推荐算法-Deep & Cross Network
推荐算法Deep & Cross Network
这篇文章是谷歌在2017年的一篇文章,是用在广告点击率预估上面的。从文章题目上来看,应该是包含两大块,Cross和Deep两个部分。原因应该很简单,还是在特征的组合上做文章。但是看完这篇文章之后,感觉很清爽,就是思路比较简单,而且实现起来也很方便。
一、Deep & Cross Network出现的原因
前面提到了FM和DeepFM两个方法,也是在特征组合上做了改进。FM还只是停留在二阶特征组合上,DeepFM是将深度模型和FM并行处理。而本篇文章介绍的是模型分为Cross Network和Deep Network两个部分。目的也是为了实现更高阶的特征组合,但是它在特征预处理或者构造方面不需要人为的做更多操作。而是直接将类别型特征进行one-hot处理,对于数值型特征直接保留原始数值。然后直接将类别型特征的embedding和数值型特征concat在一起,作为Cross Net和Deep Net的输入。
二、Deep & Cross Network结构
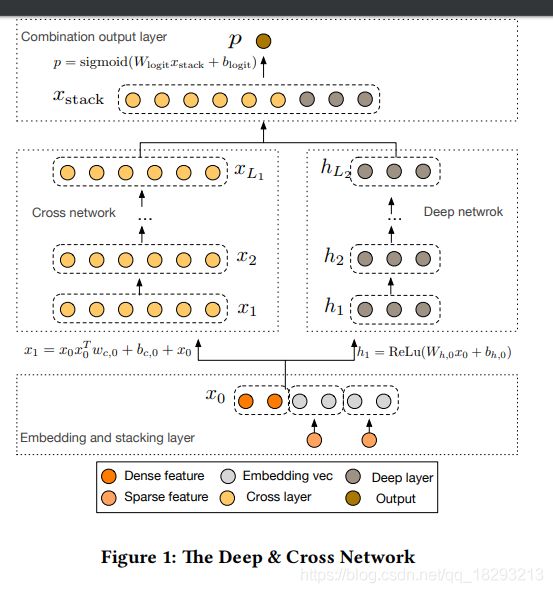
结构比较简单,输入就是上文提到的,one-hot类型的特征embedding之后与数值类型的特征合并在一起作为整个模型的输入,输入表示如下:
x 0 = [ X e m b e d , 1 T , X e m b e d , 2 T . . . X e m b e d , k T , X d e n s e T ] x_{0}=[X_{embed, 1}^{T}, X_{embed, 2}^{T}...X_{embed, k}^{T}, X_{dense}^{T}] x0=[Xembed,1T,Xembed,2T...Xembed,kT,XdenseT]
模型分为两个部分,左边是Cross Net 右边是Deep Net。
Deep Net部分很简单,就是几层全连接层。
Cross Net部分比较有意思,Cross Net主要是想显示的实现各个特征之间的交叉,并且随着层数的加深,特征交叉的程度会增大。下图表示了特征交叉的过程:
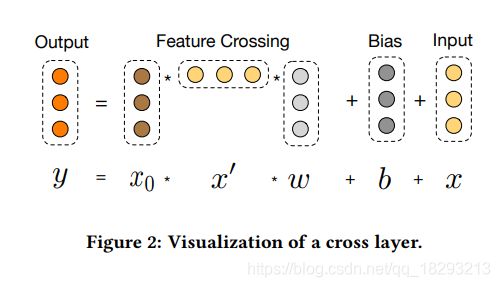
可以看出某一层进行特征组合的过程中有 x 0 x_{0} x0即原始的输入特征,有当前层的特征 x x x以及改层特征的转置 x ′ x^{'} x′。而且输入特征的维度和输出特征维度是一致的。整体的表达式如下:
x l + 1 = y = x 0 ∗ x l ′ ∗ w l + b l + x l x_{l+1}=y=x_{0}*x_{l}^{'}*w_{l}+b_{l}+x_{l} xl+1=y=x0∗xl′∗wl+bl+xl
可以看出每一层的输出是由输入和前一层的输出组合得到的结果。在 x 0 ∗ x l ′ x_{0}*x_{l}^{'} x0∗xl′部分,是输入的每一个特征与l层的每一个组合特征进行交叉相乘,即实现了每一个特征之间的组合,而且是层数越深,组合的阶数也就越高。并且还引入了残差的思想,即最后又加上了 x l x_{l} xl,防止计算过程中出现梯度的弥散现象。充分的发挥了特征之间的组合能力,而且这种做法不需要在数据预处理阶段手工的进行各种特征之间的组合了。
Deep和Cross部分计算完成之后,都会输出一组特征向量,然后直接将这两组特征向量concat起来,然后进行分类就完成了分类。输入表示为:
p = s i g m o i d ( W ∗ X s t a c k + b ) p=sigmoid(W*X_{stack}+b) p=sigmoid(W∗Xstack+b)
X s t a c k = c o n c a t ( [ X d e e p , X c r o s s ] , a x i s = 1 ) X_{stack}=concat([X_{deep}, X_{cross}], axis=1) Xstack=concat([Xdeep,Xcross],axis=1)
X c r o s s X_{cross} Xcross的大小就是输入数据的特征维度,即 n u m e r i c _ s i z e + f i e l d _ s i z e ∗ e m b e d d i n g _ s i z e numeric\_size+field\_size*embedding\_size numeric_size+field_size∗embedding_size,field_size就是需要进行one-hot的特征个数,embedding_size就是每一个特征在嵌入层的维度。
X d e e p X_{deep} Xdeep的维度是最后一层全连接层的特征维度。
X s t a c k X_{stack} Xstack的维度就是 n u m e r i c _ s i z e + f i e l d _ s i z e ∗ e m b e d d i n g s i z e + d e e p _ l a y e r [ − 1 ] numeric\_size+field\_size*embedding_size+deep\_layer[-1] numeric_size+field_size∗embeddingsize+deep_layer[−1]
在Cross Net中计算 x l + 1 x_{l+1} xl+1部分,计算 x 0 ∗ x l T x_{0}*x_{l}^{T} x0∗xlT时,需要生成一个矩阵,然后再和 w l w_{l} wl相乘,其实是可以先计算 x l T ∗ w l x_{l}^{T}*w_{l} xlT∗wl的,最后再和 x 0 x_{0} x0相乘即可,因为矩阵相乘是满足结合率的,这样节省了很多内存空间。
A B C = A ( B C ) ABC=A(BC) ABC=A(BC)
三、数据预处理
数据预处理部分和前面推荐算法-DeepFM部分基本上一样的。对于类别型的特征处理是完全一样的,但是对于数值型的特征在这里就不做处理了,只是单独把这一部分数据拿出来,作为一个独立的输入,在对类别型特征完成one-hot之后将数值型特征和embedding部分concat起来就可以了。
首先是数据的读取以及缺失值的处理:
def load_data():
dfTrain = pd.read_csv(config.TRAIN_FILE)
dfTest = pd.read_csv(config.TEST_FILE)
def preprocess(df):
cols = [col for col in df.columns if col not in ['id', 'target']]
df['missing_feat'] = np.sum((df[cols]==-1).values, axis=1)
df["ps_car_13_x_ps_reg_03"] = df["ps_car_13"] * df["ps_reg_03"]
return df
dfTrain = preprocess(dfTrain)
dfTest = preprocess(dfTest)
cols = [col for col in dfTrain.columns if col not in ['id', 'target']]
cols = [col for col in cols if col not in config.IGNORE_COLS]
X_train = dfTrain[cols].values
y_train = dfTrain['target'].values
X_test = dfTest[cols].values
ids_test = dfTest['id'].values
return dfTrain, dfTest, X_train, y_train, X_test, ids_test
接着就是对类别型特征的编码:
class FeatureDictionary(object):
def __init__(self, train_file=None, test_file=None, numeric_cols=[], categorical_cols=[], ignore_cols=[]):
self.train_file = train_file
self.test_file = test_file
self.numeric_cols = numeric_cols
self.categorical_cols = categorical_cols
self.ignore_cols = ignore_cols
self.feature_dict = dict()
self.feature_dimention = 0
self.get_feature_dict()
def get_feature_dict(self):
df = pd.concat([self.train_file, self.test_file], axis=0)
tc = 0
for col in df.columns:
if col in self.ignore_cols or col in self.numeric_cols:
continue
else:
unique_feature_num = df[col].unique()
self.feature_dict[col] = dict(zip(unique_feature_num, range(tc, tc + len(unique_feature_num))))
tc += len(unique_feature_num)
self.feature_dimention = tc
class DataParser(object):
def __init__(self, feature_dict):
self.feature_dict = feature_dict
def parse(self, input_file=None, df=None, has_label=False):
assert not((input_file is None) and (df is None)), 'train_file or df at least one be set'
assert not((input_file is not None) and (df is not None)), 'input_file or df only one can be set'
if df is None:
df = pd.read_csv(input_file)
dfi = df.copy()
if has_label:
y = dfi['target'].values.tolist()
dfi.drop(['id', 'target'], axis=1, inplace=True)
else:
ids = dfi['id'].values.tolist()
dfi.drop(['id'], axis=1, inplace=True)
# print(dfi.columns)
numeric_x_value = dfi[self.feature_dict.numeric_cols].values.tolist() # 找出数值类型特征
dfi.drop(self.feature_dict.numeric_cols, axis=1, inplace=True) # 在数据编码索引中去除数值型特征
dfv = dfi.copy()
for col in dfi.columns:
if col in self.feature_dict.ignore_cols:
dfi.drop(col, axis=1, inplace=True)
dfv.drop(col, axis=1, inplace=True)
continue
else:
dfi[col] = dfi[col].map(self.feature_dict.feature_dict[col])
dfv[col] = 1
categorical_x_index = dfi.values.tolist()
categorical_x_value = dfv.values.tolist()
if has_label:
return categorical_x_index, categorical_x_value, numeric_x_value, y
else:
return categorical_x_index, categorical_x_value, numeric_x_value, ids
上面返回值中有numeric_x,就是数值型特征的取值,这部分特征不需要做任何处理了。
categorical_index和categorical_value和上文生成的部分一样,就是没有数值型特征部分了。
四、模型的构建
模型的构建部分相比于DeepFM部分还是比较简单的。
首先就是权重部分的构建。主要生成embedding部分的权重、Deep模型部分的权重,以及Cross部分的权重。注意Cross部分的权重和偏置shape都是[输入数据维度, 1]这样大小的。
def _init_weights(self):
weights = dict()
tf.set_random_seed(self.random_seed)
# embedding
weights['feature_embedding'] = tf.Variable(tf.truncated_normal(
shape=[self.categorical_feature_size, self.embedding_size], mean=0.0, stddev=0.001), name='feature_embedding') # self.categorical_feature_size就是编码tc的最大值
# deep
weights['deep_layer_0'] = tf.Variable(tf.truncated_normal(shape=[self.total_size, self.deep_layers[0]], mean=0.0,
stddev=0.001, name='deep_layer_0'))
weights['deep_bias_0'] = tf.Variable(tf.truncated_normal(shape=[1, self.deep_layers[0]], mean=0.0, stddev=0.001),
name='deep_bias_0')
for i in range(1, len(self.deep_layers)):
weights['deep_layer_{}'.format(i)] = tf.Variable(
tf.truncated_normal(shape=[self.deep_layers[i-1], self.deep_layers[i]], mean=0.0, stddev=0.001, name='deep_layer_{}'.format(i)))
weights['deep_bias_{}'.format(i)] = tf.Variable(tf.truncated_normal(shape=[1, self.deep_layers[i]], mean=0.0,
stddev=0.001, name='deep_bias_{}'.format(i)))
# cross
for i in range(self.cross_layer_num):
weights['cross_layer_{}'.format(i)] = tf.Variable(tf.truncated_normal(shape=[self.total_size, 1],
mean=0.0, stddev=0.001, name='cross_layer_{}'.format(i)))
weights['cross_bias_{}'.format(i)] = tf.Variable(tf.truncated_normal(shape=[self.total_size, 1],
mean=0.0, stddev=0.001, name='cross_bias_{}'.format(i)))
# concat之后的特征长度
input_size = self.total_size + self.deep_layers[-1]
weights['concat_projection'] = tf.Variable(tf.truncated_normal(shape=[input_size, 1], mean=0.0, stddev=0.001),
name='concat_projection')
weights['concat_bias'] = tf.Variable(tf.truncated_normal(shape=[1, 1]), name='concat_bias')
return weights
最后conca之后的长度为:
input_size = self.total_size + self.deep_layers[-1]
self.total_size = self.field_size * self.embedding_size + self.numeric_feature_size
接下来就是模型的构建。
首先是确定输入的数据,包括类别型特征的索引,取值,以及数值型特征,label,以及dropout的参数。
self.feature_index = tf.placeholder(shape=[None, None], dtype=tf.int32, name='feature_index')
self.feature_value = tf.placeholder(shape=[None, None], dtype=tf.float32, name='feature_value')
self.numeric_value = tf.placeholder(shape=[None, None], dtype=tf.float32, name='numeric_feature')
self.label = tf.placeholder(shape=[None, 1], dtype=tf.float32, name='label')
self.deep_dropout_keep = tf.placeholder(shape=[None], dtype=tf.float32, name='dropout_keep')
self.train_phase = tf.placeholder(tf.bool, name='train_phase')
获得类别型特征的embedding取值:
# embedding
self.embedding = tf.nn.embedding_lookup(self.weights['feature_embedding'], self.feature_index) # batch*field*embedding
feature_value = tf.reshape(self.feature_value, shape=[-1, self.field_size, 1]) # batch*field*1
self.embedding = tf.multiply(self.embedding, feature_value)
在进行深度模型构建之前,要把数值型特征和embedding部分concat起来,
# 数值类型的和embedding部分concat
self.input = tf.concat([self.numeric_value, tf.reshape(self.embedding, shape=[-1, self.field_size*self.embedding_size])], axis=1)
深度模型的构建
# deep部分
self.y_deep = tf.nn.dropout(self.input, self.deep_dropout_keep[0])
for i in range(len(self.deep_layers)):
self.y_deep = tf.add(tf.matmul(self.y_deep, self.weights['deep_layer_{}'.format(i)]),
self.weights['deep_bias_{}'.format(i)])
self.y_deep = self.deep_layer_activation(self.y_deep)
self.y_deep = tf.nn.dropout(self.y_deep, self.deep_dropout_keep[i+1])
Cross模型的构建
self.x0 = tf.reshape(self.input, shape=[-1, self.total_size, 1])
x_l = self.x0
for i in range(self.cross_layer_num):
x_l = tf.tensordot(tf.matmul(self.x0, x_l, transpose_b=True), self.weights['cross_layer_{}'.format(i)], axes=1) + self.weights['cross_bias_{}'.format(i)] + x_l
self.cross_network_out = tf.reshape(x_l, shape=[-1, self.total_size]) # batch*total_size
最后进行分类前把Deep部分和Cross部分的特征concat起来,
# concat
self.concat = tf.concat([self.y_deep, self.cross_network_out], axis=1)
self.out = tf.add(tf.matmul(self.concat, self.weights['concat_projection']), self.weights['concat_bias'])
在上文实现Cross部分,我自己试着按照节省内存的方式写了一下,但是运行的时候会报错,没有找到解决的办法,大家可以自己尝试一下。欢迎交流,我的写法是:
# cross部分
# self.x0 = tf.reshape(self.input, shape=[-1, self.total_size]) # batch * total_size
# x_l = self.x0
#
# for i in range(self.cross_layer_num):
# x_l = tf.multiply(self.x0, tf.matmul(x_l, self.weights['cross_layer_{}'.format(i)])) + \
# self.weights['cross_bias_{}'.format(i)] + x_l # batch*total_size*1
# self.cross_network_out = tf.reshape(x_l, shape=[-1, self.total_size]) # batch*total_size
整篇文章看完就是开头说的那种感觉,很清爽。可能是免去了很多复杂的特征处理组合部分,然后模型也是很清晰明了。所以实现的时候也很简便,总之Deep和Cross部分都是特征组合的方式,而且Cross部分组合的程度更加深。并且看到了在推荐中借鉴了CV中的一些思路。
参考
https://arxiv.org/pdf/1708.05123.pdf
https://www.jianshu.com/p/77719fc252fa
https://blog.csdn.net/qq_18293213/article/details/89707683