1.文件系统特性
磁盘分区后还需要进行格式化后操作系统才能使用这个文件系统,为什么要格式化?
因为每个操作系统所设定的文件属性、权限不一样,因此需要将分区槽格式化,以成为操作系统能够利用的"文件系统格式"。
传统技术中,一个分区槽只能被格式化成为一个文件系统,所以我们可以说一个filesystem是一个partition。但由于新技术的发展,例如LVM与软件磁盘阵列(software raid),可以将一个分区槽格式化为多个文件系统,也能将多个分区槽格式化为一个文件系统。所以说,通常我们称"一个可被挂载的数据为一个文件系统而不是一个分区槽"。
文件系统通常将操作系统的文件权限(rwx)和文件属性(拥有者、群组、时间参数等)分别存放在不同的区块,权限与属性放到inode中,至于实际数据放到data block中。另外,还有一个超级区块:
superblock:记录整个文件系统的整体信息,包括inode与block的总量、使用量、剩余量等。
inode:记录文件的权限与相关属性,一个文件占用一个inode,同时记录此文件的数据所在的block号码。
block:实际记录文件的内容,若文件太大时,会占用多个block。
由于每个inode与block都有编号,而每个文件都会占用一个inode,inode内会放置有block号码,也就能够读文件的实际数据。如下图所示:
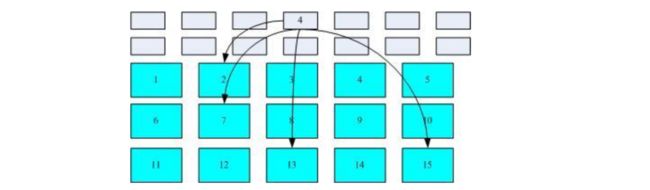
假设一个文件的属性与权限数据放到了inode4号,而这个inode记录了文件数据的实际放置点是2、7、13、15,操作系统就能够据此来排列磁盘的阅读顺序。这种数据存取方法我们称为"索引式文件系统"。
还有惯用的是"随身碟",文件系统一般为FAT格式:
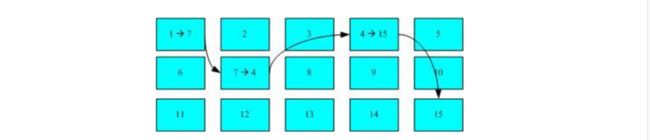
这个文件系统没有办法一口气知道4个block的号码,它得将每个block读出,才知道下一个block在哪。如果同一个文件数据写入的block分散的厉害,磁盘头就需要转好几圈才能完整读取到文件的内容。
Linux的EXT2文件系统(inode)
文件系统一开始就将inode与block规划好了,除非重新格式化,否则inode与block固定后就不再变动。但如果文件系统有几百GB时,所有的inode与block放置在一起时很不明智的。
所以,EXT2文件系统在格式化的时候基本上时区分为多个区块群组,每个群组都有自己独立的inode/block/superblock系统。如下图所示:
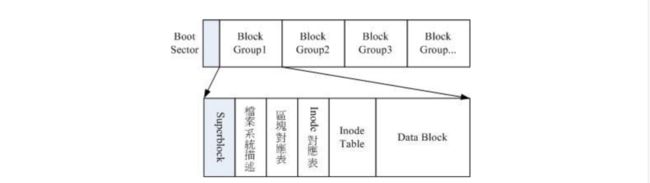
- data block
用来放置文件内容数据,在EXT2文件系统中所支持的block大小有1K、2K、4K三种。

除了大小限制还有什么限制?基本限制如下:
block的大小与数量在格式化完就不能在改变了
每个block内最多只能存放一个文件的数据
如果文件大于block的大小,则一个文件会占用多个block数量
如果文件小于block的大小,则该block的剩余容量就不能在被使用
- inode table
inode记录文件的属性以及该文件实际数据放置在哪个block内。inode记录的文件数据至少有以下这些:
该文件的存取模式(read/write/excute)
该文件的拥有者与群组(owner/group)
该文件的容量
该文件建立或状态改变的事件(ctime)
最近一次的读取时间(atime)
最近修改的时间(mtime)
定义文件特性的旗标(flag),如SetUID...
该文件真正内容的指向(pointer)
inode的特点:
数量与大小也是在格式化时就已经固定了
每个inode大小均固定为128bytes(新的ext4)
每个文件都只占用一个inode
文件系统能建立都文件数量与inode的数量有关
系统读取文件时需要先找到inode,并分析inode记录的权限与用户是否符合,符合才能开始实际读取block的内容
我们来分析以下EXT2的inode/block与文件大小的关系。inode要记录的数据非常多,但大小只有128bytes,而inode记录一个block号码要花掉4byte,假设我有一个文件有400MB且每个block为4K时,那么至少要10w个block号码记录。inode哪有这么多可记录的信息?为此我们系统将inode记录与block号码的区域定义为12个直接,1个间接,1个双间接,1个三间接记录区,结构如下所示:
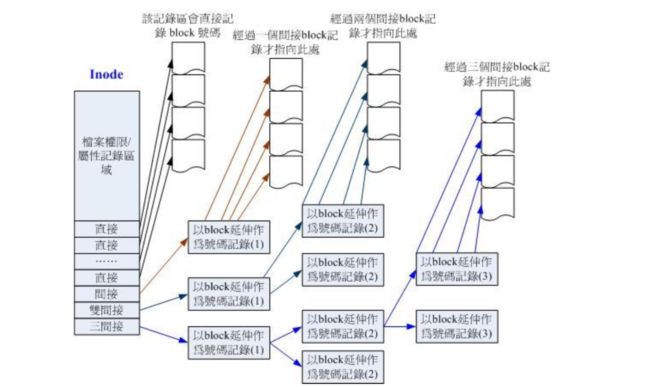
假设我们以1K block大小来说明:
12个直接指向:12*1K=12K
直接指向就是直接存放的block的数据,总共可记录12笔
间接:256*1K=256K
拿到额外一个block专门存取block号码,每个block号码记录花去4bytes,1K的大小能记录256个block。
双间接:2562561K=256^2K
第一层block会指定256个第二层,每个第二层可以指定256个block号码
三间接:256256256*1K=256^3K
第一层block会指定256个第二层,每个第二层指定256个第三层,每个第三层指定256个block号码
- superblock
记录整个文件系统相关信息的地方,主要记录的信息有:
block与inode的总量
未使用与已使用的inode/block数量
block与inode的大小(block为1,2,4K;inode为128或256bytes)
filesystem的挂载时间、最近一次写入数据的时间、最近一次检验磁盘的时间等文件系统的相关信息
一个valid bit数值,若此文件系统已被挂载,则valid bit为0,没被挂载就为1。
一般来说,supderblock大小为1024bytes
我们说一个文件系统应该只有一个superblock,但是后续的block group可能还会有superblock,这是为了防止superblock死掉,进行的备份。
- filesystem Description(文件系统描述说明)
这个区段描述每个block group的开始与结束的block号码,以及说明每个区段(superblock、bitmap、inodemap、data block)分别介于哪一个block号码之间。
block bitmap(区块对照表)
在新增文件的时候总会用到block,那怎么知道哪个block是空的呢,这就需要block bitmap的辅助了,能够快速找到可使用的空间。inode bitmap(inode对照表)
这个和block bitmap相似的功能。记录inode使用与未使用的号码。
2.文件系统与目录树
2.1 目录
在Linux下的文件系统建立一个目录时,文件系统会给该目录分配一个inode与至少一个block。其中,inode记录该目录的相关权限与属性,并可以记录分配到了哪块block号码;block记录了这个目录下的文件名与文件名占用的inode号码数据。
可以使用命令"ls -il"选项查看某个目录下的文件所占用的inode号码
[jumpserver@xxx tomcat-analysis]$ ls -il
total 108
239384 drwxr-xr-x. 2 jumpserver root 4096 Apr 2 14:12 bin
268848599 drwxr-xr-x. 3 jumpserver root 4096 Apr 3 10:41 conf
538441458 drwxr-xr-x. 2 jumpserver root 4096 Apr 2 14:12 lib
268848635 -rw-r--r--. 1 jumpserver root 56846 Sep 14 2016 LICENSE
537335010 drwxr-xr-x. 3 jumpserver root 4096 Apr 10 15:08 logs
268848636 -rw-r--r--. 1 jumpserver root 1239 Sep 14 2016 NOTICE
268848637 -rw-r--r--. 1 jumpserver root 8965 Sep 14 2016 RELEASE-NOTES
268848638 -rw-r--r--. 1 jumpserver root 16195 Sep 14 2016 RUNNING.txt
807646942 drwxr-xr-x. 2 jumpserver root 29 Apr 2 14:12 temp
239395 drwxr-xr-x. 9 jumpserver root 4096 Apr 4 10:26 webapps
268848634 drwxr-xr-x. 3 jumpserver root 21 Apr 3 10:31 work
2.2 文件
在Linux下的EXT2下建立一个一般文件时,EXT2会分配一个inode和相对于该文件大小的block数量给该文件。
例如:假设block为4KB,我们要建立一个100KB的文件,那么Linux将分配一个inode和25个block来存储该文件。注意:inode只有12个直接指向,因此还要多一个block来作为区块号码的记录。
2.3 目录树读取
inode本身并不记录文件名,文件名的记录在目录的block中。所以我们在第五章文件与目录的权限说明中,才会提到"新增、删除、更名文件名与目录的w权限有关"。
目录树是由根目录开始读起的,系统通过挂载的信息可以找到挂载点的inode号码,此时就能够得到根目录的inode内容,根据该inode读取根目录的block内的文件名数据,再一层一层向下读到正确的档名。例如:我们想读取"/etc/passwd"这个文件,系统由以下步骤:
[jumpserver@xxx tomcat-analysis]$ ll -di / /etc/ /etc/passwd
128 dr-xr-xr-x. 18 root root 4096 Aug 10 2018 /
16777345 drwxr-xr-x. 91 root root 8192 Mar 30 03:45 /etc/
18615857 -rw-r--r--. 1 root root 1613 Mar 15 15:53 /etc/passwd
[jumpserver@host-172-16-13-249 tomcat-analysis]$
-
- / 的inode:通过挂载点的信息找到inode号码为128的根目录inode,且inode规范的权限让我们可以读取该block的内容(由r、x)
-
- / 的block:经过上面步骤取得block号码,并找到该内容有/etc目录的inode号码(16777345)
-
- etc/ 的inode:读取16777345号inode得知root具有r、x的权限,因此可以读取etc/的block
4.etc/ 的block:经过上个步骤取得block号码,并找到该内容有passwd文件的inode号码(18615857)
5.passwd的inode:读取18615857号inode得知root有r的权限,因此可以读取passwd的block内容
6.passwd的block:最后将该block内容的数据读出来
2.4 磁盘读取功能
当你的文件系统很大时,例如100GB,由于磁盘上面的数据总是来来去去,所以正规文件系统的文件通常无法连续卸载一起(block号码不会连续),而是填入式的将数据填入未被使用的block中。这样就会有所谓的"文件数据离散"问题。
它导致的结果就是读取效率很低,因为磁盘读取头要在正规文件系统中反反复复的频繁读取。不过,你可以将整个文件系统的数据全部复制出来,将该系统重新格式化,再将数据复制回去可以解决这个问题。
EXT2/EXT3/EXT4 文件的存取与日志式文件系统的功能
假设我们想要新增一个文件,它的行为是怎样的呢?
1.先确定用户对想要新增文件的目录是否有w与x的权限;
2.根据inode bitmap找到没有使用的inode号码,并将新文件的权限/属性写入;
3.根据block bitmap找到没有使用的block号码,并将实际数据写入block中,且更新的inode的block指向;
4.将刚刚写入的inode与block数据同步更新inode bitmap与block bitmap,并更新superblock的内容。
数据不一致的状态:正常情况下,新增可以顺利完成。如果在数据写入inode table及data block后突然停电等突发状况,最后一个superblock的同步更新步骤没有做完,此时就会发生metadata的内容与实际数据存放区产生不一致。
早期的EXT2中,如果发生这个问题,系统在重启的时候,就会把superblock记录的valid bit(是否有挂载)与filesystem state(是否clean)等状态来判断是否需要进行数据一致性检查。这样的检查真的很费时,metadata区域与实际数据存放区进行比对,要搜索整个filesystem!
日志式文件系统
为了避免上面的问题发生,后来想到一种方式:如果在我们的filesystem中规划出一个区块,该区块专门记录写入活修订文件的步骤:
1.预备:当系统要写入一个文件时,会先在日志记录区块中记录某个文件准备要写入的信息。
2.实际写入:开始写入文件的权限与数据;开始更新metadata的数据。
3.结束:完成数据与metadata的更新后,在日志记录区块中完成该文件的记录。
EXT3/EXT4是EXT2的升级版本,并可向下兼容。我们可以用"dumpe2fs"查看输出的讯息,可以发现superblock里面含有journal处理日志区块的记录。
3.Linux文件系统的运作
3.1 大文件的运作
所有的数据要加载到内存后CPU才能对该数据进行处理。如果你编辑一个大文件,编辑过程中又频繁的要系统来写入到磁盘中,由于磁盘写入的速度比内存慢很多,因此会常常等待磁盘的写入/读取效率!
为了解决整个问题,Linux使用的方式是异步处理(asynchronously):
当系统加载一个文件到内存后,如果该文件没有被动过,则在内存区段的文件数据会被设定为干净(clean)的。但如果内存中但文件数据被改过,此时该内存的数据会被设定为脏的(Dirty),此时所有的动作都还在内存中执行,并没有写入磁盘中。系统会不定时的将内存中设定为"Dirty"的数据写回磁盘。其实也就是缓冲的功能。
3.2 挂载点的意义
每个filesystem都有独立的inode/block/superblock等信息,这个文件系统要能够链接到目录树才能被我们使用。将文件系统与目录树结合的动作我们成为"挂载"。
注意:挂载点一定是目录,该目录为进入该文件系统的入口。
举例来说,CentOS7.x应该有3个挂载点,分别是"/","/boot","/home"。如果我们观察这3个目录的inode号码,可以发现:

由于XFS文件系统最顶层的目录inode一般为128,因此可以发现"/","/boot","/home"为3个不同的fielsystem。(因为每行的文件属性不相同,并且3个目录挂载点也不同)。
4.XFS文件系统
CentOS7开始,预设的文件系统由EXT4变成了XFS文件系统。这是由于哪些原因?
4.1 EXT家族目前的问题:支持度最广,但格式化很慢!
EXT文件系统对于文件格式化处理,采用但是预先规划出所有的inode/block/metadata等数据。早期磁盘容量不大这个还没什么问题,但现在磁盘容量越来越大。光是系统要预先分配inode与block就要消耗很长很长时间了。
4.2 XFS文件系统配置
XFS在文件系统资料分布上,主要有3个部分:数据区(data section)、文件系统活动登录区(log section)、实时运作区(realtime section)。
- 1.数据区(data section)
像EXT家族一样,包括inode/datablock/superblock等,都放在这个区块。这个数据去与EXT的block group类似,分为多个储存区群组(allocation groups)来分别放置文件系统所需要的数据。
每个存储区又包含:整个文件系统的superblock;剩余空间的管理机制;inode的分配与追踪。此外,inode与block都是系统需要用到时,才动态配置产生,所以格式化很快!。
- 2.文件系统活动登录区(log section)
主要来记录文件系统的变化。如果文件系统因为某些故障损毁时,系统会拿这个登录区来进行检验,查看系统挂掉前,文件系统正在做哪些动作。
- 3.实时运作区(realtime section)
有文件要被建立时,XFS会在这个区段里找一个或多个extent区块,将文件放置在这个区块内,等分配完成后,再写入data section的inode与block。extent区块的大小要在格式化的时候就先指定,最小4K最大1GB。
4.3 XFS文件系统的描述数据观察
有么有像EXT家族的dumpe2fs一样可以观察superblock内容的相关指令?我们可以用xfs_info。
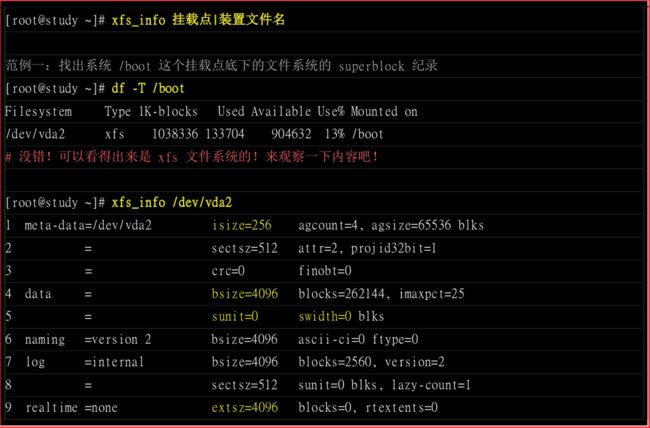
第1行里面的isize指inode的容量,每个有256bytes大小。agcount是储存区群组的个数,一共是4个。agsize是指每个储存区具有65536个block。配合第4行的block设定为4K,因此整个文件系统的容量是4655364K这么大。
第2行sectsz指逻辑扇区(sector)的容量设定为512bytes。
第4行bsize指block的容量,每个block为4K,共有262144个block在这个文件系统内。
第5行第sunit与swidth与磁盘阵列第stripe相关性较高。下面说明。
第7行internal指这个登录区的位置在文件系统内,而不是外部设备的意思。占用4K*2560个block,总共月10MB的容量。
第9行的realtime区域,里面的extent容量为4K。目前没有使用。