Swin Transformer: Hierarchical Vision Transformer using Shifted Windows论文阅读
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows论文阅读
-
-
- 摘要
- 介绍
- 相关工作
- 方法
-
- 整个架构
- 基于self-attention的shifted window
- 架构变种
- 实验
-
- 图像分类
- 目标检测
- 语义分割
- 消融实验
-
paper:https://arxiv.org/pdf/2103.14030v1.pdf
code: https://github.com/microsoft/Swin-Transformer
摘要
采用transformer来做计算机视觉任务有两个挑战:
(1)视觉目标的尺度具有很大的变化;
(2)相比于文本,高分辨率的像素具有很大的计算量;
为了解决这些不同,论文提出一个层级的transformer,并采用shifted windows计算表示;
shifted windows带来了巨大的高效性,通过限制self attention在non-overlapping局部窗口的计算量,并保持cross-window连接;
这个层级架构可以很灵活的对不同尺度建模,并且随着image-size线性的增加计算量;
Swin transformer在图像分类imagenet达到86.4的top 1准确率,在密集任务目标检测coco test-dev上达到58.7box AP和51.1 mask AP,
语义分割ADE20K val上达到53.5mIOU,在coco上超过之前的SOTA+2.7 box AP、+2.6 mask AP,在ADE20K上超过之前的SOTA+3.2mIOU;

介绍
transformer在NLP取得巨大的成功,使研究者将transformer迁移到视觉任务上,然而最近的研究也证明transformer能够在视觉任务取得较好的效果;
在该论文中,作者寻求将transformer扩展为计算机视觉通用的backbone,现在很多的视觉任务(比如说语义分割)需要密集像素级别的预测,这往往需要很高的分辨率,但image-size的增加会给self-attention带来二次方的计算复杂度,为了克服这个问题,作者提出了一个通用的transformer backbone,叫做swin transformer;
如图1所示,swin transformer设计了一个层级的表示,从小的patches开始,然后在更深的transformer层逐步融合邻近的patches;通过这个层级特征图,swin transformer模型可以很好的利用密集预测器先进的技术,比如说FPN和Unet;线性增长的复杂度通过局部计算non-overlapping滑窗的self-attention实现;
每个窗口的patches数量是固定的,因此复杂度是随着image-size的增长线性增长;这些优点使得swin transformer可以为多个视觉任务作为一个通用的backbone;之前基于transformer的架构,只是用单层特征图,且有着二次方增长的复杂度;
swin transformer关键的设计是:self-attention层之间窗口划分的shift,如图2所示;shifted 窗口连接上一层的窗口,提供了它们之间的连接,显著增强了建模能力(见表4)。这个策略对于实际上的延迟也很有效:一个窗口所有query patches共享一个key集,这为硬件节省了内存;之前的transformer方法在实际硬件上具有高延时,由于不同query像素上不同的key集;论文的实验证明shifted 窗口方法有比滑窗方法更低的延时,并有着相似的建模能力(见表5和6);
论文提出的swin transformer在不同回归任务,图像分类,目标检测,语义分割上都有着强大的性能表现,性能胜过ViT/DeiT和ResNe(X)t;
相关工作
基于self-attention的backbone架构:一些工作采用self-attention来部分代替或者全部代替卷积网络ResNet,在这些工作中,通过一个局部窗口的每个像素来计算self-attention,从而促进优化,他们通常比传统卷积架构ResNet实现了更好的精度与FLOPs的兼容,然而他们所占用硬件的内存和延时也高于传统卷积网络;相比于滑窗,我们提出在连续层之间shift窗口,能够在硬件上更高效的实现;
self-attention/transformer增强CNNs:另一部分工作是使用self-attention或者transformer来增强标准的CNN架构,self-attention层通过提供捕捉长距离依赖性或者说是更多的交互来增强backbones和heads网络;作者探索了transformers的适应性,用于基本的视觉特征提取,是对这些工作的补充;
基于transformer的视觉backbones:与该工作最相关的是视觉transformer(ViT)[19]及其后续[60, 69, 14, 27, 63];先驱工作ViT直接在图片patches上采用transformer架构来实现图像分类,它实现了很好的速度与精度的平衡;但是ViT需要在更大的数据集上训练才能够有较好的性能,DeiT引入几个训练策略使得ViT也能够在较小的数据集ImageNet-1K上取得较好性能;ViT在图像分类上的结构是很不错的,但是不适合作为通用的骨干网络在密集任务上使用,或者说由于他的低分辨率特征图和随着image-size二次方增长的复杂度;作者的工作可以看作是在ViT架构上的改进,获得了更好的性能;即便是按照通用backbone的原则设计,swim transformer也能在图像分类上实现更好的速度与精度的平衡;有一些工作[63]也是使用transformer添加多层特征图,但是他的复杂度还是随着image-size二次方增长;
方法
整个架构
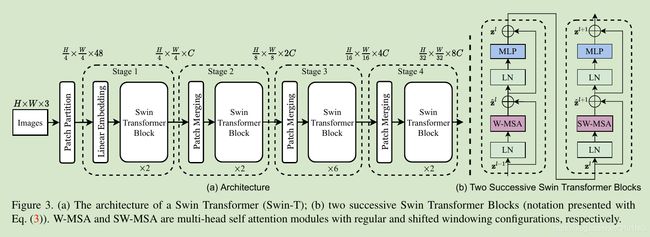
swin transformer的架构如图3所示(tiny版本),首先像ViT一样,将输入图片分成多个patches,作者使用4x4的patch-size,然后跟着的是一个embedding层,之后就是作者提出的swin transformer block;
swin transformer block:该模块是使用基于shifted窗口的模块替换transformer中的多头self-attention模块,其他都是一致;如图3(b)所示,一个swin transformer模块包括一个基于MSA(多头attention)模块的shifted window,之后是一个2层的MLP,LayerNorm层添加到每个MSA模块和每个MLP层之前,然后是一个残差连接;
基于self-attention的shifted window
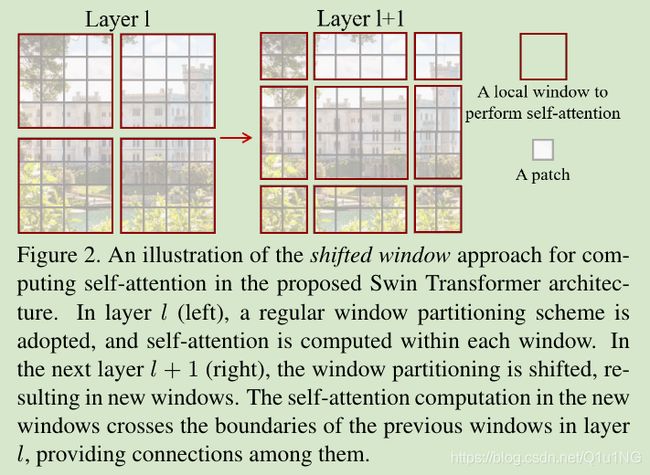
标准的transformer使用全局self-attention,建立一个token与其他所有tokens的关系,这带来了与image-size成二次方的复杂度增长,不适合用于密集任务;
为了高效建模,作者提出使用局部窗口计算self-attention,假定每一个窗口包含MxM个patches,一个全局MSA模块和一个基于窗口的MSA模块在有hxw patches的图片上计算复杂度为:
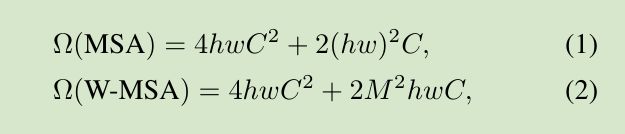
其中(1)复杂度是patch数量hw的二次方增长,而(2)是线性增长,其中M是固定的,全局self-attention是负担不起一个很大的hw,然而基于窗口的self-attention是可以的;
连续block中的shifted 窗口分割
基于windows的self-attention虽然说是复杂度是线性增长的了,但是缺乏跨windows的连接,这限制了模型的建模能力;
为了在维持模型高效的情况下,引入跨windows的连接,作者提出shifted窗口分割,如图2所示,第一个module使用整齐的窗口分割,将一个8x8的特征图按照M=4的窗口大小,分割为2x2,然后下一个模块采用一个shifted的窗口设置,移动M/2的像素;
有了shifted结构,swin transformer blocks的计算如下:

其中W-MSA和SW-MSA分别代表使用整齐分割和shifted的self-attention;
shifted window可以为模型添加跨windows的连接,并且可以保持模型的高效性,如表4所示;
shifted window的高效batch计算
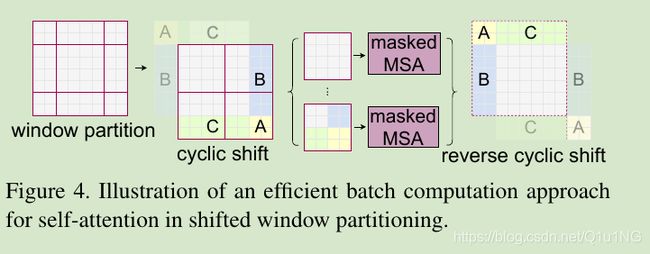
shifted window有一个问题就是这会导致更多的windows,从(h/M x w/M)到((h/M+1) x (w/M+1)),并且有些windows会比MxM更小;一个做法是填充更小的windows到MxM,计算注意力再遮掩填充的值;当整齐分割windows的数量较少时,比如说2x2,使用该策略增加的计算量会很多(2x2 -> 3x3会带来2.25倍的计算量);所以作者提出了一个更高效的batch计算方法,通过沿着左上角方向进行cycilc shifting,如图4所示;经过这个shift之后,一个batched window有特征图上几个不邻近的sub-windows组成,因此使用masking机制来限制self-attention在sub-windows内进行计算,使用cyclic-shift,batched-windows的数量和整齐分割windows的数量一致,可以大大提高计算效率,该方法的低延时如表5所示;
相对位置bias
作者在self-attention中为每个头引入一个相对位置bias B:
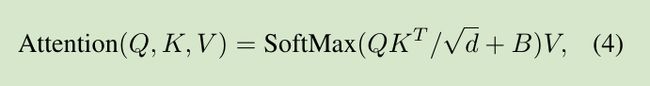
其中
![]()
![]()
如表4所示,这带来了明显的性能提升;
架构变种
作者建立了基础模型,称为Swin-B,根据模型大小和计算复杂度,还引入了Swin-T,Swin-S和Swin-L,大概0.25×、0.5×和2×的模型大小和复杂度;
其中窗口大小M设置为7,每个头的query唯独d=32,每个MLP的expansion层α=4:

其中C是第一个stage中隐藏层的通道数;
实验
图像分类
表1a,在imagenet-1k上从头开始训练:
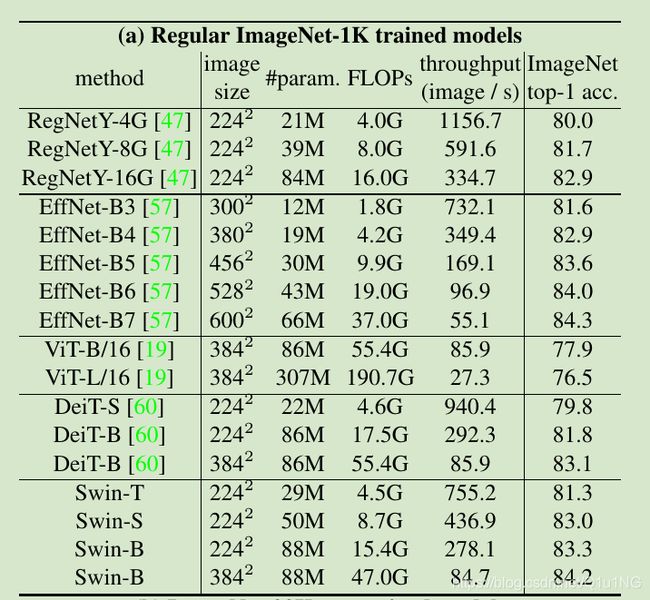
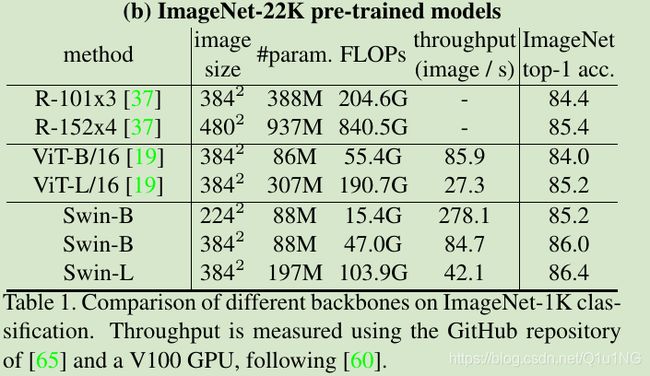
表1b,首先在imagenet-22k上预训练,再1迁移到imagenet-1k上:
目标检测
表2a,在不同模型框架上,使用swin transformer替换backbone:
表2b,在cascade RCNN上实验多个backbone:
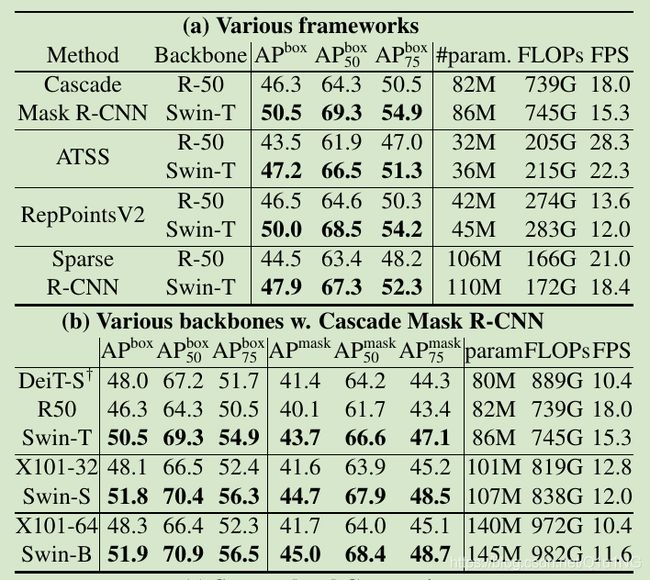
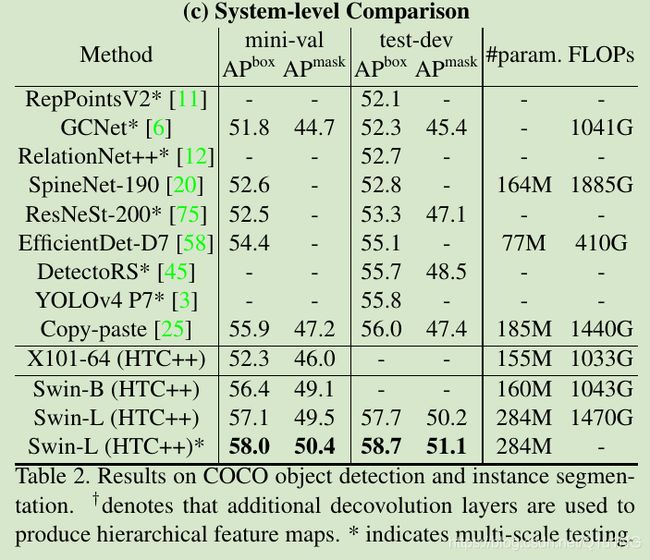
表2c,与SOTA比较:
语义分割
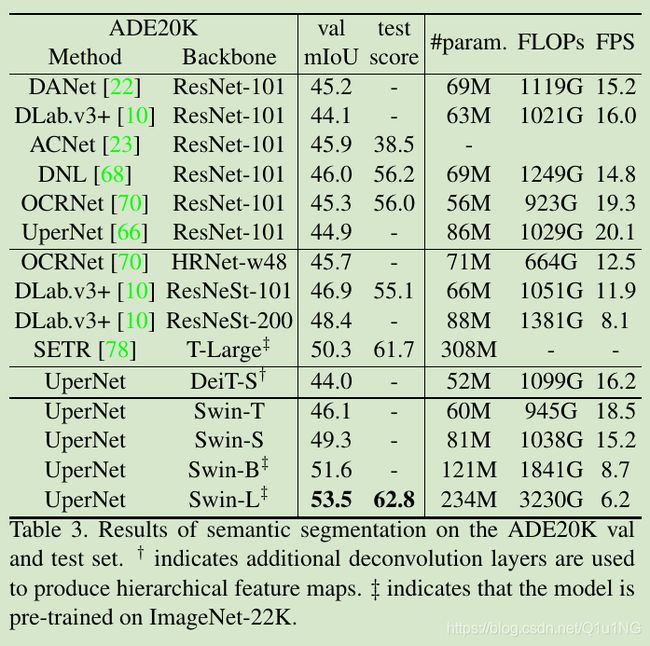
表3,以更小的模型实现了比之前的SOTA SETR更高的mIOU:
消融实验
表4,shifted window和相对位置bias带来的性能提升:
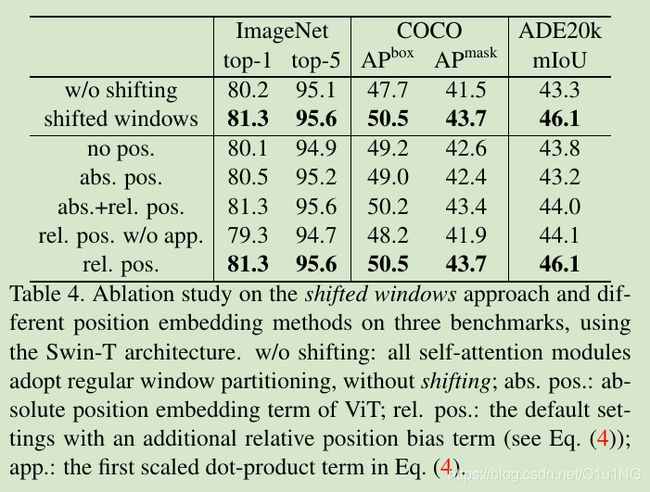
表5,shifted window和cycilc 带来的高效性:
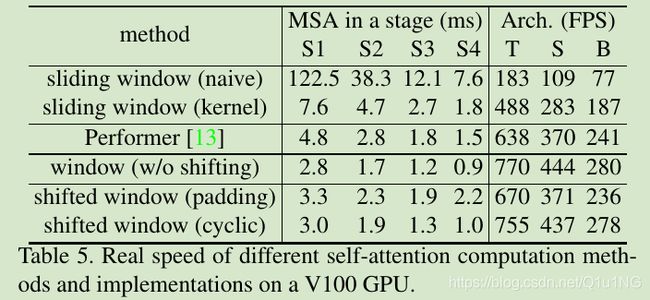
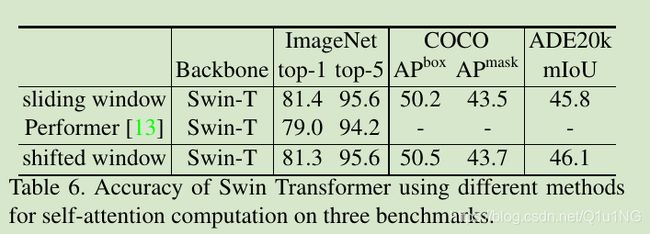
表6,使用不同的self-attention比较: