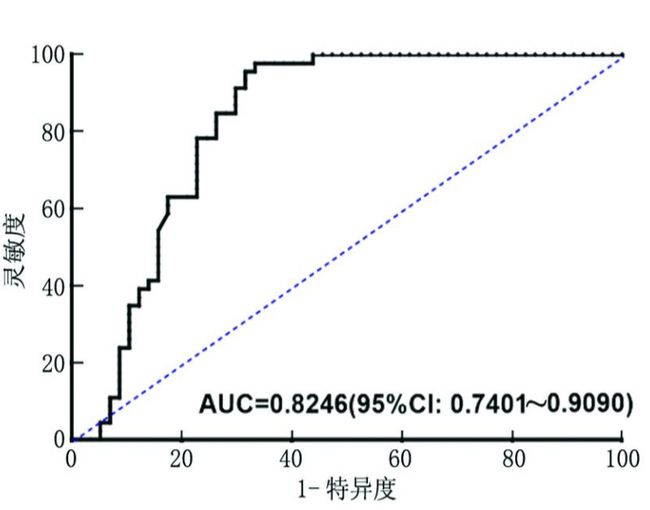
- 宫颈长度预测早产风险 ROC 曲线
采用 ROC 曲线分析宫颈长度预测早产风险的价 值 , 见图 3 。 宫颈长度预测早产风险的 ROC 曲线显
示 ,宫颈长度对预测双胎早产具有较高的临床价值
7.ROC曲线和AUC面积
第一个指标---==纵轴==TPR,要越高越好。而把没病的样本误诊为有病的,也就是第二个指标---==横轴==FPR,要越低越好,所以就是曲线上的点越靠近左上角,AUC的面积越大,这样的结果就是预测的结果越接近实际的结果。
https://mp.weixin.qq.com/s/RGCER1Wp3jU2DPWfT3J51g
文章中的AUC面积是0.8246,是很高的结果,一般大于0.7都是很好的预测模型。同时还是需要P值来对这个模型是否统计显著进行描述,P<0.05就可以。文章中的宫颈长度预测早产风险的灵敏度为 97.83% 、诊 断 截 断点为27. 58 mm 、 特异度为 66.67% 是计算AUC面积过程中产生的值,置信区间也是。