趣味编程:函数式链表的快速排序
前一段时间有朋友问我,以下这段Haskell快速排序的代码,是否可以转化成C#中等价的Lambda表达式实现:
qsort [] = [] qsort (x:xs) = qsort (filter (< x) xs) ++ [x] ++ qsort (filter (>= x) xs)
我当时回答,C#中缺少一些基础的数据结构,因此不行。经过补充之后,就没有任何问题了。后来,我觉得这个问题挺有意思,难度适中,也挺考察“基础编程”能力的,于是就自己写了一个。如果您感兴趣的话,也不妨一试。
这段代码是经典的,常用的体现“函数式编程”省时省力的例子,用短短两行代码实现了一个快速排序的确了不起。您可能不了解Haskell,那么我在这里先解释一下。
首先,这里用到了函数式编程语言中最常用的一种数据结构:不可变的链表。这个数据结构事实上是一个单向链表,并且是“不可变”的。这种数据结构在F#中也有存在,它的结构用大致是这样的:
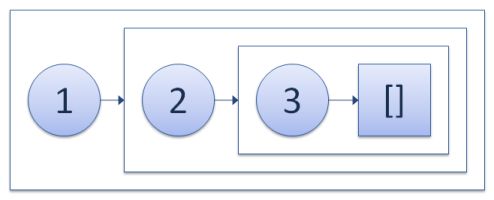
可见,这是一种递归的数据结构。如果我们把这种数据结构叫做是ImmutableList的话,那么每个ImmutableList对象就会包含一个元素的“值”,以及另一个ImmutableList对象(在上图中,每个框就是一个ImmutableList对象)。对于每个ImmutableList对象来说,这个“值”便是它的“头(Head)”,而内部的ImmutableList对象则是它的“尾(Tail)”。如果用C#来表示的话,ImmutableList在C#中的定义可能就是这样的:
public class ImmutableList<T> : IEnumerable<T> { public readonly static ImmutableList<T> Empty = new ImmutableList<T>(default(T)); private ImmutableList(T head, ImmutableList<T> tail) { this.Head = head; this.Tail = tail; } public T Head { get; private set; } public ImmutableList<T> Tail { get; private set; } ... }
您一定意识到了,ImmutableList是一个不可变的链表数据结构,一旦构造之后就再也没有办法修改它的Head与Tail。此外,这里使用Empty来表示一个空链表1。因此,我们使用一个ImmutableList对象便可以代表整个链表,并可以通过Tail来遍历链表上所有的元素:
public class ImmutableList<T> : IEnumerable<T> { ... #region IEnumerable<T> Members public IEnumerator<T> GetEnumerator() { var current = this; while (current != Empty) { yield return current.Head; current = current.Tail; } } #endregion #region IEnumerable Members IEnumerator IEnumerable.GetEnumerator() { return this.GetEnumerator(); } #endregion }
我们再来观察Haskell代码,这段代码分为两行:
qsort [] = [] qsort (x:xs) = ...
这两行都定义了qsort函数,不过参数不同。这种做法在Haskell里被称为“模式匹配”,qsort后面的参数即是“模式”。第一行代码的参数“指明”是一个空链表,因此只有为qsort传入一个空的链表才会执行等号后的逻辑。如果为qsort函数传入的链表不为空,那么它即可被匹配为head和tail两部分,这在Haskell中表示为(head:tail)。因此,在调用第二行的qsort函数时,x会自动绑定为head元素,而xs会自动绑定为tail——结合之前的解释,我们可以知道x是“元素”类型,而xs是另一个链表(可能为空)。
由于C#没有Haskell的模式匹配方式,因此只能在方法内部使用if(或三元运算符?:)进行逻辑控制:
public static class ImmutableListExtensions { public static ImmutableList<T> QuickSort<T>(this ImmutableList<T> list, Func<T, T, int> compare) { if (list == null) throw new ArgumentNullException("list"); if (compare == null) throw new ArgumentNullException("compare"); if (list == ImmutableList<T>.Empty) { ... } else { ... } } }
我们将QuickSort定义为ImmutableList的扩展方法,接受一个比较函数,最终则返回一个排序后的新的链表——因为ImmutableList是不可变的。
然后,我们再回到Haskell的代码,我们可以看出,第一行qsort函数由于接受了一个空链表,因此排序后的结果自然也是一个空链表。而第二行qsort则是一个较为标准的快速排序实现(快速排序的原理大致是:取一个元素作为pivot,先把那些比pivot小的元素放到pivot之前,再把比pivot大的放到pivot之后,然后对pivot的前后两部分分别采取快速排序。递归至最后,则整个链表排序完成):
qsort (x:xs) = qsort (filter (< x) xs) ++ [x] ++ qsort (filter (>= x) xs)
在上面这行代码中,filter高阶函数的作用是对一个链表进行过滤,并返回一个新的链表。它的第一个参数为过滤条件(如(< x)或(>= x),它们都是匿名函数),而第二个参数则是被过滤的目标。(这里即为xs,它是qsort参数的tail)。“++”运算符在Haskell中的含义是连接两个链表,并返回连接的结果。
因此,这行代码的含义为:把小于x的元素使用qsort函数排序,连接上x元素,再连接上大于等于x的元素排序后的结果。于是,最后的结果便是一个排好序的链表。
值得注意的是,由于链表是种不可变的数据结构,因此无论是qsort函数,filter函数,还是++运算符,它们都会返回一个新的链表,而不会对原有链表作任何修改。这点是和我们传统所做的“数组排序”相比有所不同的地方。
现在,您就来尝试实现那个QuickSort方法吧。您可以为ImmutableList补充所需的成员,只要保持ImmutableList的各种特性不变,并实现快速排序便可以了。
注1:原本我使用null来表示一个空链表,但是RednaxelaFX同学指出,如果使用null来表示一个空链表,在实际操作时便会造成一些特殊的情况发生。例如,对于一个null使用foreach会抛出NullReferenceException,这就要求在foreach的时候进行判断,颇为不易。因此,这里构造了一个Empty常量来表示空链表,属于Null Object Pattern的典型应用。