语音识别流程总结
比较简单的语音识别问题是通过语音识别声源的情感、类型、属于谁,属于分类问题,因此则可以转化为分类问题。
下面以常用的CASIA语音数据集识别作为例子,总结一下语音识别的总流程。
数据集文档是这样的:

导入第三方库
#数据读取
import pandas as pd
import numpy
# 特征提取
import librosa
import librosa.display
#绘图
import matplotlib.pyplot as plt
#时间进度
from tqdm import tqdm
from time import time
#模型构建
import sklearn
import tensorflow as tf
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding
from tensorflow.keras.layers import LSTM
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Input, Flatten, Dropout, Activation
from tensorflow.keras.layers import Conv1D, MaxPooling1D, AveragePooling1D
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import ModelCheckpoint
#系统
import os
import datetime
from keras.utils import np_utils
from sklearn.preprocessing import LabelEncoder
#打印时间
def printbar():
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量
#os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" 数据预处理
提取音频特征这一块librosa库,可抽取不同特征,这里就将该问题简化,只提取简单的特征。
读取音频文件
# -*- coding: utf-8 -*-
# 读取文件夹地址
import os
#以递归方式查找所有的音频文件
def listdir(path,list_name):
# list_name=list()
label_list=list()
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
elif os.path.splitext(file_path)[1]=='.wav':
list_name.append(file_path)
list_name=list()
listdir('RawData/CASIA database',list_name)获取音频类型标签
label_list=list()
name_list=["liuchanhg","wangzhe","zhaoquanyin","ZhaoZuoxiang"]
number=range(len(name_list))
d=dict(zip(name_list,number))
for i in range(len(list_name)):
# print(list_name)
name=list_name[i]
if "liuchanhg" in name:
label_list.append(0)
if "wangzhe" in name:
label_list.append(1)
if "zhaoquanyin" in name:
label_list.append(2)
if "ZhaoZuoxiang" in name:
label_list.append(3)音频特征提取
labels = pd.DataFrame(label_list)
t = time()
df = pd.DataFrame(columns=['feature'])
bookmark=0
for index,y in enumerate(tqdm(list_name)):
# print(y)
X, sample_rate = librosa.load(y, res_type='kaiser_fast'
,duration=2.5,sr=22050*2,offset=0.5)
sample_rate = np.array(sample_rate)
mfccs = np.mean(librosa.feature.mfcc(y=X,
sr=sample_rate,
n_mfcc=13),
axis=0)
feature = mfccs
#[float(i) for i in feature]
#feature1=feature[:135]
df.loc[bookmark] = [feature]
bookmark=bookmark+1
print('提取特征所需的时间: {} mins'.format(round((time() - t) / 60, 2)))
#标签和特征组合
newdf = pd.DataFrame(df['feature'].values.tolist())
newdf["label"]=label_list
newdf.head()
#补0
newdf=newdf.fillna(0)
管道构建
from sklearn.model_selection import train_test_split
X1=np.array(newdf.iloc[:, :-1])
X=np.expand_dims(X1, axis=2)
y_tmp=np.array(newdf.iloc[:, -1:])
lb = LabelEncoder()
y=np_utils.to_categorical(lb.fit_transform(y_tmp))
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=22)
BATCH_SIZE=32
ds_train = tf.data.Dataset.from_tensor_slices((X_train,y_train)) \
.shuffle(buffer_size = 1000).batch(BATCH_SIZE) \
.prefetch(tf.data.experimental.AUTOTUNE).cache()
ds_test = tf.data.Dataset.from_tensor_slices((X_test,y_test)) \
.shuffle(buffer_size = 1000).batch(BATCH_SIZE) \
.prefetch(tf.data.experimental.AUTOTUNE).cache()模型搭建
model = Sequential()
model.add(Conv1D(256, 5,padding='same',
input_shape=(216,1)))
model.add(Activation('relu'))
model.add(Conv1D(128, 5,padding='same'))
model.add(Activation('relu'))
model.add(Dropout(0.1))
model.add(MaxPooling1D(pool_size=(8)))
model.add(Conv1D(128, 5,padding='same',))
model.add(Activation('relu'))
#model.add(Conv1D(128, 5,padding='same',))
#model.add(Activation('relu'))
#model.add(Conv1D(128, 5,padding='same',))
#model.add(Activation('relu'))
#model.add(Dropout(0.2))
model.add(Conv1D(128, 5,padding='same',))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(len(d)))
model.add(Activation('softmax'))
model.summary()训练
from tensorflow.keras.optimizers import RMSprop
opt =RMSprop(lr=0.00001, decay=1e-6)
model.compile(loss='categorical_crossentropy', optimizer=opt,metrics=['accuracy'])
import os
import datetime
# optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
# model.compile(optimizer=optimizer,loss=MSPE(name = "MSPE"))
stamp = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
logdir = os.path.join('model', 'autograph', stamp)
## 在 Python3 下建议使用 pathlib 修正各操作系统的路径
# from pathlib import Path
# stamp = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
# logdir = str(Path('./data/autograph/' + stamp))
tb_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
#如果loss在50个epoch后没有提升,学习率减半。
lr_callback = tf.keras.callbacks.ReduceLROnPlateau(monitor="loss",factor = 0.5, patience = 50)
#当accuracy在500个epoch后没有提升,则提前终止训练。
stop_callback = tf.keras.callbacks.EarlyStopping(monitor = "accuracy", patience= 500)
# 在每个训练期之后保存模型
save_dir = os.path.join(os.getcwd(), 'model\\speech\\saved_models')
filepath="model_{epoch:02d}-{val_acc:.2f}.hdf5"
# mc_callback=
# tf.keras.callbacks.ModelCheckpoint(os.path.join(save_dir, filepath)
# , monitor='val_loss',
# verbose=0, save_best_only=False,
# save_weights_only=False,
# mode='auto', period=1)
mc_callback=tf.keras.callbacks.ModelCheckpoint(filepath='/model/speech/weights.hdf5',
monitor='val_loss',
verbose=1, save_best_only=True)
# 把训练轮结果数据流到 csv 文件的回调函数。
csv_callback=tf.keras.callbacks.CSVLogger('./model/speech/training.log')
callbacks_list = [tb_callback,lr_callback,stop_callback,mc_callback,csv_callback]
history = model.fit(ds_train,validation_data=ds_test,epochs=200,callbacks = callbacks_list)结果检查
1.检查误差损失和准确率
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(history, metric):
train_metrics = history.history[metric]
val_metrics = history.history['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
(1)误差损失
plot_metric(history,"loss")
(2)准确率
plot_metric(history,"accuracy")
2.表格表示的运算结果
dfhistory = pd.DataFrame(history.history)
dfhistory.index = range(1,len(dfhistory) + 1)
dfhistory.index.name = 'epoch'
dfhistory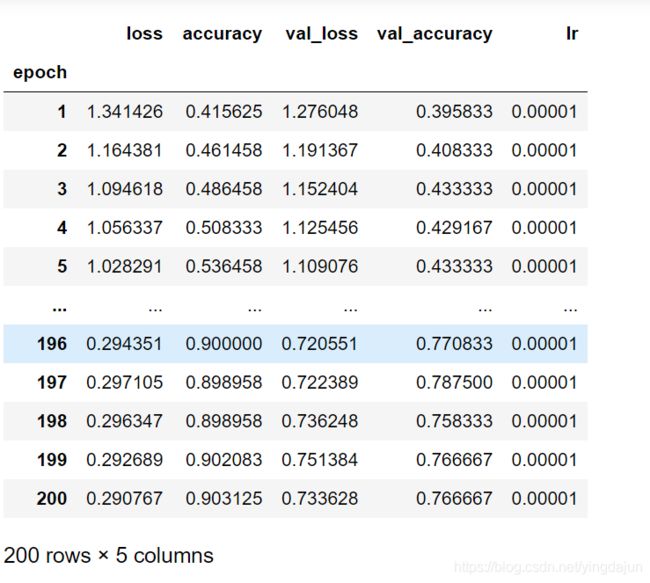
模型保存
#获取模型名称
model_name = 'Emotion_Voice_Detection_Model20201122.h5'
# 获取保存位置,当前位置+saved_models
save_dir = os.path.join(os.getcwd(), 'saved_models')
# Save model and weights
# 如果不存在,那么重新生成一个
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
#模型地址
model_path = os.path.join(save_dir, model_name)
#模型保存
model.save(model_path)
print('Saved trained model at %s ' % model_path)