NLP (一): 自然语言和单词的分布式表示
- 本文为《深度学习进阶: 自然语言处理》的读书笔记
- 记录一个课程, 有机会可以看下: CS224d: Deep Learning for Natural Language Processing
目录
- 自然语言处理 (NLP)
- 同义词词典 (thesaurus)
-
- WordNet
- 同义词词典的问题
- 基于计数的方法
-
- 基于 Python 的语料库的预处理
- 单词的分布式表示
- 分布式假设 (distributional hypothesis)
- 共现矩阵 (co-occurence matrix)
- 向量间的相似度
- 相似单词的排序
- 基于计数的方法的改进
-
- 点互信息 (PMI)
- 降维 (dimensionality reduction)
- 基于 SVD 的降维
- PTB 数据集
- 基于 PTB 数据集的评价
自然语言处理 (NLP)
Natural Language Processing
- 我们平常使用的语言,如日语或英语,称为自然语言(natural language); 自然语言处理的目标就是让计算机理解人说的话,进而完成
对我们有帮助的事情
单词含义
- 我们的语言是由文字构成的,而语言的含义是由单词构成的。换句话说,单词是含义的最小单位。因此,为了让计算机理解自然语言,让它理解单词含义可以说是最重要的事情了
同义词词典 (thesaurus)
- 要表示单词含义,首先可以考虑通过人工方式来定义单词含义. 在同义词词典中,同义词或近义词被归类到同一个组中
- 比如,使用同义词词典,我们可以知道 car 的同义词有 automobile、motorcar 等
- 另外,在自然语言处理中用到的同义词词典有时会定义单词之间的粒度更细的关系,比如“上位- 下位”关系、“整体- 部分”关系

- 像这样,通过对所有单词创建近义词集合,并用图表示各个单词的关系,可以定义单词之间的联系。利用这个“单词网络”,可以教会计算机单词之间的相关性
如何使用同义词词典根据自然语言处理的具体应用的不同而不同。比如,在信息检索场景中,如果事先知道 automobile 和 car 是近义词,就可以将 automobile 的检索结果添加到 car 的检索结果中
WordNet
- 在自然语言处理领域,最著名的同义词词典是 WordNet. WordNet 中收录了超过 20 万个单词
- 使用 WordNet,可以获得单词的近义词,或者利用单词网络。使用单词网络,可以计算单词之间的相似度
可以参考 附录 B
同义词词典的问题
- 难以顺应时代变化
- 新词不断出现,而那些落满尘埃的旧词不知哪天就会被遗忘
- 语言的含义也会随着时间的推移而变化
- 人力成本高
- 无法表示单词的微妙差异
基于计数的方法
- 语料库 (corpus): 收集大量用于自然语言处理研究和应用的文本数据, 其中的文章都是由人写出来的; 有名的语料库有 Wikipedia 和 Google News 等
- 自然语言处理领域中使用的语料库有时会给文本数据添加额外的信息。比如,可以给文本数据的各个单词标记词性。在这种情况下,为了方便计算机处理,语料库通常会被结构化(比如,采用树结构等数据形式)
- 这里,假定我们使用的语料库没有添加标签,而是作为一个大的文本文件,只包含简单的文本数据
- 基于计数的方法的目标就是从这些富有实践知识的语料库中,自动且高效地提取本质
基于 Python 的语料库的预处理
- 这里所说的预处理是指,将文本分割为单词 (分词),并将分割后的单词列表转化为单词 ID 列表
- 本章我们先使用仅包含一个句子的简单文本作为语料库,然后再处理更实用的语料库
text = 'You say goodbye and I say hello.' # 语料库的样本文章
text = text.lower() # 将所有字母转化为小写,这样可以将句子开头的单词也作为常规单词处理
text = text.replace('.', ' .') # 方便后面用空格切分句子
print(text) # you say goodbye and i say hello .
words = text.split(' ') # 将空格作为分隔符, 切分句子
print(words) # ['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.']
通过导入正则表达式的
re模块,使用re.split('(\W+)?', text)也可以进行分词
- 虽然分词后文本更容易处理了,但是直接以文本的形式操作单词,总感觉有些不方便。因此,我们进一步给单词标上 ID,以便使用单词 ID 列表
>>> word_to_id = {
} # 将单词转化为单词 ID
>>> id_to_word = {
} # 将单词 ID 转化为单词
>>>
>>> for word in words:
... if word not in word_to_id:
... new_id = len(word_to_id)
... word_to_id[word] = new_id
... id_to_word[new_id] = word
>>> import numpy as np
>>> corpus = [word_to_id[w] for w in words]
>>> corpus = np.array(corpus) # 单词 ID 列表
>>> corpus
array([0, 1, 2, 3, 4, 1, 5, 6])
- 将上述一系列处理实现为
preprocess()函数
def preprocess(text):
text = text.lower()
text = text.replace('.', ' .')
words = text.split(' ')
word_to_id = {
}
id_to_word = {
}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word
单词的分布式表示
- 分布式表示: 将单词表示为固定长度的向量. 这种向量的特征在于它是用密集向量表示的。密集向量的意思是,向量的大多数元素是由非 0 实数表示的
- 例如,三维分布式表示是 [ 0.21 , − 0.45 , 0.83 ] [0.21,-0.45,0.83] [0.21,−0.45,0.83]
分布式假设 (distributional hypothesis)
- 分布式假设: 某个单词的含义由它周围的单词形成
- 分布式假设所表达的理念非常简单。单词本身没有含义,单词含义由它所在的上下文(语境)形成。的确,含义相同的单词经常出现在相同的语境中
- 比如 “I drink beer.” “We drink wine.”,drink 的附近常有饮料出现。另外,从 “I guzzle beer.”“We guzzle wine.”可知,guzzle 和 drink 所在的语境相似。进而我们可以推测出,guzzle 和 drink 是近义词
- 从现在开始,我们会经常使用“上下文”一词。本章说的上下文是指某个单词(关注词)周围的单词. 这里,我们将上下文的大小(即周围的单词有多少个)称为窗口大小(window size)。窗口大小为 n n n,上下文包含左右各 n n n 个单词

根据具体情况,也可以仅将左边的单词或者右边的单词作为上下文。此外,也可以使用考虑了句子分隔符的上下文。简单起见,本书仅处理不考虑句子分隔符、左右单词数量相同的上下文
共现矩阵 (co-occurence matrix)
- 基于分布式假设使用向量表示单词,最直截了当的实现方法是对周围单词的数量进行计数
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
print(corpus)
# [0 1 2 3 4 1 5 6]
print(id_to_word)
# {0: 'you', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello', 6:
'.'}
- 下面,我们计算每个单词的上下文所包含的单词的频数。在这个例子中,我们将窗口大小设为 1. 下图是汇总了所有单词的共现单词的表格。这个表格的各行对应相应单词的向量。该表格就称为共现矩阵
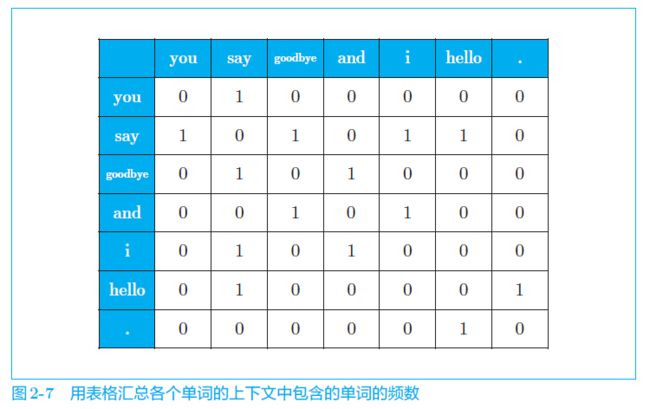
# corpus 是单词 ID 列表
# vocab_size 是词汇个数
# window_size 是窗口大小
def create_co_matrix(corpus, vocab_size, window_size=1):
corpus_size = len(corpus)
co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
for i in range(1, window_size + 1):
left_idx = idx - i
right_idx = idx + i
if left_idx >= 0:
left_word_id = corpus[left_idx]
co_matrix[word_id, left_word_id] += 1
if right_idx < corpus_size:
right_word_id = corpus[right_idx]
co_matrix[word_id, right_word_id] += 1
return co_matrix
向量间的相似度
- 在测量单词的向量表示的相似度方面,余弦相似度(cosine similarity)是很常用的
 式 (2.1) 的要点是先对向量进行正规化,再求它们的内积
式 (2.1) 的要点是先对向量进行正规化,再求它们的内积
def cos_similarity(x, y, eps=1e-8):
nx = x / (np.sqrt(np.sum(x ** 2)) + eps)
ny = y / (np.sqrt(np.sum(y ** 2)) + eps)
return np.dot(nx, ny)
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
c0 = C[word_to_id['you']] # you的单词向量
c1 = C[word_to_id['i']] # i的单词向量
print(cos_similarity(c0, c1))
# 0.7071067691154799
# 由于余弦相似度的取值范围是 −1 到 1,所以可以说这个值是相对比较高的(存在相似性)
相似单词的排序
- 当某个单词被作为查询词时,将与这个查询词相似的单词按降序显示出来
"""
@ query: 查询词
@ word_to_id: 单词到单词ID 的字典
@ id_to_word 单词ID 到单词的字典
@ word_matrix 汇总了单词向量的矩阵,假定保存了与各行对应的单词向量
@ top 显示到前几位
"""
def most_similar(query, word_to_id, id_to_word, word_matrix, top=5):
# 取出查询词
if query not in word_to_id:
print('%s is not found' % query)
return
print('\n[query] ' + query)
query_id = word_to_id[query]
query_vec = word_matrix[query_id]
# 计算余弦相似度
vocab_size = len(id_to_word)
similarity = np.zeros(vocab_size)
for i in range(vocab_size):
similarity[i] = cos_similarity(word_matrix[i], query_vec)
# 基于余弦相似度,按降序输出值
count = 0
for i in (-1 * similarity).argsort(): # argsort 返回排序后的索引
if id_to_word[i] == query:
continue
print(' %s: %s' % (id_to_word[i], similarity[i]))
count += 1
if count >= top:
return
基于计数的方法的改进
点互信息 (PMI)
Pointwise Mutual Information
- 上一节的共现矩阵的元素表示两个单词同时出现的次数。但是,这种 “原始”的次数并不具备好的性质
- 比如,我们来考虑某个语料库中 the 和 car 共现的情况。在这种情况下,我们会看到很多 “…the car…” 这样的短语。因此,它们的共现次数将会很大。另外,car 和 drive 也明显有很强的相关性。但是,如果只看单词的出现次数,那么与 drive 相比,the 和 car 的相关性更强。这意味着,仅仅因为 the 是个常用词,它就被认为与 car 有很强的相关性
- 为了解决这一问题,可以使用点互信息. 对于随机变量 x x x 和 y y y,

- 在自然语言的例子中, P ( x ) P(x) P(x) 就是指单词 x x x 在语料库中出现的概率, P ( x , y ) P(x, y) P(x,y) 表示单词 x x x 和 y y y 同时出现的概率
- PMI 的值越高,表明相关性越强
- 现在,我们使用共现矩阵(其元素表示单词共现的次数)来重写式 (2.2)。这里,将共现矩阵表示为 C C C,将单词 x x x 和 y y y 的共现次数表示为 C ( x , y ) C(x, y) C(x,y),将单词 x x x 和 y y y 的出现次数分别表示为 C ( x ) C(x) C(x)、 C ( y ) C(y) C(y),将语料库的单词数量记为 N N N,则式 (2.2) 可以重写为:
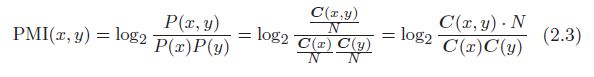
- PMI 也有一个问题。那就是当两个单词的共现次数为 0 时, log 2 0 = − ∞ \log_20 = −∞ log20=−∞。为了解决这个问题,实践上我们会使用下述正的点互信息(Positive PMI,PPMI)
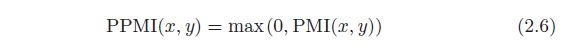
def ppmi(C, verbose=False, eps=1e-8):
M = np.zeros_like(C, dtype=np.float32)
N = np.sum(C)
S = np.sum(C, axis=0)
total = C.shape[0] * C.shape[1]
cnt = 0
for i in range(C.shape[0]):
for j in range(C.shape[1]):
pmi = np.log2(C[i, j] * N / (S[j]*S[i]) + eps)
M[i, j] = max(0, pmi)
if verbose:
cnt += 1
if cnt % (total//100+1) == 0:
print('%.1f%% done' % (100*cnt/total))
return M
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
W = ppmi(C)
np.set_printoptions(precision=3) # 有效位数为3位
print('covariance matrix')
print(C)
print('-'*50)
print('PPMI')
print(W)
output:
covariance matrix
[[0 1 0 0 0 0 0]
[1 0 1 0 1 1 0]
[0 1 0 1 0 0 0]
[0 0 1 0 1 0 0]
[0 1 0 1 0 0 0]
[0 1 0 0 0 0 1]
[0 0 0 0 0 1 0]]
--------------------------------------------------
PPMI
[[ 0. 1.807 0. 0. 0. 0. 0. ]
[ 1.807 0. 0.807 0. 0.807 0.807 0. ]
[ 0. 0.807 0. 1.807 0. 0. 0. ]
[ 0. 0. 1.807 0. 1.807 0. 0. ]
[ 0. 0.807 0. 1.807 0. 0. 0. ]
[ 0. 0.807 0. 0. 0. 0. 2.807]
[ 0. 0. 0. 0. 0. 2.807 0. ]]
- 但是,这个 PPMI 矩阵还是存在一个很大的问题,那就是随着语料库的词汇量增加,各个单词向量的维数也会增加
- 如果语料库的词汇量达到 10 万,则单词向量的维数也同样会达到 10 万。实际上,处理 10 万维向量是不现实的
- 另外,如果我们看一下这个矩阵,就会发现其中很多元素都是 0。这表明向量中的绝大多数元素并不重要。另外,这样的向量也容易受到噪声影响,稳健性差。对于这些问题,一个常见的方法是向量降维
降维 (dimensionality reduction)
- 降维: 在尽量保留“重要信息”的基础上减少向量维度

- 这里的重点是,从稀疏向量中找出重要的轴,用更少的维度对其进行重新表示。结果,稀疏矩阵就会被转化为大多数元素均不为 0 的密集矩阵。这个密集矩阵就是我们想要的单词的分布式表示。
- 降维的方法有很多, 这里我们使用奇异值分解(Singular Value Decomposition,SVD)

- SVD 将任意的矩阵 X X X 分解为 U 、 S 、 V U、S、V U、S、V 这 3 个矩阵的乘积,其中 U U U 和 V V V 是列向量彼此正交的正交矩阵, S S S 是除了对角线元素以外其余元素均为 0 的对角矩阵
- 在式 (2.7) 中, U U U 是正交矩阵。这个正交矩阵构成了一些空间中的基轴(基向量),我们可以将矩阵 U U U 作为“单词空间”。 S S S 是对角矩阵,奇异值在对角线上降序排列。简单地说,我们可以将奇异值视为“对应的基轴”的重要性。这样一来,减少非重要元素就成为可能
- 如图 2-10 所示,矩阵 S S S 的奇异值小,对应的基轴的重要性低,因此,可以通过去除矩阵 U U U 中的多余的列向量来近似原始矩阵。用我们正在处理的“单词的 PPMI 矩阵”来说明的话,矩阵 X X X 的各行包含对应的单词 ID 的单词向量,这些单词向量使用降维后的矩阵 U ′ U' U′ 表示

- 如图 2-10 所示,矩阵 S S S 的奇异值小,对应的基轴的重要性低,因此,可以通过去除矩阵 U U U 中的多余的列向量来近似原始矩阵。用我们正在处理的“单词的 PPMI 矩阵”来说明的话,矩阵 X X X 的各行包含对应的单词 ID 的单词向量,这些单词向量使用降维后的矩阵 U ′ U' U′ 表示
基于 SVD 的降维
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(id_to_word)
C = create_co_matrix(corpus, vocab_size, window_size=1)
W = ppmi(C)
# SVD
U, S, V = np.linalg.svd(W)
如果矩阵大小是 N N N,SVD的计算的复杂度将达到 O ( N 3 ) O(N^3) O(N3), 所以往往会使用 Truncated SVD 等更快的方法。Truncated SVD 通过截去(truncated)奇异值较小的部分,从而实现高速化
# 单词 ID 为 0 的单词向量:
print(C[0]) # 共现矩阵
# [0 1 0 0 0 0 0]
print(W[0]) # PPMI矩阵
# [ 0. 1.807 0. 0. 0. 0. 0. ]
print(U[0]) # SVD
# [ 3.409e-01 -1.110e-16 -1.205e-01 -4.441e-16 0.000e+00 -9.323e-01
# 2.226e-16]
- 如上所示,原先的稀疏向量
W[0]经过 SVD 被转化成了密集向量U[0]。如果要对这个密集向量降维,比如把它降维到二维向量,取出前两个元素即可
print(U[0, :2])
# [ 3.409e-01 -1.110e-16]
- 这样我们就完成了降维。现在,我们用二维向量表示各个单词,并把它们画在图上
for word, word_id in word_to_id.items():
plt.annotate(word, (U[word_id, 0], U[word_id, 1])) # 在 2D 图形中坐标为 (x, y) 的地方绘制单词的文本
plt.scatter(U[:,0], U[:,1], alpha=0.5)
plt.show()
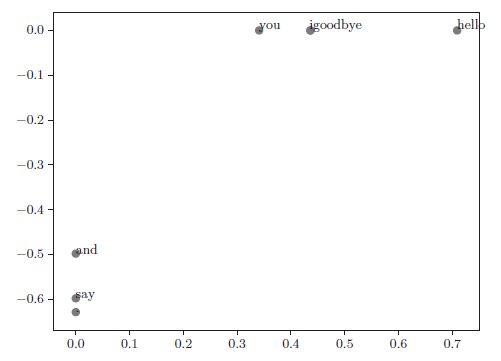
PTB 数据集
Penn Treebank 语料库
- PTB 语料库经常被用作评价提案方法的基准
- 我们使用的 PTB 语料库是以文本文件的形式提供的
- 与原始的 PTB 的文章相比,多了若干预处理,包括将稀有单词替换成特殊字符
N” 等 - 在PTB 语料库中,一行保存一个句子。在本书中,我们将所有句子连接起来,并将其视为一个大的时序数据。此时,在每个句子的结尾处插入一个特殊字符

- 与原始的 PTB 的文章相比,多了若干预处理,包括将稀有单词替换成特殊字符
from dataset import ptb
corpus, word_to_id, id_to_word = ptb.load_data('train')
print('corpus size:', len(corpus))
print('corpus[:30]:', corpus[:30])
print()
print('id_to_word[0]:', id_to_word[0])
print('id_to_word[1]:', id_to_word[1])
print('id_to_word[2]:', id_to_word[2])
print()
print("word_to_id['car']:", word_to_id['car'])
output:
corpus size: 929589
corpus[:30]: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29]
id_to_word[0]: aer
id_to_word[1]: banknote
id_to_word[2]: berlitz
word_to_id['car']: 3856
word_to_id['happy']: 4428
word_to_id['lexus']: 7426
基于 PTB 数据集的评价
window_size = 2
wordvec_size = 100
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
print('counting co-occurrence ...')
C = create_co_matrix(corpus, vocab_size, window_size)
print('calculating PPMI ...')
W = ppmi(C, verbose=True)
print('calculating SVD ...')
try:
# truncated SVD (fast!)
from sklearn.utils.extmath import randomized_svd
U, S, V = randomized_svd(W, n_components=wordvec_size, n_iter=5, random_state=None)
except ImportError:
# SVD (slow)
U, S, V = np.linalg.svd(W)
word_vecs = U[:, :wordvec_size]
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)
output:
[query] you
i: 0.702039909619
we: 0.699448543998
've: 0.554828709147
do: 0.534370693098
else: 0.512044146526
[query] year
month: 0.731561990308
quarter: 0.658233992457
last: 0.622425716735
earlier: 0.607752074689
next: 0.601592506413
[query] car
luxury: 0.620933665528
auto: 0.615559874277
cars: 0.569818364381
vehicle: 0.498166879744
corsica: 0.472616831915
[query] toyota
motor: 0.738666107068
nissan: 0.677577542584
motors: 0.647163210589
honda: 0.628862370943
lexus: 0.604740429865