大数据技术大会总结 - 6号
今天参加6号的技术大会,包含“大数据架构与系统”、“大数据技术”、“大数据应用”、“大数据研究与发展”、“大数据基准测试”“智能交通与大数据”以及“传统行业如何驾驭大数据”等主题论坛。下面我来介绍一下我的收获,由于主持不是专业出身,各种不按时间开始、结束演讲时间,有的时候去听,已经开始了10分钟了。后面的干货挺的,我主要记录的是360演讲的HBase和Storm相关主题。
1.VMware主管工程师演讲的《HadoopVirtualization Extensions》
他主要谈到了以下几点
a.虚拟化、SDDC和云
这点和之前听的VMWare大会演讲的内容差不多,主要是SDDC概念、虚拟化和云的介绍
b.大数据趋势
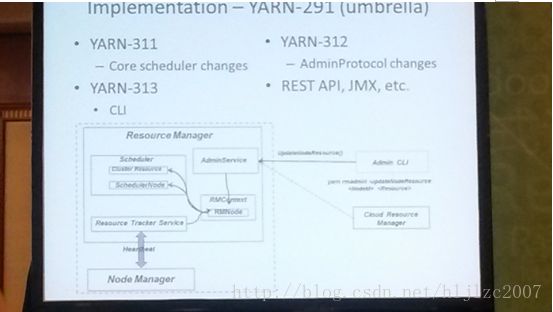
c.Yarn:大数据应用的资源管理器
它是Hadoop2.0的概念,取代了JobTracker和TaskTracker的两层架构模式,而是用ResourceManager, ApplicationMaster和NodeManager的三层架构。具体的后面有一个专题会介绍
d.云中的Yarn
这点主要谈到了云和yarn的关系,它们都具有资源管理的能力,使之整合起来,避免资源浪费,下图是云和Yarn整合的架构图
2.腾讯数据中心资深专家翟艳堂演讲的《腾讯大规模Hadoop集群实践》
该主题主要介绍了腾讯做大集群目的和实践
主要目的是:
数据共享、计算资源共享和减轻运营负担
腾讯在一年内机器由400台提升到4000台,面临人挑战是:
a. 计算层
JobTracker调度效率低,集群扩展性不好
b. 存储层
NameNode没有容灾,在NN重启时,会有丢数据的风险,重启耗时长,不支持灰度重置
基于以上的问题,腾讯的解决方案是
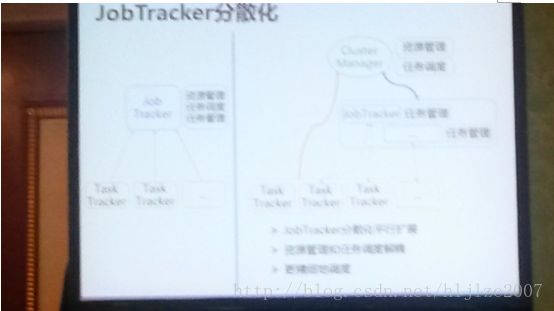
a. JobTracker分散化
这块它做了一个Cluster Manager,它的作用是,资源管理和资源调度,而在其下是JobTracker和TaskTracker,JobTracker的作用只是做任务管理,这样降低了JobTracker的权利,使其高可用
b. NN高可用
主要策略是增加一个备用的NN,当主NN宕机,使用备用的NN
3. Apache Tez Committer BikasSaha演讲了《The Next Generation of Haddop》
会上他主要介绍了Hadoop1.0的缺点和Yarn的功能。
Hadoop1.0的限制:
a. JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
b. JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,只能支持 4000 节点主机的上限。
c. 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
d. 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
e. 源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
f. 从操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应用程序是不是适用新的 Hadoop 版本而浪费大量时间。
Hadoop2.0架构Yarn的思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。新的资源管理器全局管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的 MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager 和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。
下图是Yarn的架构图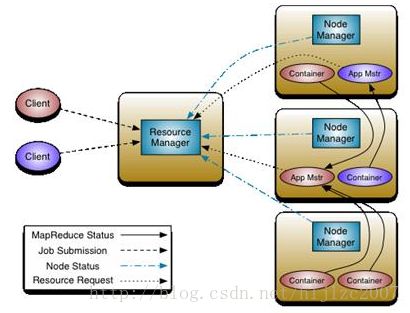
Yarn有作为整个大数据计算的资源调度器的趋势,所有的产品将来的都有可能基于它之上做开发
4.奇虎360高级软件工程师肖康演讲了《利用Storm平台实时网络攻击检测与分析》
360使用Storm遇到的问题与解决方案
a. 问题:整个storm集群不可用(如网络调整、掉电)时,业务受影响
改进:通过多集群管理平台监控storm程序在各个集群的运行情况,并自动处理,在集群中,有一个负载调度模块,当ZK或者客户端发现storm集群故障时,让客户端发送数据到其他集群,同时,自动恢复集群A。具体架构如下图所示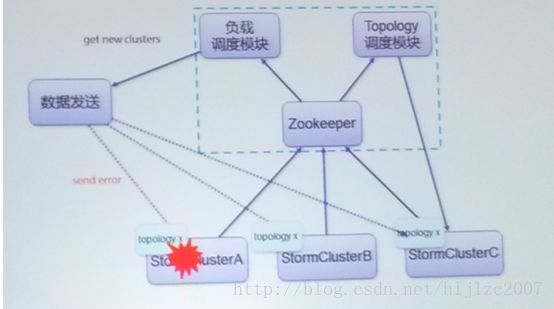
b. 问题:在集群上写非java程序不方便
改进:使用更简单的多语言程序编程接口StramingBolt,这个应该是360自己开发的接口。
c. 问题:上传大的程序jar包,通过nimbus单机分发很慢
改进:把程序的jar和其他依赖的jar包分离,对比md5,只分发md5有变化的文件,这样只是第一次上传慢一些,具体做法如下
d. 问题:查看storm程序日志不方便,需要登录到linux机器才能查看日志。
改进:他们做了一个类似hadoop人webui,可以在web上产看日志信息
同时360还介绍了他们下一步要做的内容:
a. 增加实时metrics方便快速分析问题
b. Storm程序的状态如何保证可靠
c. 满足差异化的worker资源需求通过以上的介绍,我们再使用storm的时候也可以借鉴他们遇到的问题,同时想一些解决方案。
5. 360技术经理赵健博演讲了《奇虎360超大规模HBase集群增强与改进》
360的演讲,干货很多,通过这两个演讲,对HBase和storm在使用过程中的问题有了很详细的了解,当我们使用HBase和storm人时候,可以轻易的避免。
a. 问题:Meta表与user表共用RegionServer,产生了资源竞争,操作user表时影响meta表的性能
改进:专署的MetaServer,有两个专属的Region Server A、B来存放Meta表的内容,这上面不存放user表的住处,当RegionServer A挂了,Hbase访问Region Server B,如果这两个RS都挂掉了,那么Meta表和其他user表使用相同的RS。下图是我画的一个简图。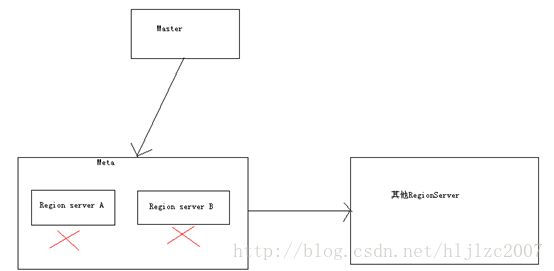
b. 问题:Region多,启动时间长
改进:
region分配是串行的,region多了的话,启动时间会很慢,改进并行的,会加快reion启动时间
单个region分配需扫描RIT队列,确定本次分配的region,提前制定好region分配计划,不让其扫描RITc. 问题:RS打开Region过程 中,一个storefile打开时会出发4次NameNode RPC操作,3次getfilestatus + 1次openfile。
改进:去除重复的NN访问,改成1次openfile
d. 问题:region打开时,操作zk是串行的
改进:ZK改成并行的,多ZK客户端支持
e. 问题:scan改进常规scan,产生大量向后的seek操作,造成读不是顺序的。例如,当纯种1在t1时间读的时候,产生了一个seek,另一个线程从t2读的时候,没有是从seek前一个时间读,那么就会产生向后偏移的seek。下图是我画的一个简图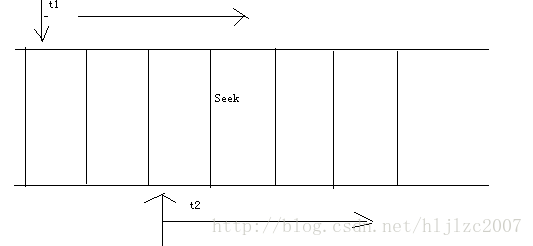
改进:建立一个outscan,绕过HBase client直接从HDFS读数据
e. 问题:outscan MR操作时,一个task对应一个region数据,任务会出现长尾问题
改进:确定表的采样点,划分task,对key索引数据进行采样
f. 问题:原有的compaction文件选择条件过粗,很难避免数据重复与compaction
改进:引入level概念
上边的leven也挺有意思的,具体的做法是问storefile加一个指标:timestamp+level,新文件的level初始值是0,进行一次压缩,level的值就为1,这样系统可以优先压缩当天level为0的文件,从而避免了重复压缩的问题。
g. 问题:HBase client超时时间控制不生效
改进:问题的主要原因是HBase纪录不对,HBaseRPC操作分为,连接服务器、发送请求和获得应答,然而HBase只计算获得应答时间,这明显是不对的,解决方案是将上述三个时间都纪录下来
6.一淘搜索高级软件工程师王峰演讲了《阿里搜索实时流计算技术》
他主要介绍了流计算,阿里内部开发了一套框架叫做istream。
下图是我画的一个架构的简图,中间还有一些细节,我记不太清了,主要流程是,用过通过一淘搜索商品时,搜索引擎从外部电商网站获取数据,放入流处理平台,同事将淘宝的数据从数据库导入到流处理平台,最后将数据发送给搜索引擎,并呈现给用户。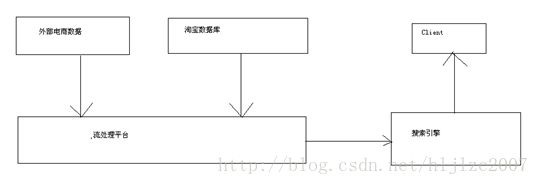
7.总结
以上内容是这两天记下来的内容,内容比较多,有待消化,会上的内容大致分为:
a. 大数据的发展方向
大数据白皮书马上发布
b. 内存计算、流计算火起来了
Spark、Storm等
c. Yarn将成为主流资源管理框架5号的链接: http://blog.csdn.net/hljlzc2007/article/details/17239595