前言

我建议新手都从Python3开始学习,可以不去学习Python2了,毕竟以后一定会被Python3代替,当然,也有一些库它现在只兼容Python2,那我们就再考虑了,我的Python版本是Python3.5.2
推荐一个基础教程,廖雪峰老师的Python入门教程
安装Scrapy
先要确定自己的Python版本 配置好环境变量,在cmd中输入python命令
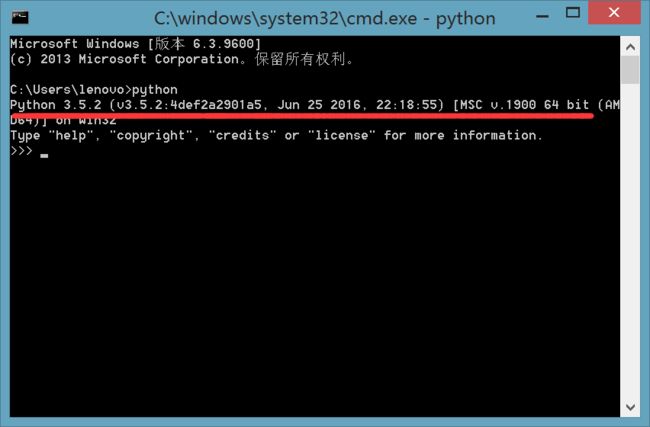
同时也需要配置好pip命令

Scrapy框架是基于twisted的异步架构的,所以我们安装Twisted
下载对应版本的.whl文件先安装twisted库,当然你也需要选择适合自己的版本下载
下载地址: http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

安装twisted
打开命令提示符窗口,输入命令:pip install (下载好的twisted模块的whl文件路径)
安装scrapy
twisted库安装成功后,就可以安装scrapy了,在命令提示符窗口直接输入命令:
pip install scrapy回车
安装关联模块pypiwin32,在命令提示符窗口直接输入命令: pip install pypiwin32 回车
Scrapy测试,生成一个Scrapy框架
创建项目
运行命令:
scrapy startproject p1(your_project_name)
自动创建目录的结果:

文件说明:
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
scrapy终端常用命令
可用scrapy命令
在终端中输入以下命令,查看scrapy有哪些命令语法
scrapy -h
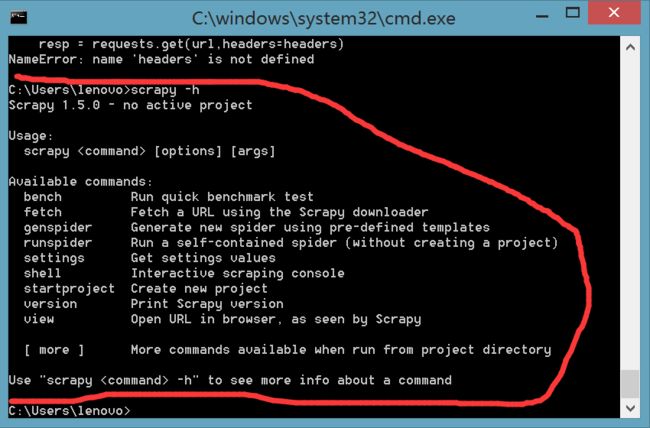
scrapy的命令有两种分类-全局命令与项目命令
比如我们在命令行直接输入scrapy startproject myproject这个命令,实际上是在全局环境中使用的。
而当我们运行爬虫时候输入scrapy crawl myspider时,实际上是在项目环境内运行的。
#全局变量
startproject
runspider
shell
fetch
#项目命令
crawl
parse
genspider
创建项目
全局命令。使用scrapy第一步是在命令行中,创建爬虫项目。
语法: scrapy startproject
在 当前目录下创建一个名为 projectname 的Scrapy项目。
scrapy startproject myproject
目录结构如下
scrapy.cfg
projectname/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
myspider.py
创建好项目后,将当前工作目录切换到项目目录中。使用
cd myproject
之后就可以使用scrapy的项目命令操作scrapy项目了。
生成spider
项目命令。创建spider。一般创建的spider名字是跟域名一样的,比如www.baidu.com,我们穿件的爬虫命令
scrapy genspider baidu baidu.com
一般规律如下
scrapy genspider spidername domain.com
爬取
项目命令。 语法:scrapy crawl
fetch
全局命令。语法:scrapy fetch
使用本语句下载指定的url,并将获取到的内容返回为scrapy中的response对象。
scrapy fetch https://i.meituan.com
shell
全局命令。语法:scrapy shell [url]
Scrapy shell是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码,用来测试提取数据的代码。该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。 免去了每次修改后运行spider的麻烦。
scrapy shell运行后,就会有以下对象,可以进行方便的调试。
scrapy shell https://www.baidu.com/
parse
项目命令。语法: scrapy parse
获取给定的URL并使用相应的spider分析处理。如果您提供 --callback 选项,则使用spider的该方法处理,否则使用 parse。
--spider=SPIDER: 跳过自动检测spider并强制使用特定的spider
--a NAME=VALUE: 设置spider的参数(可能被重复)
--callback or -c: spider中用于解析返回(response)的回调函数
--pipelines: 在pipeline中处理item
runspider
全局命令语法:scrapy runspider
在未创建项目的情况下,运行一个编写在python脚本中的spider。