Scala学习笔记-方便查找使用 为Spark学习打基础
Scala学习
- 注意
- 伊始
-
- 为什么是Scala
- 网课
- 环境
-
- 电脑环境安装
-
- 关于版本的声明
- 我的环境和版本
- IDEA插件安装
- IDEA关联Scala源码
- 基础部分1
-
- 文档注释和生成
- 字符串的三种输出
- 变量和常量
- 数据类型
-
- 数据类型体系图
-
- 小结
- 具体数据类型
-
- 整形
- 浮点型
- 字符型(char)
- Unit,Null,Nothing
- 自动数据类型转换
- 高级隐式转换和隐式函数
- 强制类型转换
-
- 细节说明
- 值类型和String类型的转换
-
- 基本数据类型转String
- String转基本数据类型
- 标识符
-
- 标识符概念
- 标识符的命名规则
- 运算符
-
- /
- %
- 自增自减
- 关系运算符
- 逻辑运算符
- 赋值运算符
- 位运算符
- 运算符优先级
- 基础部分2
-
- 读取控制台输入
- 流程控制
-
- 顺序
- 分支
-
- 单分支
- 双分支
- 多分支
- 分支嵌套
- Scala中没有switch
- 注意
- 循环
-
- `for`
-
- reverse的作用
- for循环返回值
- for循环守卫
- while循环
- do-while循环
- 循环中断
-
- break功能的解决方案
- continue功能的解决方案
- 函数
-
- 函数的基本语法
-
- 可变参数
-
- 格式
- 注意
- 参数默认值
- 带名参数
- 无参数
-
- 情况一
- 情况二
- 过程
- 匿名函数
-
- 匿名函数的简化原则
- 惰性函数
- 异常处理
-
- 注意
- 函数高阶用法小结
-
- 函数可以作为值传递
- 函数可以作为参数传递
- 函数可以作为函数返回值
- 函数闭包
- 函数柯里化
- 递归与尾递归
-
- 尾递归注解
- 注意
- 控制抽象
-
- 传值调用
- 传名调用
-
- 传名调用注意事项
- 高阶函数练习汇总见文末
- 面向对象
-
- 类与对象
- Scala与Java
- Scala中面向对象
-
- 类的注意事项
- 对象的注意事项
- 类的创建流程
- 访问权限
- 构造器
-
- 主构造器
- 辅助构造器
- 例子
- 构造器参数
-
- 实际演示
- Bean属性
- 注意
- 抽象属性和抽象方法
-
- 基本语法
- 继承和重写
- 匿名子类
- 单例对象(伴生对象)
- 单例模式
-
- 饿汉式单例模式
- 懒汉式单例模式
- Trait 特质 (理解不深 日后补充)
-
- trait和抽象类的选择
- 对象
-
- 枚举类对象
- 应用类对象
- 集合
-
- 数组
-
- 不可变数组
-
- 定义方式一:
- 定义方式二:
- 操作
- 不可变数组的增加
- 可变数组
-
- 可变数组添加元素
- 可变数组删除元素
- 可变与不可变相互转化
- 多维数组
-
- 创建
- 遍历
- 列表List
-
- 不可变
-
- 创建、遍历
- 添加元素:
- 拼接List
- 可变
-
- 创建
- 增加新元素
- 合并、拼接list
- 修改元素
- 删除
- 集合Set
-
- 不可变集合
- 创建
- 添加新元素
- 合并Set
- 删除元素
- 可变Set
- 创建
- 添加元素
- 删除元素
- 合并
- Map
-
- 不可变Map
-
- 创建
- 遍历元素
- 对map取key或value
- 可变Map
-
- 创建
- 添加和修改元素
- 删除元素
- 合并
- 元组tuple
-
- 声明、创建
- 访问元组各个元素
- 遍历
- 队列
-
- 可变队列
- 不可变队列
- 并行集合
- 集合函数
-
- 常用函数
- 衍生集合操作
-
- 针对单一集合
- 针对两个集合
-
- 并集
- 交集
- 差集
- 拉链
- 滑动窗口
- 简单函数
-
- 求和
- 求乘积
- 求最大最小值
- 排序
- 集合计算高级函数
-
- 过滤 `.filter()`
- 转化/映射(map)
- 扁平化 `.flatten`
- 扁平化+映射
- 分组group
-
- 分组练习1 奇偶分组
- 分组练习2 单词首字母分组
- 规约
-
- 求和练习
- 减法
- 折叠 fold
- 练习:合并map
- 案例:WordsCount 简单版
- 模式匹配
-
- 简单演示
- 模式守卫
-
- 案例:求数字绝对值
- 匹配常量
- 匹配类型
- 匹配集合-数组
- 匹配集合-列表
- 匹配元组
- 在其他位置进行模式匹配
-
- 变量声明时匹配
- 在循环中匹配
- 模式匹配-匹配对象
-
- 样例类
- 泛型
-
- 逆变与协变
-
- 代码演示-协变:
- 代码演示-逆变:
- 泛型限定
-
- 泛型上下限
- 上下文限定
- 包
-
- 包的作用
- 包的基本使用
-
- 注意
- 管理风格
-
- Java包管理风格
- 嵌套的包管理风格
- 导包
- 查看包的内容
- 打包
- 作用域原则:
- 包对象
- 课后练习
注意
本文适合有C、C++、Java等编程语言基础的人查看。
伊始
为什么是Scala
毕业设计所逼,我课题是《基于spark的实时音乐推荐系统》,而Spark是用Scala开发的,使用Scala必然最合适。虽然Spark提供了Java、Python等的API,但貌似效果不如Scala。
且Scala自身较为独特,和Java还有很深的渊源,毕竟可以说Scala和Java8.0都出自一人之手。
网课
自己找了个网课,开干。
环境
电脑环境安装
xxx
关于版本的声明
注意,不同的Scala版本,可能会有不同的运行结果。选择版本时,要兼顾Spark等其它框架、软件的要求
我的环境和版本
后文所有内容都将基于以下版本展开,最新情况请参考官方文档
- java version “1.8.0_201”
- Scala code runner version 2.11.8
- IntelliJ IDEA 2018.2.4 (Ultimate Edition)
构建 #IU-182.4505.22, 建于 September 18, 2018
Subscription is active until January 1, 2100
JRE: 1.8.0_152-release-1248-b8 amd64
JVM: OpenJDK 64-Bit Server VM JetBrains s.r.o - Windows 10 10.0

补充:于2021年4月2日将IDEA切换为IntelliJ IDEA 2020.3.3 (Ultimate Edition)
补充:于2021年4月5日将Scala由2.11.8切换为2.13.5
IDEA插件安装
若在idea内无法下载,需要前往idea官网下载后再安装,注意插件版本问题!!! 插件需要根据idea版本选择
IDEA关联Scala源码
xxxx
基础部分1
文档注释和生成
注释
对于方法(函数)的注释,写好方法后,在其上一行键入/**并按回车,其注释模板会自动补全:
/**
* @example
* 输入10和20 输出30
* @param number1 数字1
* @param number2 数字2
* @return 两数之和
*/
def plus(number1: Int, number2: Int): Int = {
return number1 + number2;
}
文档生成
在powershell中(保证路径无误):
scaladoc.bat -d d:\scala\mydoc\ TestScala.scala

字符串的三种输出
var name = "A_Nan"
var age = 20
// 三种输出方式
println("1. hello" + name + age)
printf("2. hello name: %s\tage: %d\n", name, age)
println(s"3. hello name: $name\tage: ${age + 20}")
结果:

变量和常量
var生成变量
var age: Int = 10
var age2 = 20 //可省略数据类型 自动推导
var num: Double = 10.9
var name: String = "hello"
var isPass: Boolean = true
var score: Float = 11.8f
val生成常量,不可再次修改,该种生成方法效率更高(因为在底层不用考虑线程安全问题)
Scala设计者推荐使用val
例如:一般生成对象后就不再重新指定对象,因此生成对象时可使用val
val Dog = new Dog //生成val对象 提高效率
Dog.name = "hello" //对象的属性可正常修改
Dog.name = "123"
class Dog {
var name: String = ""
}
数据类型
- Scala与Java有着相同的数据类型,但Scala中数据类型都是对象,即:Scala中没有Java的原生类型
- Scala数据类型分为值类型(AnyVal)和引用类型(AnyRef),这两者都是对象
这样就有一个好处——变量有大量方法可以使用:

注:无参方法可省略括号
var age: Int = 10
age.toString()
age.toString//无参方法可省略括号
数据类型体系图

小结
- 在Scala中有一个根类型Any,它是所有类的父类
- 在Scala中一切皆为对象,分两大类——值类型和引用类型,均为Any子类
- Null类型时Scala的特别类型,只有一个null值,它是bottom class,是所有引用类型的子类
- Nothing类型也是bottom class,它是所有类的子类,在开发中可将Nothing类型的值返回给任意变量和函数,在抛出异常中使用很多
- 在Scala中存在隐式转换(implicit conversion):低精度的值向高精度的值自动转换
具体数据类型

整形
var i = 10 //Int
var j = 10l //Long
var k = 10L //Long
注意:

这里报错的直接原因不是数字大小超过了变量number的范围,而是因为默认情况下数字均是int类型,错误发生在赋值号之后,将数字改为Long即可:

Long最大值和最小值:
println("MinLong:" + Long.MinValue)
println("MaxLong: " + Long.MaxValue)

处理大数据会有专用类型,Long的范围远远不够!
浮点型
-
默认为Double,声明为Float要在数字后加“f”或“F”。

-
浮点型常量表示形式(两种):
十进制形式:5.12, 512.0f,. 512(必须要有小数点)
科学计数法:5.12e2, 5.12E-2
字符型(char)
-
字符常量是用单引号括起来的单个字符。
例如:var ch = 'a' -
也允许使用转义字符
例如:var ch = '\n' //表示换行符 -
可以直接给char变量赋予整数,会按照Unicode编码保存
-
char可以进行运算
var ch: Char = 'a' var number: Int = 10 + ch + 'b' println("number: " + number)结果:

以下为错误赋值:

Unit,Null,Nothing

自动数据类型转换

高级隐式转换和隐式函数
Scala提供了非常强大的隐式转换机制(隐式函数,隐式类等),请看高级部分
强制类型转换
将容量大的数据类型转为容量小的数据类型,但可能会造成精度降低或溢出。
var num: Int = 2.7.toInt //使用强转方法
细节说明

值类型和String类型的转换
基本数据类型转String
var str: String = 123 + ""
String转基本数据类型
使用String的.toXxx方法
var str: String = "1234"
var num: Int = str.toInt
var num_double: Double = str.toDouble
注意:
转换时确保能够将String转为有效数据,例如:
- 不能将
"hello"转为整数 - 不能将
"12.2"转为Int
标识符
标识符概念
- Scala对各种变量、方法、函数等命名时使用的字符序列称为标识符
- 凡是自己可以起名字的地方都叫标识符
标识符的命名规则
- 首字符为字母,后续字符任意字母和数字,美元符号,可后接下划线_
- 数字不可以开头。
- 首字符为操作符(比如+ - * /),后续字符也需跟操作符,至少一个(反编译)
- 操作符(比如+ - * /)不能在标识符中间和最后.
- 用反引号``包括的任意字符串,即使是关键字(39个)也可以,如
var `true` = 123
运算符
/
var num1: Int = 10 / 3
var num2: Double = 10 / 3
var num3: Double = 10.0 / 3
println("num1: " + num1)
println("num2: " + num2)
println("num3: " + num3)
println("num3: " + num3.formatted("%.2f"))

%

自增自减
var num = 1
num += 1 //代替++
num -= 1 //代替--
关系运算符
生成的值均为Boolean(true或false)
规则同C、Java,此处不做介绍
逻辑运算符
- 与
&& - 或
|| - 非
!
赋值运算符


位运算符

运算符优先级

基础部分2
读取控制台输入
package com.test.scala01
import scala.io.StdIn
object Test2 {
def main(args: Array[String]): Unit = {
val name: String = StdIn.readLine()
println(name)
}
}
流程控制
顺序
整体类似于Java,从前到后、从上到下执行
变量是向前引用,但对象、方法无限制
分支
单分支
val num = 12
if(num > 10) {
print("yes")
}
双分支
val num = 122
if (num > 1000) {
print("yes")
} else {
print("no")
}
多分支
val num = 122
if (num == 100) {
print("100")
} else if (num == 111) {
print("111")
} else {
print("no")
}
分支嵌套
同Java、C等语言,此处不做介绍,推荐嵌套不要超过三层
Scala中没有switch
在Scala中用模式匹配来处理,该方法需要知识较多,后文进行介绍
注意
在if else中:
-
若大括号内只有一行代码,那么大括号可以省略
-
Scala中任何表达式都有返回值,包括
if else表达式,if else的返回内容取决于满足条件的代码体的最后一行内容,以下为特殊情况:val num = if (12 == 100) { 200 } print(num)
这里小括号()表示返回值为Unit,即空 -
Scala中没有三元运算符,因为可以用
if else代替:val num = if (12 > 100) 12 else 100
循环
for
第一种:
for (i <- 1 to 5) {
//[1, 5]
println(i) //一共循环五次
}
结果:

第二种:
for (i <- 1 until 5) {
//[1,5)
println(i) //循环4次
}
在for循环中引入变量:
可以在原括号内的后面加上分号;后再创建新的变量,让编程更灵活
for (i <- 1 until 5; j = 6 - i) {
//分号不可省略
println(j)
}
运行结果:

注意,在Scala的for循环中,分号;的意义和C、Java等语言中for循环的分号不一样了,以至于Scala的for循环嵌套可以这么写:
for (i <- 1 to 3; j <- 1 until 3) {
println("i=" + i + " j=" + j)
}
运行结果如下:

这种写法相当于:
for (i <- 1 to 3) {
for (j <- 1 until 3) {
println("i=" + i + " j=" + j)
}
}
在实际的使用中,还是这种原始的方法更为灵活。说实话,把两个循环条件写一个括号里没求用,花里胡哨反而影响代码阅读。。。。。。
注意1:
-
{}和()对于for来说都可以for (i <- 1 to 5) { //两个for循环功能相同 print(i) } for { i <- 1 to 5} { //两个for循环功能相同 print(i) } -
不成文规定(非强制性):
for推导式仅包含单一表达式用小括号,多个表达式用大括号 -
当使用大括号
{}换行写表达式时,分号可省略for { i <- 1 to 10 j = 2 * i } { println(j) }
注意2:
要想理解1 to 10,不妨先想想以下代码可否执行?结果是怎样?
print(1 to 10)
运行结果:

有意思吧,Range()这个东西用处多多,下面还会提到。
注意3:
for循环步长的控制
- 使用
Range()
for (i <- Range(1, 10, 2)) {
//范围[1, 10),步长为2
println(i)
}

- 使用循环守卫(见下文)
reverse的作用
reverse查一下单词意思就明白了
reverse适用于List:
val list = List(1, 2, 3)
println(list)//1, 2, 3
println(list.reverse)//3, 2, 1
因此,如果要反着循环,可以通过如下实现:
-
使用
reversefor (i <- 0 to 10 reverse) { println(i) }当然,前文提到了
0 to 10就是Range(0, 11),因此也可以这么写:for (i <- (0 to 10).reverse) { println(i) }或:
for (i <- Range(0, 11).reverse) { println(i) } -
当然,通过减法运算也可实现一样的效果
for (i <- 0 to 10) { println(10 - i) }
for循环返回值
如同if语句一样,for循环语句也有返回值,但要借助yield:
val num = for (i <- 1 to 3) yield i;
print(num)
结果如下:

这就表明,yield返回的对象是Vector,也就是会把每次循环得到的变量i放入Vector中,循环结束后将Vector赋值给变量num。同时,在yield后面可以是一个代码块,这样就会有更强的灵活性:
val num = for (i <- 1 to 3) yield {
if (i * i > 2 * i) {
i * i
} else {
2 * i
}
};
print(num)
结果如下:

这种特性,正体现了Scala中的一个重要特点,就是Scala擅长将一个集合中的每一个元素都进行处理后,返回给新的集合。
for循环守卫
循环守卫也叫循环保护式、条件判断式、守卫。保护式为true则进入循环体,为false则跳过,类似C语言中的continue
例如:
for (i <- 1 until 5 if i != 2) {
println(i)
}
该代码一共会循环四次,其中i等于2时跳过
故也可以通过此方法来实现循环步长的控制:
for (i <- 1 to 10 if i % 2 != 0) {
println(i)
}

while循环
同C、Java等语言相似:
- 循环条件是返回一个布尔值的表达式
- while循环是先判断再执行语句
- 与
if语句不同,while语句本身没有值,即整个while语句的结果是Unit类型的,即() - 因为没有返回值,所以当要用该语句来计算并返回结果时,就需要使用外部变量,即在
while循环的外部声明变量,所以会造成循环内部对外部的变量造成了影响,而这是与Scala的设计理念相违背的,因此更推荐使用for循环
例子如下:
var i = 0
while (i < 10) {
i += 1
print("hello:" + i)
}
do-while循环
同样不推荐使用,理由同上
例子:
var i = 0
do {
i += 1
println(i + " hello")
} while (i < 5)
循环中断
在Scala中是没有break和continue这两个关键字的,所以无法像C、Java等语言一样通过它们来实现循环控制。这么做是为了更好地适应函数化编程。
break功能的解决方案
在Scala中,虽然没有break关键字,但是存在break函数,即break()。注意,关键字和函数是不一样的。
在使用break()时,会在循环中抛出一个异常:
package com.test.scala01
import util.control.Breaks._
object Test2 {
def main(args: Array[String]): Unit = {
while (true) {
break();//此处抛出异常
}
}
}

其实,大家看到这应该就有些眉目了,Scala是通过异常处理这种方式来实现和break关键字一样的功能。所以,既然抛出了异常,就要异常处理。
当然,这里需要使用breakable()来接收异常,这是一个高阶函数,高阶函数可以接受代码段作为参数:
package com.test.scala01
import util.control.Breaks._
object Test2 {
def main(args: Array[String]): Unit = {
breakable(
while (true) {
break();
}
)
}
}
这样异常就被捕获了:

不过在breakable()的小括号中写好几行代码怪怪的,所以也可以用大括号:
package com.test.scala01
import util.control.Breaks._
object Test2 {
def main(args: Array[String]): Unit = {
breakable {
while (true) {
break();
}
}
}
}
查看breakable()源码就能看出这种方式实现的原理:

图中的op就是自己写的代码块,在程序运行时,直接把这些括号内的代码都作为参数传至try语句的后面,通过try-catch来实现循环中断。
注意:不是所有的函数的小括号都可以换为大括号!!
continue功能的解决方案
- 循环守卫(
while循环没有守卫。。。) - 在循环体内使用
if语句加以解决
函数
注意:函数式编程和函数是两个概念
函数的基本语法
def 函数名 ([参数:参数类型],······)[[:返回值类型]=] {
语句······
return 返回值
}
- 函数声明关键字为
def(definition) [参数名:参数类型],···表示函数的输入(也就是参数列表)可以有也可以没有。如果有,多个参数使用逗号间隔- 函数返回值可有可无
- 若函数体只有一行,则大括号可省略
返回值有多种情况:
- 明确给出返回值
:返回值类型= - 返回值类型不确定,使用类型推导完成
= - 没有返回值,return不生效
空 - 如果没有
return,默认以执行到最后一行的结果作为返回值 - 若声明返回值为
Unit,那么不论return什么东西,返回值一定为Unit,即空,也就是()
如果写了return,那么就必须要指明返回类型,而不能只写=让编译器推导类型
错误写法(浅灰色内容是IDEA的自动类型显示,不是代码部分):

正确的写法:

可变参数
顾名思义,可变参数是指向函数中传入的参数的数量是可以变化的,底层是通过集合(类似于Java中的数组)来进行接收参数的。
格式
用*表示此参数为可变参数
def main(args: Array[String]): Unit = {
printString("aaa", "bbb", "ccc")
}
def printString(s: String*): Unit = {
println(s)
}
运行结果:

注意
- 一个函数中的可变参数最多只能有一个
- 可变参数必须置于最后
思考为何如此?
参数默认值
def printString(name: String = "nan"): Unit = {
println(name)
}
使用时可以直接调用无需赋值:printString()
带名参数
在调用函数时带有参数的名称
例如:
函数主体
def printString(name: String = "nan", age: Int): Unit = {
println(name + age)
}
调用:
printString(age = 12)
这种方式可以指定向某参数传值而无需考虑参数的先后顺序。
实际使用中,函数可能参数众多,且均带有默认值,此时若只修改某一两个参数,便可通过带名参数的方法实现。
无参数
情况一
声明时有(),但参数列表为空:
def he(): Unit = {
println(111)
}
调用时括号可以省略:
def main(args: Array[String]): Unit = {
he()
he
}
情况二
声明时无():
def he: Unit = {
println(111)
}
那么在调用时()必须省略:
def main(args: Array[String]): Unit = {
he
}
过程
过程(procedure)也是函数,但其返回类型为Unit,此时等号可以省略。
def he(num: Int) {
print(num)
}
匿名函数
如果只关心函数的逻辑处理过程,而不关心函数名称,那么对于函数名称的声明也可以省略!当然,形式上要发生一些变化。
普通函数:
def printName(name: String): Unit = {
println(name)
}
匿名函数:
(name: String) => {
println(name)
}
通常而言,匿名函数会结合高阶函数使用。高阶函数可以接受函数作为参数,如下所示:
object myClass {
def main(args: Array[String]): Unit = {
demo((name: String) => {
println(name)
})
}
//高阶函数 接受函数作为参数
//func为接受的函数名 String为接受的函数的参数
//第一个Unit为接受的函数的返回值类型
def demo(func: String => Unit): Unit = {
func("nan")
}
}
匿名函数的简化原则
- 参数类型可省略,由形参自动推导
例:
object myClass {
def main(args: Array[String]): Unit = {
//name类型省略
demo((name) => {
println(name)
})
}
def demo(func: String => Unit): Unit = {
func("nan")
}
}
- 在参数类型省略后,有且只有一个参数时,
()可以省略,若无参数或参数数量大于1则不能省略
例:
object myClass {
def main(args: Array[String]): Unit = {
//name类型省略
//只有一个参数 圆括号可省略
demo(name => {
println(name)
})
}
def demo(func: String => Unit): Unit = {
func("nan")
}
}
- 匿名函数体若只有一行则大括号可以省略
例:
object myClass {
def main(args: Array[String]): Unit = {
//name类型省略
//只有一个参数 圆括号可省略
//函数体只有一行 大括号可以省略
demo(name => println(name))
}
def demo(func: String => Unit): Unit = {
func("nan")
}
}
- 若参数只出现一次,则参数省略且后面的参数可以用
_代替
例:若把println()传入到demo()中,可如下:
object myClass {
def main(args: Array[String]): Unit = {
//参数只出现一次 则参数省略 后面使用时用下划线代替
demo(println(_))
}
def demo(func: String => Unit): Unit = {
func("nan")
}
}
- 若可以推断出,传入的内容是函数体而非调用语句,下划线和
()可以一同省略
例:
object myClass {
def main(args: Array[String]): Unit = {
//参数只出现一次 则参数省略 后面使用时用下划线代替
//传入的内容是函数体而非调用语句 下划线和()可以一同省略
demo(println)
}
def demo(func: String => Unit): Unit = {
func("nan")
}
}
匿名函数与高阶函数的练习
惰性函数
当函数返回值被声明为lazy时,函数的执行将被推迟,直到我们首次对此取值,该函数才会执行。这种函数被称为惰性函数,在Java中与之相对应的是通过某些框架实现的懒加载模式。
普通函数:
package com.test.scala01
object Test2 {
def plus(num1: Int, num2: Int): Int = {
println("this is plus")
return num1 + num2
}
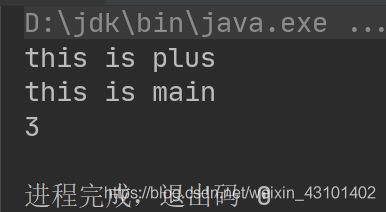
def main(args: Array[String]): Unit = {
val result = plus(1, 2)
println("this is main")
println(result)
}
}
普通函数执行结果:
惰性函数例子:
package com.test.scala01
object Test2 {
def plus(num1: Int, num2: Int): Int = {
println("this is plus")
return num1 + num2
}
def main(args: Array[String]): Unit = {
lazy val result = plus(1, 2) //lazy!!!!!
println("this is main")
println(result)
}
}
执行结果:

从中可以发现,两者之间的区别仅在于是否在变量前加上lazy
从执行结果也可以看出,惰性函数会尽可能的拖延函数中代码的执行,只有在确实需要函数返回值的情况下,才会运行函数。
注意:
lazy不能修饰var类型的变量(这不难理解,一个可变的东西没法实现懒加载)- 对于函数的调用,加了
lazy会推迟函数的执行;对于变量的声明也会推迟其数值的赋予
例:lazy val i = 10
我称其为懒汉他娘给懒汉开门——懒到家了
异常处理
例如这里有一个除数为零的异常:
package com.test.scala01
object Test2 {
def divided(num1: Int, num2: Int): Int = {
println("this is plus")
return num1 / num2
}
def main(args: Array[String]): Unit = {
val result = divided(1, 0)//除数为零
println("this is main")
}
}
那么"this is main"是不会被输出的,因为在这之前就遇到异常终止了:

众所周知,加入异常处理便能完成,也就是try-catch,但Scala这门语言非常神奇,即使没有catch也可编译,只不过会有警告而且异常仍然存在:

正确的异常处理:
package com.test.scala01
object Test2 {
def divided(num1: Int, num2: Int): Int = {
println("this is plus")
return num1 / num2
}
def main(args: Array[String]): Unit = {
try {
val result = divided(1, 0)
}
catch {
case ex: ArithmeticException => {
println("除数为零")
}
case ex: Exception => println("所有异常的接收")
}
finally {
println("it's ok")
}
println("this is main")
}
}
结果如下:

注意
-
Scala中没有checked(编译期)异常,只有运行时异常 -
用
throw关键字,可抛出异常对象。所有异常都是Throwable的子类型。throw表达式是有类型的,就是Nothing,因为Nothing是所有类型的子类型,所以throw表达式可以用在需要类型的地方def test(): Nothing = { throw new Exception("no") } -
try中一旦有异常就立刻会转到catch中进行处理,对于try中未执行的代码则彻底不会执行 -
在
Scala中,借用模式匹配思想来做异常匹配(模式匹配前文有提到过哦~),因此是通过一系列case语句来处理的。=>后的可以是单条代码也可以大括号包裹的多行代码(代码块) -
和其它语言类似,在
catch中,是按照次序捕捉异常的。因此编写代码时,越具体的异常要越靠前,越普遍的异常要越靠后。尽管反着写不会报错,但这是非常不好的编程风格。 -
finally可有可无,若有则必会执行其内部的代码,一般用于清理对象 -
Scala提供了throws关键词来声明异常。可使用方法定义声明异常,它向调用者函数提供了此方法可能引发异常的信息,有助于调用函数处理并将该代码包含在异常处理中。例:/** * * @param num1 * @param num2 * @throws java.lang.ArithmeticException * @return */ @throws(classOf[ArithmeticException]) def divided(num1: Int, num2: Int): Int = { println("this is plus") return num1 / num2 } //注释模板生成参考前文->文档注释和生成
注意:在Scala 2.13.4版本中,注释发生了变化:

故实际情况请参考自己版本对应的手册
函数高阶用法小结
函数可以作为值传递
例(带参函数):
object myClass {
def main(args: Array[String]): Unit = {
val f1 = func _
val f2: Int => Int = func
println(f1)
println(f1(1))
println(f2)
println(f2(2))
}
def func(n: Int): Int = {
n + 1
}
}
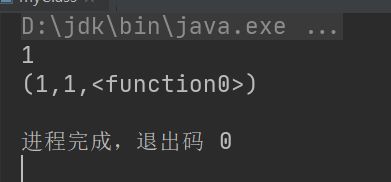
例:(无参函数)
object myClass {
def main(args: Array[String]): Unit = {
println(func2())
val a = func2
val b = func2()
val c = func2 _
println(a, b, c)
}
def func2(): Int = {
1
}
}
注意结果
函数可以作为参数传递
object myClass {
def main(args: Array[String]): Unit = {
println(dualFunc(plus, 1, 2))
println(dualFunc((a, b) => a + b, 1, 2))
println(dualFunc(_ + _, 1, 2))
}
def dualFunc(func: (Int, Int) => Int, a: Int, b: Int): Int = {
func(a, b)
}
def plus(a: Int, b: Int): Int = {
a + b
}
}
函数可以作为函数返回值
这需要用到函数嵌套
object myClass {
def main(args: Array[String]): Unit = {
val result = func()
println(result(1, 2))
//以上可简写为
println(func()(1, 2))
}
def func() = {
def plus(num1: Int, num2: Int): Int = {
num1 + num2
}
plus _
}
//func()也可以写为
def func2():(Int, Int) => Int = {
def plus(num1: Int, num2: Int): Int = {
num1 + num2
}
plus
}
}
函数闭包
闭包是函数式编程的标配
闭包:如果一个函数访问了外部变量的值,那么这个函数和他所处的环境,称为闭包
通常的局部变量在方法执行结束时就不存在了,但是如果被包括进了闭包,那么在闭包存在的期间,局部变量也会一直存在。
也就是说,函数体受外部环境所影响,一段封闭的代码块将外部环境(函数外部的上下文环境)包括进来,就是闭包。
函数柯里化
柯里化:把一个参数列表的多个参数,变成多个参数列表
def plus2(a: Int)(b: Int) = {
a + b
}
递归与尾递归
尾递归是对递归的优化,避免出现栈溢出的情况

在IDEA中,普通递归和尾递归的标志不同
尾递归注解
为了确保尾递归正确,可以使用注解。如果尾递归书写有误,在加上注解后就会报错

注意
尾递归的实现依赖于编译器,所以 即使可以在Java中写成尾递归的形式,但仍然是普通的递归
控制抽象
传值调用
把计算后的值传递过去,也就是通常所看到的这些函数
例:
def main(args: Array[String]): Unit = {
println(plus(1, 2))
}
def plus(a: Int, b: Int) = {
a + b
}
传名调用
把代码传递过去
例:
def main(args: Array[String]): Unit = {
printTime( {
print("hello ")
2
})
}
def printTime(n: => Int): Unit = {
println("Time: " + n)
}

运行结果:

传名调用注意事项
传入的参数不仅包括代码,以下均可:
- 单行语句:尽管看起来和值调用没有区别,但它仍然是传名调用
例:
def main(args: Array[String]): Unit = {
printTime(2)
}
def printTime(n: => Int): Unit = {
println("Time: " + n)
}
- 函数:没错,函数也可以作为
代码块传入,不过要和函数高阶用法中的把函数作为参数传递区分开来,二者实现过程、功能均不相同
例:
def main(args: Array[String]): Unit = {
printTime(function0())
}
def function0(): Int = {
println("this is function0")
0
}
def printTime(n: => Int): Unit = {
println("Time: " + n)
println("Time: " + n)
}
执行结果如下:
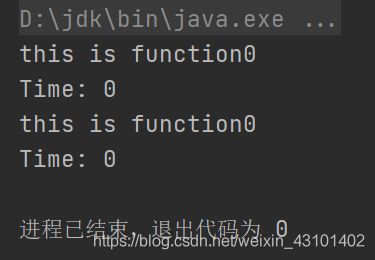
在传名调用中,被传入的函数执行几次,取决于被引用了几次
练习:用自定义函数实现while循环功能
高阶函数练习汇总见文末
高阶函数练习四:用自定义函数实现while循环功能
面向对象
类与对象
| 类 | 对象 |
|---|---|
| 抽象的,代表一类事物 | 具体的,代表确切的某一个体 |
| 类是对象的模板 | 对象是类的一个个体 |
Scala与Java
- Java是面向对象的编程语言,但其还包含着非面向对象的部分,例如静态方法、基本类型等
- Scala来自于Java,所以天生就是面向对象,而且是纯粹的面向对象语言,即一切皆为对象
Scala中面向对象
例子:
def main(args: Array[String]): Unit = {
val cat = new Cat //能用val就用val 可提高速度
cat.name = "hello"
cat.age = 100
cat.kind = "bosi"
cat.weight = 26
}
class Cat {
var name: String = "" //必须要赋初值
var kind: String = _ //下划线表示自动对
var age: Int = 0 //不同类型变量赋初值
var weight: Int = _
}
类的注意事项
-
对于属性必须要赋予初始值,否则报错
-
下划线
_表示让编译器根据属性类型自动赋予初值类型 _对应的值Byte,Short,Int,Long0Float,Double0.0String,引用类型nullBooleanfalse -
在声明
var name: String时,底层会生成对应的private name,也就是说,属性是private,同时也会生成public name()和public name_$eq(),类似于Java中的getter()和setter(),实现属性的取值、赋值功能
即:Scala中类似于cat.name = "hello"这样对属性的取值、赋值操作在底层都借助于方法来实现 -
默认下,
class修饰符缺省的情况下,生成的class为public,但不要画蛇添足,在class前加上public会报错!!!!!!

-
借助于反编译工具查看生成的字节码,就能发现底层所有的实现逻辑
属性的高级部分和构造器相关,请查看构造器(构造方法/函数)的相关章节
对象的注意事项
-
对象的创建时能用
val就用val,可提高速度 -
当类型和后面new的对象类型有继承关系(多态)时,必须写对象类型,否则可省略
package com.test.scalaDemo2 object myClass { def main(args: Array[String]): Unit = { val dog = new Dog //自动类型推断将会把类型设定为Dog val animal: Animal = new Dog //把子类对象交给父类对象的应用 //这种就需要明确指出类型 } } class Dog extends Animal { } class Animal { } -
val dog2 = dog这两个对象在底层是同一个,都指向了同一块内存。例如:修改dog的属性,dog2的属性也会发生一样的变化
类的创建流程
- 加载类的信息(属性信息、方法信息)
- 在内存中(堆)开辟空间
- 使用父类的构造器(主、辅助)进行初始化
- 使用自己的主构造器对属性初始化
- 使用自己的辅助构造器对属性进行初始化
- 将开辟的地址赋值给对象变量(常量)
访问权限

构造器
在Scala中,共有主构造器和辅助构造器两种,两种构造器参数不能相同,否则会报错

主构造器
class A {
var address: String = _
println("this is A")
}
在这个代码中,var address: String = _和println("this is A")都属于主构造器中的一部分。
由于主构造器没有参数,所以括号省略掉了,原本的形式是这样的:
class A() {
var address: String = _
println("this is A")
}
而默认情况下主构造器都是public,所以要想变为private,需要如下处理:
class A private() {
var address: String = _
println("this is A")
}
其实看到这里,大家应该有稍有理解了,A是类名,而()是属于主构造器的,所以要想让主构造器成为private,就要在()前添加,而不是在A的前面。
辅助构造器
辅助构造器名称均为this,多个辅助构造器通过不同参数列表进行区分,在底层中就是通过重载来实现的。
例子
理解一下代码的执行顺序:
package com.test.scalaDemo2
object myClass {
def main(args: Array[String]): Unit = {
val b = new B()
println(b.toString)
}
}
class A() {
var address: String = _
println("this is A")
}
/**
* B类继承自A
* @param inName
*/
class B private(inName: String) extends A {
var name: String = inName
var age: Int = _
println("this is B, and name=" + this.name)
/**
* 辅助构造器
*/
def this() {
this("ZhouXingXing") //必须要调用主构造器 并保证参数类型匹配
// this.age = age
println("this()")
this.name = "ANan"
}
/**
* 重载toString
* @return 返回两个属性的字符串
*/
override def toString: String = {
"toString\n\tname: " + name + "\n\t" + "age: " + age
}
}
运行结果:

构造器参数
- 在类的主构造器中,形参未使用任何修饰符修饰,那么这个参数是局部的。
- 如果参数使用
val关键字声明,那么Scala会将参数作为类的私有的、只读的属性使用。 - 如果参数用
var声明,那么Scala会将参数作为类的成员属性使用,且会提供对应的方法(类似于Java中的getter()和setter()),即这个参数是可读可写的私有成员属性。
实际演示
声明为val:

可以读取,但无法赋值:

声明为var:
可取值可赋值

Bean属性
在Scala字段前加@BeanProperty会自动生成规范的setter()和getter(),此时可以通过对象.setXXX()和对象.getXXX()来调用属性。
注意1:
这里生成的对象.setXXX()和对象.getXXX()和底层当中的属性本身的get、set方法是不冲突的,两者共存。

注意2:
@BeanProperty的存在仅仅是为了保证与Java的互操作性,一旦属性为private,@BeanProperty就不能使用了:

所以,对于private的属性来说,真正的getter和setter是长这么个样子:

TODUDO:关于属性的操作方法 日后补充或新开文章
注意
- Scala中属性和方法都是动态绑定的
- 如下:

抽象属性和抽象方法
基本语法
- 定义抽象类:
abstract class Person{} - 定义抽象属性:
var name: String(属性没有初始化就是抽象属性) - 定义抽象方法:
def hello(): String(只声明没有实现就是抽象方法)
继承和重写
- 如果父类是抽象类,那么子类需要将抽象的属性和方法
实现,否则子类也必须要声明为抽象类 - 重写非抽象方法需要用
overide修饰,重写抽象方法则可以不加 - 子类调用父类的方法用
super关键字 - 子类对抽象属性进行实现,父类抽象属性用
var修饰 - 子类对非抽象属性重写,父类非抽象属性只能用
val修饰,因为:var修饰的为可变变量,子类继承后直接就可使用,没必要重写
匿名子类
与匿名函数类似,当不关心类的名称时,便可直接在代码块中使用匿名子类
例:
def main(args: Array[String]): Unit = {
val stu =new Person {
override var name: String = "hello"
}
println(stu.name)
}
abstract class Person {
var name: String
}
单例对象(伴生对象)
Scala是完全面向对象的语言,没有静态的操作。但Java中有静态的概念。所以为了和Java交互,就产生了单例对象。若单例对象名和类名保持一致,则称该单例对象是这个类的伴生对象,这个类的所有“静态”的内容都可以放在伴生对象中。
例:
def main(args: Array[String]): Unit = {
println(Student.name)
}
class Student {
}
object Student {
val name = "nan"
}
单例模式
定义:单例对象的类只能允许一个实例存在
饿汉式单例模式
不管三七二十一,先把对象创建出来
def main(args: Array[String]): Unit = {
val myStu = Student.getInstance
myStu.printHello()
val myStu2 = Student.getInstance
println(myStu + "\n" + myStu2)
}
class Student private {
def printHello(): Unit = {
println("hello")
}
}
/**
* 饿汉式单例模式
*/
object Student {
private val student = new Student
def getInstance: Student = {
student
}
}
执行结果:

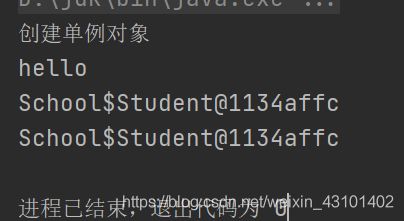
懒汉式单例模式
只有当调用时才创建单例对象,类似于lazy懒加载
def main(args: Array[String]): Unit = {
val myStu = Student.getInstance
myStu.printHello()
val myStu2 = Student.getInstance
println(myStu + "\n" + myStu2)
}
class Student private {
def printHello(): Unit = {
println("hello")
}
}
object Student {
private var student: Student = _
def getInstance: Student = {
if (student == null) {
println("创建单例对象")
student = new Student
}
student
}
}
执行结果:
Trait 特质 (理解不深 日后补充)
在Scala中,用trait(特质)来代替接口
trait既可以有抽象属性和方法,也可以有具体的属性和方法,一个类可以maxin(混入)多个trait
引入trait,既是对接口的代替,又是对单继承的补充
class Student private extends Person with Address {
override var add: String = "China"
override var name: String = "hello"
override var age: Int = 88
def printHello(): Unit = {
println("hello")
}
}
trait Person {
var name: String
var age: Int
}
trait Address {
var add: String
}
trait和抽象类的选择
- 优先选择trait(特质)。一个类扩展多个特质很方便,但只能扩展一个抽象类(单继承嘛)
- 若需要构造函数参数,就使用抽象类。抽象类可以定义带参数的构造函数,特质则不行
对象
枚举类对象
def main(args: Array[String]): Unit = {
println(Week.MONDAY)
println(Week.TUESDAY)
}
object Week extends Enumeration {
val MONDAY = Value(1, "Monday")
val TUESDAY = Value(2, "Tuesday")
}
应用类对象
应用类对象自带main(),可以直接运行

集合
集合有三大类,均来自Iterable特质:
- 序列
Seq - 集
Set - 映射
Map
对于几乎所有的集合类,Scala都同时提供了可变和不可变的版本:
- 不可变集合:
scala.collection.immutable - 可变集合:
scala.collection.mutable
不可变集合:该集合对象不可修改,每次修改就会返回新的对象,而不是对原对象修改,就像Java中的String一样
可变集合:可以直接对原对象进行修改,就像Java中的StringBuilder一样
建议:操作时,可变集合用方法,不可变集合用符号
数组
不可变数组
不可变指的是所指向的对象不可变。数组对象被创建出来后,整体的情况也就都定下了。因此,整体的大小、数组所能容纳的数量、所能存储的数据类型等均不可修改。但是,数组中某一位置上的值还是可以改变的。
定义方式一:
泛型
val arr1 = new Arry[Int](10)
定义方式二:
val arr2 = Array(1, 2, 3, 4)
底层实现原理:
这里实际上调用了Array的伴生对象的apply():

操作
由于不可变数组特性,故仅实现查询、修改操作
修改:
arr2(0) = 1000
查询操作:
arr2(0)arr2.apply(0)
.apply(0)是数组的第一个元素。请注意,索引语法arr2(0)是arr2.apply(0)的简写
通过循环遍历:
val arr2 = Array(1, 2, 3, 4)
for(i <- arr2.indices) {
println("arr2(i):" + arr2(i))
println("arr2.apply(i)" + arr2.apply(i))
}
这里.indices可以返回数组的范围,返回值类型为Range,就相当于0 until arr2.length
执行结果:

也可使用增强for循环:
for (elem <- arr2) println(elem)
迭代器:
val iter = arr2.iterator
while (iter.hasNext) {
println(iter.next())
}
Array对象有foreach()函数可以遍历每一个元素,而这是一个高阶函数,因此可以如下操作:
arr2.foreach((elem: Int) => println(elem))
简化之:
arr2.foreach(println(_))
再简化:
arr2.foreach(println)
除以上之外,还可以直接:
println(arr2.mkString("-"))
//"-"表示用-来连接每个元素
不可变数组的增加
对于不可变数组,增加元素后会返回新的对象
例:
var arr2 = Array(1, 2, 3, 4)
println(arr2)
arr2 = arr2.:+(5)
println(arr2)
println(arr2.mkString(" "))
执行结果:

可以看出,对象已经发生变化了
注意,代码中的:+是一个函数!这表示在数组末尾添加新元素构成新数组。将这两个符号反过来就表示在数组头部添加新元素构成新数组,即:arr2 = arr2.+:(-1)
而在Scala中,.是可以用空格代替的,当小括号内只有一个元素时,小括号也是可以去掉用空格隔开的,因此可以写作:
arr2 = arr2 :+ 5
但对于+:来说,则要把新加入的元素写在其左侧,也就是:
arr2 = -1 +: arr2
无疑,这种方法更方便记忆
练习:
var arr2 = Array(1, 2, 3, 4)
println(arr2)
arr2 = -2 +: -1 +: 0 +: arr2
println(arr2)
arr2 = arr2 :+ 5 :+ 6
println(arr2)
println(arr2.mkString(" "))
结果:

可变数组
ArrayBuffer:
val arr1 = new ArrayBuffer[Int](5)
val arr2 = new ArrayBuffer[Int]()
val arr3 = ArrayBuffer(12, 13, 14)
println("arr1+" + arr1)
println("arr2+" + arr2)
println("arr3+" + arr3)
println("arr1.mkString()+" + arr1.mkString(" "))
println("arr2.mkString()+" + arr2.mkString(" "))
println("arr3.mkString()+" + arr3.mkString(" "))
执行结果:

对于ArrayBuffer来说,打印元素时推荐不要加mkString,因为当数组没有内容时,将没有任何输出内容
可变数组添加元素
1.使用:+ 和 +:
注意:使用他们会返回新的对象,而不是在原对象上添加新元素
例:
var arr = ArrayBuffer(12, 13, 14)
println(arr)
arr = arr :+ 15
println(arr)
}
2.使用+=和+=:
val arr = ArrayBuffer(12, 13, 14)
println(arr)
arr += 15
println(arr)
从这里就能看出,这是在原对象上进行修改的,因为值类型为val,不能赋予新对象
如果要在头部加,则是
val arr = ArrayBuffer(12, 13, 14)
println(arr)
11 +=: arr
println(arr)
使用符号容易和不可变数组混淆,故推荐使用方法:
首尾增加元素:
val arr = ArrayBuffer(12, 13, 14)
println(arr)
arr.append(999)//末尾追加
arr.prepend(-999)//首部追加
println(arr)
任意位置:
val arr = ArrayBuffer(12, 13, 14)
println(arr)
arr.insert(1, 99)
println(arr)

还可以增加数组类型:
arr.appendAll(数组)
arr.prependAll(数组)
arr.insertAll(index, 数组)
可变数组删除元素
1.remove()
val arr = new ArrayBuffer[Int](10)
arr.appendAll(1 to 10)
println(arr)
arr.remove(0)//移除第0个位置的元素
arr.remove(5, 2)//从第五个位置开始,移除两个元素
println(arr)

2.-=
val arr = ArrayBuffer(0, 1, 0, 2, 2, 3, 0, 4, 0, 5)
println(arr)
arr -= 0
arr -= 2
arr -= 100
println(arr)
从左往右删除符合的第一个元素
执行结果:

可变与不可变相互转化
1.可转不可
val arr = ArrayBuffer(0, 1, 0, 2, 2, 3, 0, 4, 0, 5)
val newArr = arr.toArray
println(arr.getClass.getSimpleName)
println(newArr.getClass.getSimpleName)
println(newArr)

2.不可转可
val arr = Array(0, 1, 0, 2, 2, 3, 0, 4, 0, 5)
val newArr = arr.toBuffer
//注意值类型
// val newArr: mutable.Buffer[Int] = arr.toBuffer
println(arr.getClass.getSimpleName)
println(newArr.getClass.getSimpleName)
println(newArr)

多维数组
以二维数组为例
创建
var arr = Array.ofDim[Int](3, 4)//3 * 4大小的二维数组
//var arr: Array[Array[Int]] = Array.ofDim(3, 4)
arr(0)(1) = 1
arr(1)(0) = 9
遍历
方法1
for (i <- arr.indices; j <- arr(i).indices) {
print(arr(i)(j) + " ")
if (j == arr(i).length - 1) {
println()
}
}
方法2
arr.foreach(elem => elem.foreach(println))
简化之:
arr.foreach(_.foreach(println))
列表List
不可变
创建、遍历
val list = List(1, 2, 3, 4)
print(list.mkString(" ") + "\n")
list.foreach(println)
List是abstract,所以不能new
添加元素:
val list = List(1, 2, 3, 4)
val newList = 0+: list :+ 5
print(newList.mkString(" "))
还可以使用::
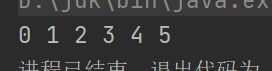
val list = List(1, 2, 3, 4)
val newList1 = list.::(0)
val newList2 = -1 :: newList1
print(newList2.mkString(" "))

借助于::和空列表Nil也可以实现List的创建
val list = 0 :: 1 :: 2 :: 3 :: Nil
print(list.mkString(" "))

注意:双冒号只能在对象名的左侧,表示在list的左侧添加新元素
拼接List
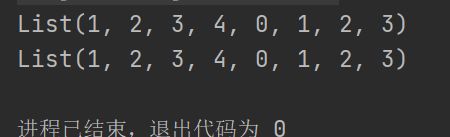
使用:::或++
val list1 = List(1, 2, 3, 4)
val list2= 0 :: 1 :: 2 :: 3 :: Nil
val list3 = list1 ::: list2
val list4 = list1 ++ list2
println(list3)
println(list4)
可变
创建
val list1 = new ListBuffer[Int]()
val list2 =ListBuffer(1, 2, 3, 4)
println(list1)
println(list2)

增加新元素
使用方法增加:
val list1 = new ListBuffer[Int]()
list1.append(1, 2, 3)//尾部加多个元素
list1.appendAll(list1)//尾部加列表
list1.insert(0, 0)//第0个位置加元素0
list1.insertAll(0, list1)
list1.prepend(-2, -1)//头部加元素
list1.prependAll(list1)
println(list1)
使用符号增加:
val list1 = new ListBuffer[Int]()
1 +=: 2 +=: 3 +=: list1 += 4 += 5
println(list1)
合并、拼接list
方法1:++
val list1 = new ListBuffer[Int]()
1 +=: 2 +=: 3 +=: list1 += 4 += 5
val list2 = ListBuffer(6, 7, 8)
val list3 = list1 ++ list2
println(list3)

方法2:++=
val list1 = new ListBuffer[Int]()
1 +=: 2+=: 3 +=: list1 += 4 += 5
val list2 = ListBuffer(6, 7, 8)
list1 ++= list2
println(list1)

方法3:++=:
val list1 = new ListBuffer[Int]()
1 +=: 2 +=: 3 +=: list1 += 4 += 5
val list2 = ListBuffer(6, 7, 8)
list1 ++=: list2
println(list1)
println(list2)
修改元素
val list1 = new ListBuffer[Int]()
1 +=: 2 +=: 3 +=: list1 += 4 += 5
list1(0) = 11
println(list1)
等同于
list1.update(0, 11)
删除
val list1 = new ListBuffer[Int]()
1 +=: 2 +=:3 +=: list1 += 4 += 5
list1.remove(0)
println(list1)

或使用-=
从左到右删除第一个符合的元素
val list1 = new ListBuffer[Int]()
3 +=: 2 +=: 3 +=: list1 += 4 += 5
list1 -= 3
println(list1)

集合Set
和数组、列表一样,在Scala中,也分为可变Set和不可变Set
在默认情况下,使用的是不可变集合,如果要用可变集,需要引用scala.collection.mutable.Set包
集合特性:在集合中,不关心数据的先后顺序,且无重复数据
不可变集合
创建
val set = Set(1, 2, 2, 5, 6, 6, 6, 10)
println(set)
执行结果:

对于Set,不能使用new来创建,因为Set是trait:

添加新元素
val set = Set(1, 2, 2, 5, 6, 6, 6, 10)
println(set)
//因为是不可变,且.+会返回新对象,所以要创建新的常量来接收
val newSet = set.+(55)
val nnSet = newSet + 33
//添加新元素后出现的位置是不固定的
//对于set来说,也无需关系顺序
println(nnSet)
结果:

合并Set
使用两个加好:++
val set = Set(1, 2, 2, 5, 6, 6, 6, 10)
val set2 = Set(5, 6, 7)
val nnSet = set ++ set2
println(nnSet)
执行结果:
删除元素
val set = Set(1, 2, 2, 5, 6, 6, 6, 10)
println("set " + set)
val set2 = set - 6
println("set " + set)
println("set2 " + set2)
执行结果:

可以看出,去掉元素后,原Set没有发生变化,而新的Set中元素已经删除
可变Set
创建
创建时需要声明类型
val set = mutable.Set(1, 2, 3)
//val set: mutable.Set[Int] = mutable.Set(1, 2, 3)
添加元素
val set = mutable.Set(1, 2, 3)
set += 4
或使用add方法:
set.add(4)
删除元素
1.-=
set -= 2
2.remove()
val flag = set.remove(2)
若被删除,则flag为true,否则为false
合并
1.++
使用++并不会改变双方的值,而是返回新的set:
val set = mutable.Set(1, 2, 3)
val set2 =mutable.Set(5,2,1)
val newSet = set ++ set2
println(set)
println(set2)
println(newSet)

2.++=
++=会改变左侧的操作数:
val set = mutable.Set(1, 2, 3)
val set2 = mutable.Set(5,2,1)
val newSet = set ++= set2
println(set)
println(set2)
println(newSet)
结果:

Map
这是一个散列表,存储的内容是键值对(key-value)映射
不可变Map
创建
val map = Map("li" -> 18, "wang" -> 19, "zhang" -> 20)
val map_new: Map[String, Int] = Map()
遍历元素
两种方式:for循环和foreach
推荐使用foreach的简写形式
val map = Map("li" -> 18, "wang" -> 19, "zhang" -> 20)
for (i <- map) {
println(i)
}
//(String, Int)就是元组类型
map.foreach((kv: (String, Int)) => println(kv))
//简写为
map.foreach(println)
对map取key或value
for (key <- map.keys) {
println(s"$key --> ${map.get(key)}")
}
若是使用map.get("you key"))会返回Some类型
所以要想得到元素自身还需要再次get:
map.get("you key").get
但这样存在一个问题:
若不存在元素,则使用map.get("you key"))会返回None,而None显然是没有get方法的,所以使用map.get("you key").get有抛异常的可能性!
当然,可以用try-catch来接收:
val map = Map("li" -> 18, "wang" -> 19, "zhang" -> 20)
try{
println(map.get("33").get) //对于None使用get会抛异常
}
catch {
case ex: NoSuchElementException => {
println("key->value不存在")
}
}
不过更推荐使用:
val defaultValue = 0//设定默认值
println(map.getOrElse("2222", defaultValue))
这样在访问不存在的元素时,会返回自己设定的默认值
可变Map
实际上就是HashMap
创建
val map = mutable.Map("li" -> 18, "wang" -> 19, "zhao" -> 20)
val map2: mutable.Map[String, Int] = mutable.Map("hong" -> 18, "zzz" -> 19)
添加和修改元素
在map中,添加和修改没有太多区别:若存在对应的key,则修改value,否则将添加新的键值对
1.使用put
map.put("nan", 444)
2.使用+=
map.+=(("nan", 444))
在省略.时要注意,添加元素需要的类型是元组,而只写为map += ("nan", 444)就相当于是map.+=("nan", 444),也就是两个参数,这时map接收的数据就变为了单个字符串"nan"了,这显然是错误的。
因此正确的写法是:
map += (("nan", 444))
//第一个括号表示参数 第二个括号表示元组类型
3.update
val map: mutable.Map[String, Int] = mutable.Map()
//不存在key则添加
map.update("nan", 444)
println(map)
//已存在则修改
map.update("nan", 555)
println(map)

删除元素
1.remove
val map = mutable.Map("nan" -> 444, "zzz" -> 555)
println(map.remove("nan"))
println(map.remove("2222"))

如果是删除不存在的元素,会返回None
否则会返回 要删除的元素
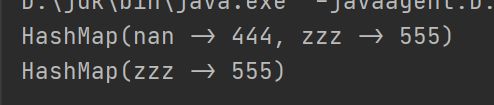
2.-=
val map = mutable.Map("nan" -> 444, "zzz" -> 555)
println(map -= "nnnn")
println(map -= "nan")
合并
使用++和++=
如果合并时,存在相同的key,则会对value进行覆盖
val map = mutable.Map("nan" -> 444, "zzz" -> 555)
val map2 = Map("hello" -> 666)
map ++= map2
val map3 = map ++ map2
val map4 = map2 ++ map
println(s"type:${map.getClass.getSimpleName} val:$map")
println(s"type:${map2.getClass.getSimpleName} val:$map2")
println(s"type:${map3.getClass.getSimpleName} val:$map3")
println(s"type:${map4.getClass.getSimpleName} val:$map4")

元组tuple
元组是一种元素,可以存放多种不同类型的数据,元组中最大支持22个元素,也可以进行元组嵌套
声明、创建
//创建tuple
val tup = ("nan", 444, "中国 北京 海淀区", ("水瓶座", "爱好玩"))
访问元组各个元素
//访问各个元素
println(tup._1)
println(tup._2)
println(tup._3)
//嵌套元组的访问
println(tup._4._1)
println(tup._4._2)
println(tup.productElement(2)) //访问第3个元素
遍历
//遍历
for (elem <- tup.productIterator) {
println(elem)
}
队列
可变队列
- 创建
- 入队
- 出队
val queue1 = mutable.Queue(1, 2, 3)
val queue2 = new mutable.Queue[String]()
//入队
println(queue1)
queue1.enqueue(6, 7)
println(queue1)
//出队
queue1.dequeue()
println(queue1)
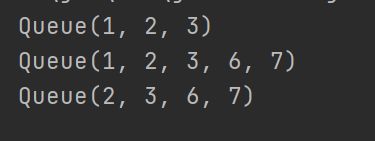
不可变队列
- 创建
- 入队
- 出队
对于不可变队列来说。每次入队出队都要赋给新的对象,因为原队列是不会变化修改的
//不可变队列
val que_im = immutable.Queue(5, 2, 3)
//入队 因为不可变 所以需要赋给新的对象
val que_im_en = que_im.enqueue(8)
println(que_im)
println(que_im_en)
//出队
val que_im_de = que_im_en.dequeue //返回的是元组,包含出队的元素和剩余的队列
println(que_im_de)
并行集合
Scala为了充分利用多核CPU,提供了并行集合
在Scala 2.13.x版本中,需要导入依赖才可以使用并行集合。导入依赖或出现idea对依赖文件报错,请参考这篇文章
以下是单核心和多核心运行的对比:
import scala.collection.parallel.CollectionConverters._
import scala.collection.parallel.immutable.ParSeq
object Test13_Parallel {
def main(args: Array[String]): Unit = {
//输出单线程的执行线程
val result = (1 to 100).map(
elem => {
Thread.currentThread().getId
}
)
println(result)
val res: ParSeq[Long] = (1 to 100).par.map(
elem => {
Thread.currentThread().getId
}
)
println(res)
}
}

集合函数
常用函数
-
获取集合长度
list.length -
获取集合大小
list.size -
循环遍历
for循环或foreach -
迭代器
for (elem <- list.iterator) {
println(elem)
}
- 生成字符串
println(list)
println(list.mkString("-"))
- 是否包含某元素
list.contains(4)
衍生集合操作
针对单一集合
//获取集合的头部
println(list.head)
//获取集合的尾 除了头都是尾
println(list.tail)
//获取集合的最后一个元素
println(list.last)
//获取集合初始数据 即除了last外的全部
println(list.init)
//反转
println(list.reverse)
//获取前、后n个元素
println(list.take(4))
println(list.takeRight(4))
//去掉前、后n个元素 不会删除原数据
println(list.drop(2))
println(list.dropRight(2))
println(list)
针对两个集合
并集
.union().concat()++:::
//并集
val union = list.union(list2)
println(union)
//union()被弃用了 推荐concat
val union_concat = list.concat(list2)
val union_plus = list ++ list2
val un = list ::: list2
println(union_concat)
println(union_plus)
如果是set做并集 会自动去重
交集
//交集
val intersection = list.intersect(list2)
println(intersection)
差集
//差集
val diff = list.diff(list2)
val diff2 = list2.diff(list)
println(diff)
println(diff2)
list1.diff(list2)返回的是在list1中与list2不同的内容
拉链
把两个集合中的元素,从前到后依次两两组合,并返回List,返回值中的元素是元组
val zip = list.zip(list2)
println(zip)
![]()
滑动窗口
println("=========sliding(4)============")
//滑动窗口
val listNew = List(1, 3, 5, 7, 9, 11)
for (elem <- listNew.sliding(4)) {
println(elem)
}
println("========sliding(4, 4)=============")
for (elem <- listNew.sliding(4, 4)) {
//设置大小size和步长step
println(elem)
}

简单函数
求和
val list = List(1, 2, 3, 4, 5, 6)
//求和函数
println(list.sum)
求乘积
//求乘积
val list = List(1, 2, 3, 4, 5, 6)
println(list.product)
求最大最小值
val list = List(1, 2, 3, 4, 5, 6)
//求最大值
println(list.max)
//求最小值
println(list.min)
但如果是val listTuple = List(("123", 2), ("333", 77), ("fd", 10))这样的,则需要选择比较的元素
这里以元组中第二个元素为比较对象进行找大小:
//根据元组中第二个元素选最大、最小值
val listTuple = List(("123", 2), ("333", 77), ("fd", 10))
println(listTuple.maxBy((tuple: (String, Int)) => tuple._2))
println(listTuple.minBy((tuple: (String, Int)) => tuple._2))
//简写为
println(listTuple.minBy(_._2))
排序
.sorted.sortBy.sortWith
若list中存放的单个的元素:
//排序
var sortedList = list.sorted //小到大
println(sortedList)
sortedList = list.sorted.reverse //逆序变为大到小 但不推荐 效率差
println(sortedList)
sortedList = list.sorted(Ordering[Int].reverse) //传入隐式参数 表示逆序排列
println(sortedList)
如果存放的是元组,那么可以根据指定的元素排序:
//对 list中存放的元组排序
var sortedListTuple = listTuple.sortBy((tuple: (String, Int)) => tuple._2)
println(sortedListTuple)
sortedListTuple = listTuple.sortBy(_._2)
println(sortedListTuple)
也可以使用.sortWith自定义排序规则:
//使用sortWith自定义排序规则
println(list.sortWith((a: (Int), b: (Int)) => a < b))
println(list.sortWith(_ < _))
println(list.sortWith(_ > _))
println(listTuple.sortWith((a: (String, Int), b: (String, Int)) => a._2 < b._2))
println(listTuple.sortWith(_._2 < _._2))
集合计算高级函数
过滤 .filter()
遍历一个集合并获取指定条件下的元素,同时组成新集合
例:将list数字分为奇偶两组
//过滤、筛选
//将其分为奇偶两组
val listOdd = listNumber.filter((elem: Int) => elem % 2 == 1)
val listEven = listNumber.filter(_ % 2 == 0)
转化/映射(map)
将集合中的每一个元素映射到某个函数
//map 映射
//将集合中每个元素乘以2
val resultProduct = listNumber.map(_ * 2)
扁平化 .flatten
例:List中可能存在嵌套的情况,扁平化便是消除嵌套
//扁平化
val listNested =List(List(1, 2, 3, 4), List(3, 3, 4), List(4, 75))
val list_flat1 = listNested(0) ::: listNested(1) ::: listNested(2)
val list_flat2 = listNested(0) ++ listNested(1) ++ listNested(2)
println(list_flat1)
println(list_flat2)
//更便捷的操作
val list_flat3 = listNested.flatten
println(list_flat3)
扁平化+映射
这是二者的结合,先map,再flatten
//扁平化+映射
val listMessage = List("hello world", "wang yi bo", "xiao zhan")
//目的:将message按空格分割并组成新列表
//分步操作
//1.分割
val list_split = listMessage.map(_.split(" ")) //按照空格分隔并映射
println(list_split) //此时得到的是嵌套的List
//2.扁平化
val list_flatten = list_split.flatten //扁平化
println(list_flatten)
当然,也有更简便的方法:扁平映射flatmap
val list_flatten_better = listMessage.flatMap(_.split(" "))
分组group
一组数据按照规则分成多组
分组练习1 奇偶分组
val listNumber = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
println("========分组=============")
//分组groupBy
//将其分为奇偶两组
val map_group = listNumber.groupBy(_ % 2)
println(map_group)
//让结果更易读
val map_group_better = listNumber.groupBy(num => {
if (num % 2 == 0) {
"偶数"
}
else {
"奇数"
}
})
println(map_group_better)
分组练习2 单词首字母分组
//练习二:按照单词首字母分组
val listWords = List("book", "name", "word", "apple", "abandon")
val map_group_word = listWords.groupBy(_(0))
println(map_group_word)
![]()
规约
规约操作(reduction operatio),是通过某个连接动作将所有元素汇总成一个结果的过程。元素求和、求最大值或最小值、求出元素总个数、将所有元素转换成一个列表或集合,都属于规约操作。
求和练习
//用规约实现list求和
val list = List(1, 2, 3, 4)
val list_sum = list.reduce(_ + _)
val list_sum_left = list.reduceLeft(_ + _)
val list_sum_right = list.reduceRight(_ + _)
查看方法实现代码可知,reduce()是调用reduceLeft()实现的

减法
通过减法,探究规约执行的顺序
//规约减法 探究规约执行的顺序
val list = List(1, 2, 3, 5)
val list_subtraction = list.reduce(_ - _) //1 - 2 - 3 - 5
println(list_subtraction)
val list_subtraction_left = list.reduceLeft(_ - _)
println(list_subtraction_left)
//查看底层可知 reduce是调用reduceLeft()实现的
val list_subtraction_right = list.reduceRight(_ - _) //1 - (2 - (3 - 5))
println(list_subtraction_right)
折叠 fold
在fold函数中,多了一个预先传入的参数
//折叠 fold
val list_fold_sum = list.fold(10)(_ + _) //10 + 1 + 2 + 3 + 4 + 5
println(list_fold_sum)
val list_fold_sum_left = list.foldLeft(10)(_ + _) //10 + 1 + 2 + 3 + 4 + 5
println(list_fold_sum_left)
val list_fold_subtraction_right = list.foldRight(10)(_ - _) //1 - (2 - (3 - (5 - 10)))
println(list_fold_subtraction_right)
练习:合并map
现有两个map,要求进行合并,key值相同的value进行累加
//合并两个map 要求key值相同的value进行累计
val map1 = Map("a" -> 1, "b" -> 34,"x" -> 45,"r" -> 23)
val map2 = mutable.Map("a" -> 76, "b" -> 1,"x" -> 2,"r" -> 3, "c" -> 2)
//注意:若使用++ 那么会对value进行覆盖操作
//这里使用foldLeft完成操作
//fold只能使用两个相同类型的数据 而foldLeft支持不同类型
val map_result = map1.foldLeft(map2)((marged, kv) => {
val key = kv._1
val value = kv._2
marged(key) = marged.getOrElse(key, 0) + value
marged
})
println(map1)
println(map2)
println(map_result)
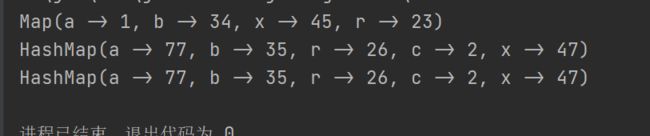
理解这一过程,可以结合foldLeft()源码:
/** Applies a binary operator to a start value and all elements of this $coll,
* going left to right.
*
* $willNotTerminateInf
* $orderDependentFold
*
* @param z the start value.
* @param op the binary operator.
* @tparam B the result type of the binary operator.
* @return the result of inserting `op` between consecutive elements of this $coll,
* going left to right with the start value `z` on the left:
* `op(...op(z, x,,1,,), x,,2,,, ..., x,,n,,)` where `x,,1,,, ..., x,,n,,`
* are the elements of this $coll.
* Returns `z` if this $coll is empty.
*/
def foldLeft[B](z: B)(op: (B, A) => B): B = {
var result = z
val it = iterator //A的迭代器
while (it.hasNext) {
result = op(result, it.next())
}
result
}
案例:WordsCount 简单版
单词计数:将集合中出现的相同的单词进行统计,取前三名
此练习非常重要,综合性极强,值得研究每一步
代码如下:
object Test10_CommonWordCount {
def main(args: Array[String]): Unit = {
//单词计数:将集合中出现的相同的单词进行统计,取前三名
val message = List("hello world", "hello scala", "hello spark", "hello flink from scala")
//1. 分割单词 扁平化+映射
val res1 = message.flatMap(_.split(" "))
println(res1)
//2. 相同的单词进行分组
val res2_groupBy = res1.groupBy( word => word) //这里不可以直接写为_
println(res2_groupBy)
//3. 计数 用映射实现
val res3 = res2_groupBy.map(kv => (kv._1, kv._2.length))
println(res3)
//4. 排序 只有list可以排序 所以要类型转换
val res4 = res3.toList.sortWith(_._2 > _._2).take(3)
println(res4)
}
}
执行结果:
![]()
模式匹配
类似于Java中的switch-case语句
特性如下:
- 如果所有
case都不匹配,那么执行case _分支,类似于default语句。若此时没有case _分支,会抛出MatchError - 每个
case中不需要break语句 match case语句可以匹配任何类型=>后面的代码块。直到下一个case语句之前的代码都是作为一个整体执行的,可以用大括号包括,也可以没有
简单演示
object Test01_PatternMatchBase {
def main(args: Array[String]): Unit = {
//模式匹配
val num = 234
val check_num = num match {
case 1 => "a"
case 2 => "b"
case 3 => "c"
case _ => "no"
}
println(check_num)
val a = 10
val b = 23
def compute(op: Char) = op match {
case '+' => a + b
case '-' => a - b
case '*' => a * b
case '/' => a / b
}
println(compute('*'))
}
}
结果:

模式守卫
如果想要表达匹配某个范围的数据,就需要在模式匹配中增加条件守卫
案例:求数字绝对值
//数字绝对值
def abs(num: Int) = num match {
case n if n >= 0 => n //定义一个变量n来接收传入的数值 再加以判断
case _ => -num
}
println(abs(1))
println(abs(0))
println(abs(-234))
匹配常量
模式匹配可以匹配常量,且类型不固定
//匹配常量
def describe_const(n: Any) = n match {
case "hello" => "world"
case "ni hao" => "hello"
case 123 => "123"
case true => "true"
case _ => "anyway"
}
println(describe_const(123))
匹配类型
在匹配类型时,存在着类型擦除问题
//scala类型匹配
//小心类型擦除问题
def describe_type(n: Any): String = n match {
case i:String => "String: " + i
case i:Int => "Int: " + i
case i:Array[Int] => "Array[Int]: " + i.mkString(" ")
case i:Array[String] => "Array[String]: " + i.mkString(" ")
case i:List[String] => "List[String]: " + i.mkString(" ")
case i:List[Int] => "List[Int]: " + i.mkString(" ")
case i => "其它类型: " + i
}
println(describe_type("hello"))
println(describe_type(123))
println(describe_type(Array("123", "hello")))
println(describe_type(Array(123, 123)))
println(describe_type(Array(123l, 123l)))
println(describe_type(List("123", "hello")))
println(describe_type(List(7777, 123))) //这里尽管是数字,但还是按照List[String]处理了
// 因为对于case来说,识别到List就直接确定了,不会去确认元素的类型 这就是类型擦除问题
//但对于Array则不存在这样的问题

匹配集合-数组
//匹配数组(集合)
List(
Array(0),
Array(1, 0),
Array("hello", 1),
Array(12, 24, 34),
Array(23, 23, 234, 34, 34)
).foreach(elem => elem match {
case Array(0) => println("0")
case Array(1, 0) => println("1, 0")
case Array(x, y) => println(x.toString + y.toString)
case Array(x, 24, z) => println(x.toString + 24 + z.toString)
case Array(23, _*) => println("23.......")
})
println("==========foreach中集合匹配简写==========")
//其中模式匹配可以简写为:(偏函数)
List(
Array(0),
Array(1, 0),
Array("hello", 1),
Array(12, 24, 34),
Array(23, 23, 234, 34, 34)
).foreach {
case Array(0) => println("0")
case Array(1, 0) => println("1, 0")
case Array(x, y) => println("两个元素的数组")
case Array(x, 24, z) => println(x.toString + 24 + z.toString)
case Array(23, _*) => println("以23开头的类型")
case _ => "其它类型"
}
匹配集合-列表
//匹配列表
val list1 = List(1, 2, 3, 4, 5)
val list2 = List(3)
def describe_list(op: Any) = op match {
//这里表示列表的链接 一个列表分为三部分
case first :: second :: last => s"first: $first second: $second last: $last"
case _ => "other"
}
println(describe_list(list1))
println(describe_list(list2))
匹配元组
方式和匹配数组、列表相同
//匹配元组
for (tuple <- List(
(12, 23),
(0, 23),
("Hello", 23),
(12, 23, 23),
(12, true, 1),
(12, 0.5)
)) {
val result = tuple match {
case (0, _) => "0开头 两个元素"
case ("Hello", _) => "Hello + 两个元素"
case (_, true, _) => "中间值为true 三元"
case (_, 0.5) => "有0.5"
case _ => "other"
}
println(result)
}
在其他位置进行模式匹配
变量声明时匹配
//模式匹配也可以用在变量声明中
val (x, y) = (10, "hello world")
println(x + " " + y)
val List(num1, num2, _*) = List(1, 2, 3, 4, 5, 6)
println(s"num1: $num1 num2: $num2")
val first :: second :: last = List(1, 2, 3, 4, 5, 6)
println(s"fir: $first, sec: $second, last: $last")
在循环中匹配
val list_num = List(("hello", 10), ("hello", 45), ("abc", 45), ("wer", 98))
for ((word, number) <- list_num) {
println(word + " " + number)
}
//只获取key或value
println("======只获取word===========")
for ((word, _) <- list_num) {
println(word)
}
//还可以进行筛选
println("======筛选hello的number===========")
for (("hello", number) <- list_num) {
println(number)
}
模式匹配-匹配对象
对 对象进行模式匹配,不能直接在case后面跟一个对象,因为两个对象都是引用类型,不可能相同,而且这种方式本来也是错误的
实现对象匹配,需要借助于伴生对象和apply()、unapply()方法
通过unapply()方法,实现对 对象数据的拆解,才能让case进行匹配判断
object Test02_MatchObject {
def main(args: Array[String]): Unit = {
val stu = new Student("bob", 300)
val result = stu match {
case Student("bob", 300) => "it's right"
case _ => "other"
}
println(result)
}
class Student(var name: String, var age: Int)
object Student {
def apply(name: String, age: Int): Student = new Student(name, age)
def unapply(student: Student): Option[(String, Int)] = {
if (student == null) {
None
}
else {
Some((student.name, student.age))
}
}
}
}
样例类
为了简化以上操作,于是有了case类。case类帮助我们自动生成了伴生对象和当中的apply()、unapply()方法
object Test02_MatchObject {
def main(args: Array[String]): Unit = {
//case类可以替我们解决手写apply、unapply的问题
val stu_new = new StudentNew(name = "bob", age = 300)
val result_new = stu_new match {
case StudentNew("bob", 300) => "it's right"
case _ => "other"
}
println(result_new)
}
case class StudentNew(name: String, age: Int)
}
注:IDEA可以帮助我们生成case类:

在case类中,主构造器内的参数默认就是属性,var可以省略

泛型
逆变与协变
协变:Son是Father的子类,则MyList[Son]也作为MyList[Father]的子类,MyList[Son]产生的对象赋给MyList[Father]类型,即 某个返回的类型可以由其派生类型替换
逆变:Son是Father的子类,MyList[Father]产生的对象赋给MyList[Son]类型, 即:某个参数类型可以由其基类替换
代码演示-协变:
现有如下继承关系:
class Parent {
}
class Child extends Parent {
}
class SubChild extends Child {
}
在创建对象时,可以把子类赋予父类类型:
val child: Parent = new Child
而现在,需要把这种方式带入到 带泛型的集合类型中
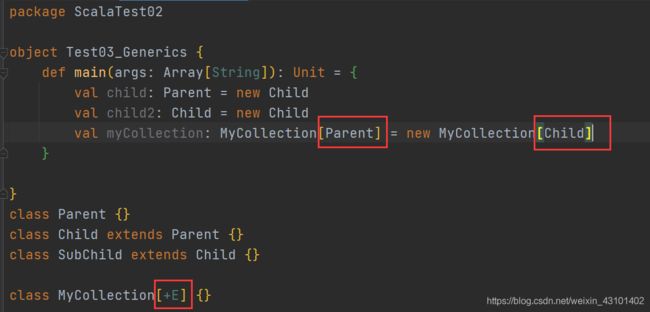
//泛型定义
class MyCollection[E] {
}
需要实现这样的效果:
val myCollection: MyCollection[Parent] = new MyCollection[Child]
当然,这样写肯定是会报错的,所以需要用到协变:
//泛型定义中 在E前加一个加号即可
class MyCollection[+E] {
}
现在,这样就是合法的:
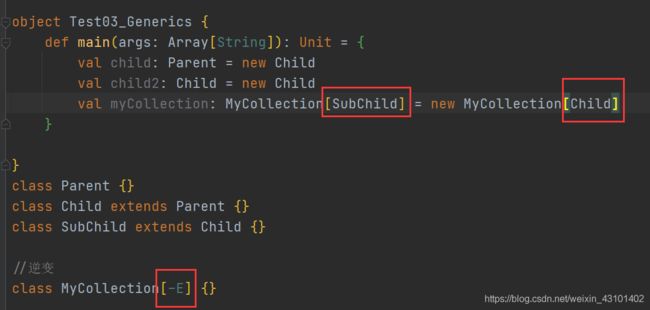
代码演示-逆变:
+E改为-E即可
泛型限定
泛型上下限

测试:

可以发现,当设定好上限后,若超过则编译无法通过
而这样是可行的:

输出结果:
上下文限定

包
和Java一样,Scala中管理项目也是可以用包的,不过Scala的包更加强大,所以使用也相对复杂
在Scala中,包名和源码所在的系统文件目录结构可以不一致,但是编译后的字节码文件路径和包名会保持一致,这个工作由编译器完成。
在引用包时可以使用绝对路径也可以使用相对路径。
包的作用
- 把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用
- 可以更好得维护程序结构
- 避免因为类名相同造成的冲突
- 包也限定了访问权限,拥有包访问权限的类才能访问某个包中的类。
包的基本使用
由于Scala具有类型自动匹配,所以在使用包、创建类对象时非常的简洁方便,而不会像Java一样代码特别冗长。
package com.test.scalaDemo2
import com.test.scala01.Test2 //引入包
object myClass {
def main(args: Array[String]): Unit = {
val cat = new Test2.Cat
cat.age = 12
}
}
注意
在Scala中,有三个包是自动引入的:
java.lang.*scala包Predef包
引入包,并不会引入该包下的子包,所以对于子包还需要单独引入
例如要想实现从控制台读取输入的内容,还需要单独import scala.io._
管理风格
Scala有两种管理风格
Java包管理风格
每个源文件一个包,但 包名和源文件所在路径不要求一致,包名用.进行分割表示包的层级关系
嵌套的包管理风格
package com {
package haha {
package scala {
}
}
}
特点如下:
- 一个源文件可以声明多个
package - 子包中的类可以直接访问父包中的内容,而无需导包。但反之则必须要导包
导包

查看包的内容
ctrl+鼠标左键 或 ctrl+b

前提是关联了Scala源码,相关内容参考前文
打包


作用域原则:
- 可以直接向上访问。即在
scala中子包中直接访问父包中的内容,大括号体现作用域。而在Java中子包使用父包的类,需要import。 - 在子包和父包类重名时,默认采用就近原则,如果希望指定使用某个类,则带上包名即可。
- 对于父包来说,要想访问子包内容时,需要
import对应的类。
包对象
由于Java虚拟机的局限,导致包可以包含类、对象和特质trait,但不能包含函数/方法或变量的定义。
为了弥补这一不足,Scala提供了包对象。
课后练习
对文中练习链接的汇总
匿名函数与高阶函数的练习
高阶函数练习二:对数组进行处理,将操作抽象出来,处理完毕后返回一个新的数组
高阶函数练习三
高阶函数练习四:用自定义函数实现while循环功能