yolov5分割_基于YOLOv4和YOLOv5网络的目标检测方法介绍
背景简介 目标检测 是人工智能及深度学习中非常重要的一类任务,其目的是在一张图片中自动定位某个物体的位置并标注出该物体的类型,如下图所示:
 本文中,我们介绍最新的深度学习网络结构 YOLOV4 及其衍生出的网络结构 YOLOv5 ,用来更加快速和高效的进行目标检测任务,与此同时,我们将介绍和YOLOv5结构相近的网络YOLOV4,并做进一步对比。实现目标检测的核心要素 完成一个目标检测任务,包含几个核心要素,1.数据的准备;2. 正则化方法;3.整体网络结构;4.BackBone创新,5. Neck结构创新;6. Prediction创新; 核心要素精讲
1 数据的准备 数据的准备是深度学习能够发挥其强大功能最基础也是最重要的过程。网络上公开的数据集往往无法适应现实工程中各种复杂的情况,现实场景中的数据会有更多的不确定性,包括:遮挡、目标过小、角度等等,如何利用现有数据尽可能覆盖更多的场景是我们在训练一个深度学习模型中首要去考虑的问题。这种利用现有数据,覆盖更多场景的方法叫 数据增强 。
本文中,我们介绍最新的深度学习网络结构 YOLOV4 及其衍生出的网络结构 YOLOv5 ,用来更加快速和高效的进行目标检测任务,与此同时,我们将介绍和YOLOv5结构相近的网络YOLOV4,并做进一步对比。实现目标检测的核心要素 完成一个目标检测任务,包含几个核心要素,1.数据的准备;2. 正则化方法;3.整体网络结构;4.BackBone创新,5. Neck结构创新;6. Prediction创新; 核心要素精讲
1 数据的准备 数据的准备是深度学习能够发挥其强大功能最基础也是最重要的过程。网络上公开的数据集往往无法适应现实工程中各种复杂的情况,现实场景中的数据会有更多的不确定性,包括:遮挡、目标过小、角度等等,如何利用现有数据尽可能覆盖更多的场景是我们在训练一个深度学习模型中首要去考虑的问题。这种利用现有数据,覆盖更多场景的方法叫 数据增强 。


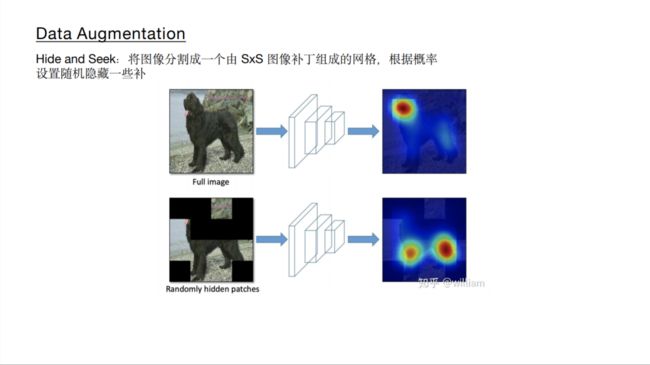
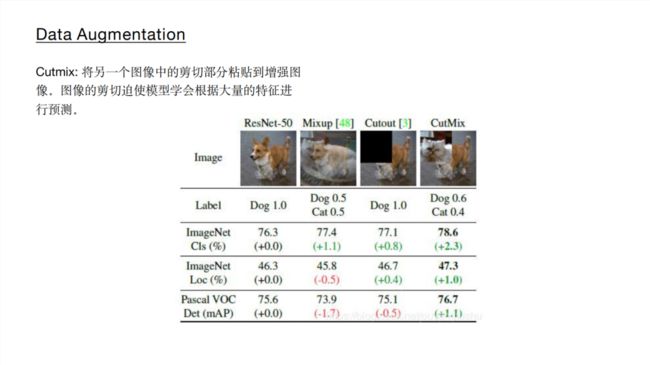
 如上图所示,传统的图像增强方式包括几何畸变以及光照畸变,包括对图片进行 裁剪、旋转、翻转、调色、饱和度、曝光度设置等,除此之外,还有图像遮挡以及多图组合的数据增强方式,如下图:
如上图所示,传统的图像增强方式包括几何畸变以及光照畸变,包括对图片进行 裁剪、旋转、翻转、调色、饱和度、曝光度设置等,除此之外,还有图像遮挡以及多图组合的数据增强方式,如下图:


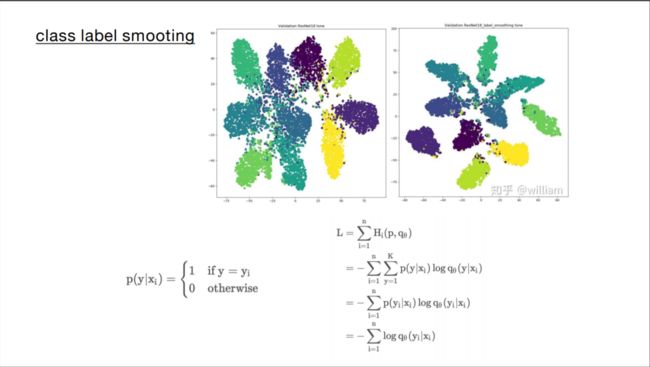
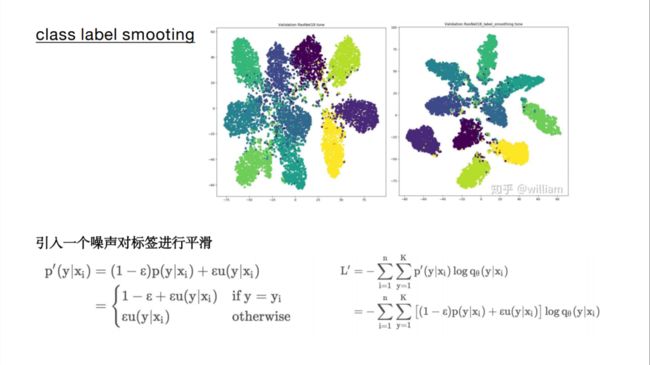
 2 正则化方法 所谓正则化,就是为了减小泛化误差而对机器学习算法进行的修改,这里所说的泛化误差,也就是过拟合和欠拟合,反应了我们通过训练数据得到的深度学习模型,能够适应未知新数据的能力。 在机器学习或者深度学习实验中,我们通常使用大量的正则化技术,比如L1, L2, Dropout等来防止模型发生过拟合,在分类问题中,模型往往可以正确的预测训练样本,但是泛化能力比较弱,下面我们介绍一种分类问题中经常使用的正则化技术——标签平滑。 以交叉熵损失函数为例,传统方式中,我们发现计算的损失只考虑正确标签位置的损失,而不考虑其他标签位置的损失,这就会出现一个问题,即不考虑其他错误标签位置的损失,会使得模型过于关注增大预测正确标签的概率,而不关注减少错误标签的概率,最后导致的结果是模型在自己的训练集上拟合效果非常良好,而在其他的测试集结果表现不好,出现过拟合。 为了改善这种情况,引入一个噪声对标签进行平滑,即样本以epsilon的概率为其他类。如下图,可以看到,标签平滑为最终的激励产生了更紧密的聚类和更大的类别间的分离。
2 正则化方法 所谓正则化,就是为了减小泛化误差而对机器学习算法进行的修改,这里所说的泛化误差,也就是过拟合和欠拟合,反应了我们通过训练数据得到的深度学习模型,能够适应未知新数据的能力。 在机器学习或者深度学习实验中,我们通常使用大量的正则化技术,比如L1, L2, Dropout等来防止模型发生过拟合,在分类问题中,模型往往可以正确的预测训练样本,但是泛化能力比较弱,下面我们介绍一种分类问题中经常使用的正则化技术——标签平滑。 以交叉熵损失函数为例,传统方式中,我们发现计算的损失只考虑正确标签位置的损失,而不考虑其他标签位置的损失,这就会出现一个问题,即不考虑其他错误标签位置的损失,会使得模型过于关注增大预测正确标签的概率,而不关注减少错误标签的概率,最后导致的结果是模型在自己的训练集上拟合效果非常良好,而在其他的测试集结果表现不好,出现过拟合。 为了改善这种情况,引入一个噪声对标签进行平滑,即样本以epsilon的概率为其他类。如下图,可以看到,标签平滑为最终的激励产生了更紧密的聚类和更大的类别间的分离。
 标签平滑前
标签平滑前
 标签平滑后
3 整体网络结构 一个传统的目标检测网络的整体结构大概包括3个主要成分: 1. BackBone主干网络,该主干网络主要负责将输入的图像抽象成特征。 深度学习的发展,离不开特征提取网络的发展。最初的特征提取网络,用来实现分类问题。从LeNet到AlexNet,再到NiN,GoogleNet,ResNet等。 这些基础主干网络的演进带来了性能的提升,性能提升体现在两个方面:1. 对图片特征的表达能力更强。这一点体现在Network in Network网络中,以1*1卷积作为基本单位,增加了网络局部模块的抽象表达能力,实现跨通道特征融合,更加方便的实现通道升降维。同时1*1卷积具有天然的降低计算量的优势。2. 在保证对图片特征的表达能力的同时,还需要尽量减小网络的计算量。当网络过深或者过宽时,一方面,会使得参数过多,训练数据有限的情况下,容易过拟合,另一方面会使得计算复杂度升高,并产生梯度弥散。为了解决这类问题,引入了GooLeNet,其核心思想是构建Inception,将稀疏矩阵聚类为较为密集的子矩阵来提升计算性能。 2. Neck层: 目标检测网络在BackBone和最后的输出层之间往往会插入一些层,这些层被称为neck层,用来更加充分的提取网络特征,为网络的输出做准备。 3. prediction层:该层将网络中提取出的数据特征,最终转化为我们需要的数据格式。
标签平滑后
3 整体网络结构 一个传统的目标检测网络的整体结构大概包括3个主要成分: 1. BackBone主干网络,该主干网络主要负责将输入的图像抽象成特征。 深度学习的发展,离不开特征提取网络的发展。最初的特征提取网络,用来实现分类问题。从LeNet到AlexNet,再到NiN,GoogleNet,ResNet等。 这些基础主干网络的演进带来了性能的提升,性能提升体现在两个方面:1. 对图片特征的表达能力更强。这一点体现在Network in Network网络中,以1*1卷积作为基本单位,增加了网络局部模块的抽象表达能力,实现跨通道特征融合,更加方便的实现通道升降维。同时1*1卷积具有天然的降低计算量的优势。2. 在保证对图片特征的表达能力的同时,还需要尽量减小网络的计算量。当网络过深或者过宽时,一方面,会使得参数过多,训练数据有限的情况下,容易过拟合,另一方面会使得计算复杂度升高,并产生梯度弥散。为了解决这类问题,引入了GooLeNet,其核心思想是构建Inception,将稀疏矩阵聚类为较为密集的子矩阵来提升计算性能。 2. Neck层: 目标检测网络在BackBone和最后的输出层之间往往会插入一些层,这些层被称为neck层,用来更加充分的提取网络特征,为网络的输出做准备。 3. prediction层:该层将网络中提取出的数据特征,最终转化为我们需要的数据格式。
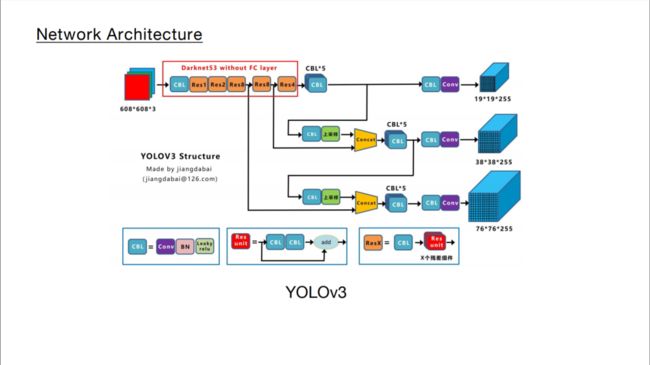
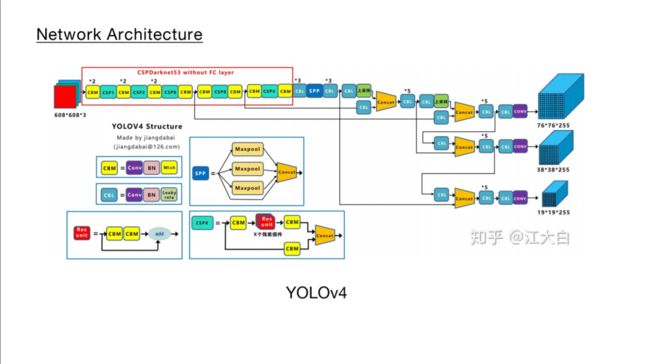 YOLOv4在主干网络上的创新主要在以下 1. BackBone主干网络: 将各种新的方式结合起来,包括: CSPDarknet53、Mish激活函数、Dropblock 2. Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构 3. Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
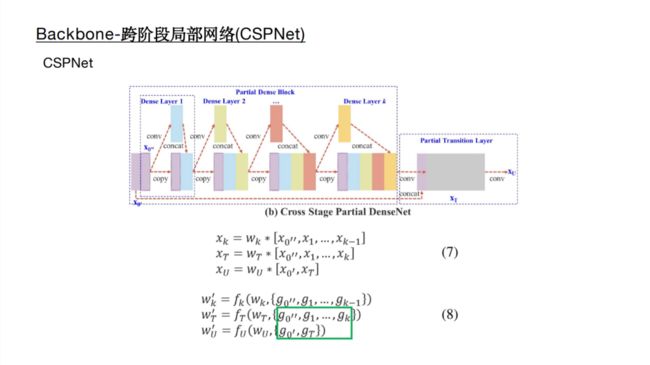
4 BackBone创新 CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块。 每个CSP模块前面的卷积核的大小都是3×3,stride=2,因此可以起到下采样的作用。 因为Backbone有5个CSP模块,输入图像是608×608,所以特征图变化的规律是:608->304->152->76->38->19 经过5次CSP模块后得到19*19大小的特征图。 CSPNet全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中计算量很大的问题。 CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。 因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。 因此Yolov4在主干网络Backbone采用CSPDarknet53网络结构,主要有三个方面的优点: 优点一:增强CNN的学习能力,使得在轻量化的同时保持准确性。 优点二:降低计算瓶颈 优点三:降低内存成本
YOLOv4在主干网络上的创新主要在以下 1. BackBone主干网络: 将各种新的方式结合起来,包括: CSPDarknet53、Mish激活函数、Dropblock 2. Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构 3. Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
4 BackBone创新 CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块。 每个CSP模块前面的卷积核的大小都是3×3,stride=2,因此可以起到下采样的作用。 因为Backbone有5个CSP模块,输入图像是608×608,所以特征图变化的规律是:608->304->152->76->38->19 经过5次CSP模块后得到19*19大小的特征图。 CSPNet全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中计算量很大的问题。 CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。 因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。 因此Yolov4在主干网络Backbone采用CSPDarknet53网络结构,主要有三个方面的优点: 优点一:增强CNN的学习能力,使得在轻量化的同时保持准确性。 优点二:降低计算瓶颈 优点三:降低内存成本
 5 Neck创新
5 Neck创新
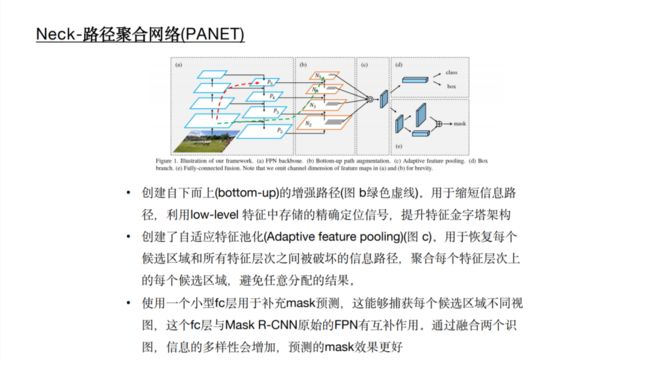
 在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。相当于目标检测网络的颈部,也是非常关键的。 Yolov4的Neck结构主要采用了SPP模块、FPN+PAN的方式。 本文主要讲解FPN+PAN模块。 我们首先回顾之前的YOLOv3结构图,可以看到经过几次下采样,三个紫色箭头指向的地方,输出分别是76×76、38×38、19×19。 以及最后的Prediction中用于预测的三个特征图①19×19×255、②38×38×255、③76×76×255。[注:255表示80类别(1+4+80)×3=255] 而Yolov4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构:前面CSPDarknet53中讲到,每个CSP模块前面的卷积核都是33大小,步长为2,相当于下采样操作。 因此可以看到三个紫色箭头处的特征图是76×76、38×38、19×19。 以及最后Prediction中用于预测的三个特征图:①76×76×255,②38×38×255,③19×19×255。 我们也看下Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。 和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。 其中包含两个PAN结构。 这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。 FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。相当于目标检测网络的颈部,也是非常关键的。 Yolov4的Neck结构主要采用了SPP模块、FPN+PAN的方式。 本文主要讲解FPN+PAN模块。 我们首先回顾之前的YOLOv3结构图,可以看到经过几次下采样,三个紫色箭头指向的地方,输出分别是76×76、38×38、19×19。 以及最后的Prediction中用于预测的三个特征图①19×19×255、②38×38×255、③76×76×255。[注:255表示80类别(1+4+80)×3=255] 而Yolov4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构:前面CSPDarknet53中讲到,每个CSP模块前面的卷积核都是33大小,步长为2,相当于下采样操作。 因此可以看到三个紫色箭头处的特征图是76×76、38×38、19×19。 以及最后Prediction中用于预测的三个特征图:①76×76×255,②38×38×255,③19×19×255。 我们也看下Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。 和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。 其中包含两个PAN结构。 这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。 FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
 6 Prediction创新 目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。 Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020) 我们从最常用的IOU_Loss开始,进行对比拆解分析,看下Yolov4为啥要选择CIOU_Loss。 可以看到IOU的loss其实很简单,主要是交集/并集,但其实也存在两个问题。 问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。 问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。 CIOU_Loss在IOU_Loss的基础上,1. 考虑了边界框不重合时的问题;2、考虑边界框中心点距离的信息;
6 Prediction创新 目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。 Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020) 我们从最常用的IOU_Loss开始,进行对比拆解分析,看下Yolov4为啥要选择CIOU_Loss。 可以看到IOU的loss其实很简单,主要是交集/并集,但其实也存在两个问题。 问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。 问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。 CIOU_Loss在IOU_Loss的基础上,1. 考虑了边界框不重合时的问题;2、考虑边界框中心点距离的信息;
 计算公式如下
计算公式如下

本文中,我们介绍最新的深度学习网络结构 YOLOV4 及其衍生出的网络结构 YOLOv5 ,用来更加快速和高效的进行目标检测任务,与此同时,我们将介绍和YOLOv5结构相近的网络YOLOV4,并做进一步对比。实现目标检测的核心要素 完成一个目标检测任务,包含几个核心要素,1.数据的准备;2. 正则化方法;3.整体网络结构;4.BackBone创新,5. Neck结构创新;6. Prediction创新; 核心要素精讲
1 数据的准备 数据的准备是深度学习能够发挥其强大功能最基础也是最重要的过程。网络上公开的数据集往往无法适应现实工程中各种复杂的情况,现实场景中的数据会有更多的不确定性,包括:遮挡、目标过小、角度等等,如何利用现有数据尽可能覆盖更多的场景是我们在训练一个深度学习模型中首要去考虑的问题。这种利用现有数据,覆盖更多场景的方法叫 数据增强 。
如上图所示,传统的图像增强方式包括几何畸变以及光照畸变,包括对图片进行 裁剪、旋转、翻转、调色、饱和度、曝光度设置等,除此之外,还有图像遮挡以及多图组合的数据增强方式,如下图:
2 正则化方法 所谓正则化,就是为了减小泛化误差而对机器学习算法进行的修改,这里所说的泛化误差,也就是过拟合和欠拟合,反应了我们通过训练数据得到的深度学习模型,能够适应未知新数据的能力。 在机器学习或者深度学习实验中,我们通常使用大量的正则化技术,比如L1, L2, Dropout等来防止模型发生过拟合,在分类问题中,模型往往可以正确的预测训练样本,但是泛化能力比较弱,下面我们介绍一种分类问题中经常使用的正则化技术——标签平滑。 以交叉熵损失函数为例,传统方式中,我们发现计算的损失只考虑正确标签位置的损失,而不考虑其他标签位置的损失,这就会出现一个问题,即不考虑其他错误标签位置的损失,会使得模型过于关注增大预测正确标签的概率,而不关注减少错误标签的概率,最后导致的结果是模型在自己的训练集上拟合效果非常良好,而在其他的测试集结果表现不好,出现过拟合。 为了改善这种情况,引入一个噪声对标签进行平滑,即样本以epsilon的概率为其他类。如下图,可以看到,标签平滑为最终的激励产生了更紧密的聚类和更大的类别间的分离。
标签平滑前
标签平滑后
3 整体网络结构 一个传统的目标检测网络的整体结构大概包括3个主要成分: 1. BackBone主干网络,该主干网络主要负责将输入的图像抽象成特征。 深度学习的发展,离不开特征提取网络的发展。最初的特征提取网络,用来实现分类问题。从LeNet到AlexNet,再到NiN,GoogleNet,ResNet等。 这些基础主干网络的演进带来了性能的提升,性能提升体现在两个方面:1. 对图片特征的表达能力更强。这一点体现在Network in Network网络中,以1*1卷积作为基本单位,增加了网络局部模块的抽象表达能力,实现跨通道特征融合,更加方便的实现通道升降维。同时1*1卷积具有天然的降低计算量的优势。2. 在保证对图片特征的表达能力的同时,还需要尽量减小网络的计算量。当网络过深或者过宽时,一方面,会使得参数过多,训练数据有限的情况下,容易过拟合,另一方面会使得计算复杂度升高,并产生梯度弥散。为了解决这类问题,引入了GooLeNet,其核心思想是构建Inception,将稀疏矩阵聚类为较为密集的子矩阵来提升计算性能。 2. Neck层: 目标检测网络在BackBone和最后的输出层之间往往会插入一些层,这些层被称为neck层,用来更加充分的提取网络特征,为网络的输出做准备。 3. prediction层:该层将网络中提取出的数据特征,最终转化为我们需要的数据格式。
YOLOv4在主干网络上的创新主要在以下 1. BackBone主干网络: 将各种新的方式结合起来,包括: CSPDarknet53、Mish激活函数、Dropblock 2. Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构 3. Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
4 BackBone创新 CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块。 每个CSP模块前面的卷积核的大小都是3×3,stride=2,因此可以起到下采样的作用。 因为Backbone有5个CSP模块,输入图像是608×608,所以特征图变化的规律是:608->304->152->76->38->19 经过5次CSP模块后得到19*19大小的特征图。 CSPNet全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中计算量很大的问题。 CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。 因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。 因此Yolov4在主干网络Backbone采用CSPDarknet53网络结构,主要有三个方面的优点: 优点一:增强CNN的学习能力,使得在轻量化的同时保持准确性。 优点二:降低计算瓶颈 优点三:降低内存成本
5 Neck创新
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。相当于目标检测网络的颈部,也是非常关键的。 Yolov4的Neck结构主要采用了SPP模块、FPN+PAN的方式。 本文主要讲解FPN+PAN模块。 我们首先回顾之前的YOLOv3结构图,可以看到经过几次下采样,三个紫色箭头指向的地方,输出分别是76×76、38×38、19×19。 以及最后的Prediction中用于预测的三个特征图①19×19×255、②38×38×255、③76×76×255。[注:255表示80类别(1+4+80)×3=255] 而Yolov4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构:前面CSPDarknet53中讲到,每个CSP模块前面的卷积核都是33大小,步长为2,相当于下采样操作。 因此可以看到三个紫色箭头处的特征图是76×76、38×38、19×19。 以及最后Prediction中用于预测的三个特征图:①76×76×255,②38×38×255,③19×19×255。 我们也看下Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。 和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。 其中包含两个PAN结构。 这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。 FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
6 Prediction创新 目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。 Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020) 我们从最常用的IOU_Loss开始,进行对比拆解分析,看下Yolov4为啥要选择CIOU_Loss。 可以看到IOU的loss其实很简单,主要是交集/并集,但其实也存在两个问题。 问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。 问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。 CIOU_Loss在IOU_Loss的基础上,1. 考虑了边界框不重合时的问题;2、考虑边界框中心点距离的信息;
计算公式如下
