推荐算法学习笔记之Deep&Wide模型
文章目录
- 模型简介
-
- 解决的痛点:
- 模型结构
-
- wide
- Deep
- 模型代码(主要基于TensorFlow)
- 部分训练过程
- 总结
模型简介
Wide&Deep模型是由谷歌于2016年提出,并在Google Play store的场景中成功落地。模型特点是由wide部分为模型提供记忆能力,由deep部分提供泛化能力
解决的痛点:
传统的DNN(Deep Neural Networks,深度神经网络)能将高维稀疏特征编码为低维稠密的Embedding vector,这种基于Embedding的方式能够有效提高模型的泛化能力。但是,基于Embedding的方式可能因为数据长尾分布,导致长尾的一些特征值无法被充分学习,其对应的Embedding vector是不准确的,这便会造成模型泛化过度(过拟合)。
模型结构
如下图所示,模型由wide和deep两部分构成
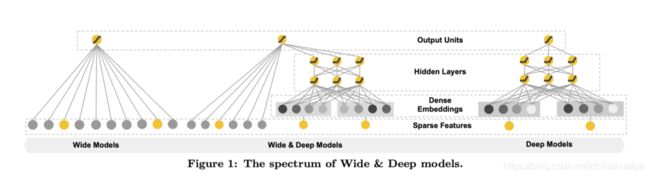
(图1)
wide
上文简介部分我们提到,该部分为模型提供记忆能力–通过特征叉乘对原始特征做非线性变换,输入为高维度的稀疏向量。通过大量的特征叉乘产生特征相互作用的“记忆(Memorization)”
数学原理:
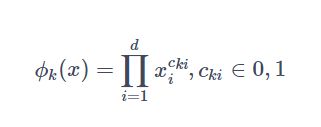
其中Cki是一个布尔变量,当第i个特征属于第k个特征组合Φk时,Cki值为1,否则为0,Xi是第i个特征的值,当Cki和Xi值1都为1时,结果才为1
例如特征组合"AND(gender=female, language=en)",如果对应的特征“gender=female” 和“language=en”都符合,则对应的交叉积变换层结果才为1,否则为0。
Deep
该部分主要是一个Embedding+MLP的神经网络模型(如图1)。大规模稀疏特征通过embedding转化为低维密集型特征。然后特征进行拼接输入到MLP中,挖掘藏在特征背后的数据模式。
模型代码(主要基于TensorFlow)
import warnings
warnings.filterwarnings("ignore")
import itertools
import pandas as pd
import numpy as np
from tqdm import tqdm
from collections import namedtuple
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
# 简单处理特征,包括填充缺失值,数值处理,类别编码
def data_process(data_df, dense_features, sparse_features):
data_df[dense_features] = data_df[dense_features].fillna(0.0)
for f in dense_features:
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
for f in sparse_features:
lbe = LabelEncoder()
data_df[f] = lbe.fit_transform(data_df[f])
return data_df[dense_features + sparse_features]
def build_input_layers(feature_columns):
# 构建Input层字典,并以dense和sparse两类字典的形式返回
dense_input_dict, sparse_input_dict = {
}, {
}
for fc in feature_columns:
if isinstance(fc, SparseFeat):
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
elif isinstance(fc, DenseFeat):
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
return dense_input_dict, sparse_input_dict
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
# 定义一个embedding层对应的字典
embedding_layers_dict = dict()
# 将特征中的sparse特征筛选出来
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
if is_linear:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, 1, name='1d_emb_' + fc.name)
else:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='kd_emb_' + fc.name)
return embedding_layers_dict
def get_linear_logits(dense_input_dict, sparse_input_dict, sparse_feature_columns):
# 将所有的dense特征的Input层,然后经过一个全连接层得到dense特征的logits
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
dense_logits_output = Dense(1)(concat_dense_inputs)
# 获取linear部分sparse特征的embedding层,这里使用embedding的原因是:
# 对于linear部分直接将特征进行onehot然后通过一个全连接层,当维度特别大的时候,计算比较慢
# 使用embedding层的好处就是可以通过查表的方式获取到哪些非零的元素对应的权重,然后在将这些权重相加,效率比较高
linear_embedding_layers = build_embedding_layers(sparse_feature_columns, sparse_input_dict, is_linear=True)
# 将一维的embedding拼接,注意这里需要使用一个Flatten层,使维度对应
sparse_1d_embed = []
for fc in sparse_feature_columns:
feat_input = sparse_input_dict[fc.name]
embed = Flatten()(linear_embedding_layers[fc.name](feat_input)) # B x 1
sparse_1d_embed.append(embed)
# embedding中查询得到的权重就是对应onehot向量中一个位置的权重,所以后面不用再接一个全连接了,本身一维的embedding就相当于全连接
# 只不过是这里的输入特征只有0和1,所以直接向非零元素对应的权重相加就等同于进行了全连接操作(非零元素部分乘的是1)
sparse_logits_output = Add()(sparse_1d_embed)
# 最终将dense特征和sparse特征对应的logits相加,得到最终linear的logits
linear_logits = Add()([dense_logits_output, sparse_logits_output])
return linear_logits
# 将所有的sparse特征embedding拼接
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
# 将sparse特征筛选出来
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
embedding_list = []
for fc in sparse_feature_columns:
_input = input_layer_dict[fc.name] # 获取输入层
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
embed = _embed(_input) # B x dim 将input层输入到embedding层中
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
if flatten:
embed = Flatten()(embed)
embedding_list.append(embed)
return embedding_list
def get_dnn_logits(dense_input_dict, sparse_input_dict, sparse_feature_columns, dnn_embedding_layers):
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values())) # B x n1 (n表示的是dense特征的维度)
sparse_kd_embed = concat_embedding_list(sparse_feature_columns, sparse_input_dict, dnn_embedding_layers, flatten=True)
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed) # B x n2k (n2表示的是Sparse特征的维度)
dnn_input = Concatenate(axis=1)([concat_dense_inputs, concat_sparse_kd_embed]) # B x (n2k + n1)
# dnn层,这里的Dropout参数,Dense中的参数及Dense的层数都可以自己设定
dnn_out = Dropout(0.5)(Dense(1024, activation='relu')(dnn_input))
dnn_out = Dropout(0.3)(Dense(512, activation='relu')(dnn_out))
dnn_out = Dropout(0.1)(Dense(256, activation='relu')(dnn_out))
dnn_logits = Dense(1)(dnn_out)
return dnn_logits
# Wide&Deep 模型的wide部分及Deep部分的特征选择,应该根据实际的业务场景去确定哪些特征应该放在Wide部分,哪些特征应该放在Deep部分
def WideNDeep(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# Wide&Deep模型论文中Wide部分使用的特征比较简单,并且得到的特征非常的稀疏,所以使用了FTRL优化Wide部分(这里没有实现FTRL)
# 但是是根据他们业务进行选择的,我们这里将所有可能用到的特征都输入到Wide部分,具体的细节可以根据需求进行修改
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
# 在Wide&Deep模型中,deep部分的输入是将dense特征和embedding特征拼在一起输入到dnn中
dnn_logits = get_dnn_logits(dense_input_dict, sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
# 将linear,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layer = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layer)
return model
if __name__ == "__main__":
# 读取数据
data = pd.read_csv('./data/criteo_sample.txt')
# 划分dense和sparse特征
columns = data.columns.values
dense_features = [feat for feat in columns if 'I' in feat]
sparse_features = [feat for feat in columns if 'C' in feat]
# 简单的数据预处理
train_data = data_process(data, dense_features, sparse_features)
train_data['label'] = data['label']
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
for feat in dense_features]
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
for feat in dense_features]
# 构建WideNDeep模型
history = WideNDeep(linear_feature_columns, dnn_feature_columns)
history.summary()
history.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
# 将输入数据转化成字典的形式输入
train_model_input = {
name: data[name] for name in dense_features + sparse_features}
# 模型训练
history.fit(train_model_input, train_data['label'].values,
batch_size=64, epochs=5, validation_split=0.2, )
部分训练过程
Epoch 1/5
3/3 [==============================] - 2s 778ms/step - loss: 0.8376 - binary_crossentropy: 0.8376 - auc: 0.4508 - val_loss: 1.1011 - val_binary_crossentropy: 1.1011 - val_auc: 0.4986
Epoch 2/5
3/3 [==============================] - 0s 62ms/step - loss: 0.8176 - binary_crossentropy: 0.8176 - auc: 0.4761 - val_loss: 0.7597 - val_binary_crossentropy: 0.7597 - val_auc: 0.4886
Epoch 3/5
3/3 [==============================] - 0s 61ms/step - loss: 0.6375 - binary_crossentropy: 0.6375 - auc: 0.5239 - val_loss: 0.7511 - val_binary_crossentropy: 0.7511 - val_auc: 0.5912
Epoch 4/5
3/3 [==============================] - 0s 59ms/step - loss: 0.5976 - binary_crossentropy: 0.5976 - auc: 0.6104 - val_loss: 0.6745 - val_binary_crossentropy: 0.6745 - val_auc: 0.5997
Epoch 5/5
3/3 [==============================] - 0s 48ms/step - loss: 0.5190 - binary_crossentropy: 0.5190 - auc: 0.6963 - val_loss: 0.6332 - val_binary_crossentropy: 0.6332 - val_auc: 0.6638
总结
wide&deep挺好,就是理解起来有点费脑。在博客上仍有精进的空间,可以加个数学公式等,加油~