Hadoop实例WordCount程序修改--词频降序
修改wordcount实例,改为:
1、 对词频按降序排列
2、 输出排序为前三,和后三的数据
首先是第一项:
对词频排序,主要针对的是最后输出的部分。
**
分析程序内容:
**
WordCount.java
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static final Log LOG =
LogFactory.getLog(FileInputFormat.class); //定义log变量
//map过程需要继承org.apache.hadoop.mapreduce包中的Mapper类,并重写map方法。
//这里继承Mapper接口,设置map的输入类型为,输出类型为
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1); //one表示单词只出现一次。为IntWritable类型。
private Text word = new Text(); //word用来存储切下的单词。为Text类型。
//这里map方法的前面两个参数代表输入类型为,对应。
//后面的一个参数context应该是固定要这么写的,输出对到中间文件
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
//对输入的行进行切词。这里输入的Text为一行文本。
//若输入文件中有多行,会由map自动对其进行处理,切分成单行,每行的文本内容为value,key为这一行到文件开头的偏移量。
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken()); //将切分后的单词存到word中。
LOG.info("map过程 : " + word + "~~~~" + key + "@@@@" + one );
context.write(word, one); //将处理结果输出到中间文件,对每个单词定词频为1,中间文件中可能会存在重复行,即一个单词出现不止一次。这里暂不处理。
}
}
}
//reduce过程需要继承org.apache.hadoop.mapreduce包中的Reducer类,并重写其reduce方法。
//这里继承Reducer接口,设置Reduce的输入类型为,输出类型为
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable(); //使用result记录词频。为IntWritable类型。
//reduce方法,前面两个参数是输入类型>,对应。
//后面的一个参数context应该是固定要这么写的,用来输出对到中间文件
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get(); //对获取的计算value的和。这里不太明白是本来输入的就是value-list,还是经过处理,合成的??
LOG.info("val:get()~~~ : " + val.get() + "~~~~" + key );
}
result.set(sum); //这里的sum就是每个word的输出词频
LOG.info("word!!!! : " + result + "~~~~" + key );
context.write(key, result); //输出到中间文件,key为单词,value为词频。
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//检查运行命令
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
//配置作业名
Job job = new Job(conf, "word count");
//配置作业中使用的各种类。
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
//以上部分都是自己配置,也可以使用默认。
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
每个输入文件都是按照这几步进行处理,然后处理完一个输入文件后再处理下一个。
第一步:
Wordcount类中的一个成员函数:map函数
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
//将输入文件的值转为字符串类型后,定义为一个可以分词的对象。
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
//将可分词对象切分成单个的word。
word.set(itr.nextToken());
LOG.info("map过程 : " + word + "~~~~" + key + "@@@@" + one );
每个word的value值定为1,将word作为key。
context.write(word, one);
}
}第二步:
IntSumReducer类中一个成员函数:reduce函数
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
//针对每个key都会调用一次reduce函数,对一个word出现的次数进行计数,出现两次的话会循环两次。
LOG.info("val:get()~~~ : " + val.get() + "~~~~" + key );
}
//这里的sum就是每个word的输出词频
result.set(sum);
//输出,key为word,value为词频。
LOG.info("word!!!! : " + result + "~~~~" + key );
context.write(key, result);
} 一个文件按照上述步骤完成后将结果写入到临时文件中,接着处理第二个文件。到三个文件都已经处理完以后。
第三步:
前面三个输入文件产生的临时数据集中进行处理,执行IntSumReducer类中的reduce函数。与上面第二步相同。执行完毕后输入到另一个临时文件中。
此时,map过程和reduce过程都已经完成了。
中间临时文件以及最后输出都是是按照首字母来排序的,a→z,这里是在map端排序。然后在合并处理三个临时输出文件的过程中,又进行了一次排序,这里是在reduce端排序。
**
排序原理说明
**
map task和reduce task否会对数据按照key值进行排序。
针对map task,会将数据先存放到一个缓冲区,然后当缓冲区数据达到一定量时,对缓冲区数据进行排序,这里采用的排序算法是快速排序算法,并以IFile的文件形式写入到磁盘,当磁盘上文件数达到一定量时,会对这些文件进行合并,并再次排序,这里采用的排序算法是基于堆实现的优先队列。
针对reduce task,会从每个map task上远程拷贝数据,如果数据大小超过一定量则放到磁盘上,没有超过就放在内存中。如果磁盘上文件数目超过一定量则合并为一个大文件。如果内存中文件大小或数目超过一定大小,则会经过一次合并后将数据写入磁盘。当所有数据拷贝完毕后,再由reduce task统一对内存和磁盘上的所有数据进行一次合并。
问题1:这里reduce过程中的排序是只在最后合并所有数据时进行,还是也会像map过程中对每一次合并文件都会进行??
问题2:reduce过程的排序算法使用方式也与map相同?在磁盘上的合并使用基于堆的优先队列,在内存中合并使用快速排序?那么最后的合并是是用什么排序算法?
面临一个很大的问题
巨大的问题。。。没有搞清楚到底哪些函数需要自己编写,哪些是本来就有的,还有背后运行的机理,也没有太清楚。
解决:
《实战hadoo——开启通向云计算的捷径》 刘鹏主编
看书!!我们自己编程写mapreduce任务需要编写哪些东西(就是哪些部分是可以重写,应该重写的),这个可以参考刘鹏的《实战Hadoop》,里面细致的剖析了wordcount程序的运行过程,并说明了哪些函数是我们编程需要实现的。看懂了这些(最好要运行一些这些程序),你基本就可以写一些mapreduce程序,处理一些简单的任务了。
1、 map过程需要继承org.apache.hadoop.mapreduce包中的Mapper类,并重写map方法。
2、 reduce过程需要继承org.apache.hadoop.mapreduce包中的Reducer类,并重写其reduce方法。
问题1。Map方法和reduce方法后面接的参数是怎么定义的,个数,类型?
部分类及参数介绍,其中有些需要重写,有些可以借用默认类:
1、InputFormat类。作用是将输入的数据分割成一个个split,并将split进一步拆分成《key,value》作为map函数的输入。可以通过job.setInputFormatClass()方法进行设置,默认为使用TextInputFormatClass()方法进行设置(该类只处理文本文件)。TextInputFormat将文本文件的多行分割为solits,并通过LineRecorderReader将其中的每一行解析为《key,value》对,key值为对应行在文件中的偏移量,value为行的内容。
2、Mapper类,实现map函数,根据输入的《key,value》对生成中间结果。可以通过job.setMapperClass()方法来进行设置。默认使用Mapper类,Mapper将输入的《key,value》对原封不动地作为中间结果输出。
3、Combiner类。实现combine函数,合并中间结果中具有相同key值的键值对。可以通过job.setCombinerClass()方法进行设置,默认为null,即不合并中间结果。
4、Partitioner类。实现getPartition函数,用于在Shuffle过程中按照key值将中间数据分成R份,每份由一个Reducer负责。可以通过job.setPartitionerClass()方法进行设置,默认使用HashPartitioner类,HashPartitioner使用哈希函数完成Shuffle过程。
5、Reducer类,实现reduce函数,将中间结果合并,得到最终结果。可以使用job.setReducerClass()方法来进行设置,默认使用Reducer类,Reducer将中间结果直接输出作为最终结果。
6、OutputFormat类,负责输出最终结果,可以使用job.setOutputFormatClass()方法进行设置,默认使用TextOutputFormat类,TextOutputFormat将最终结果写成纯文本文件,每行一个《key,value》对,key和value之间用制表符分隔开。
7、除了上述几个类以外,job.setOutputKeyClass()方法和job.setOutputValueClass()方法可以用来设置最终结果(即Reducer的输出结果)的key和value的类型,默认情况下分别为LongWritable和Text。Job.setMapOutputKeyClass()方法和job.setMapOutputValueClass()方法可以用来设置中间结果(即Mapper的输出结果)的key和value的类型,默认情况下与最终结果的类型保持一致。
程序CopyOfWordCount.java
程序参考:
http://blog.csdn.net/zwx19921215/article/details/20712839
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Random;
import java.util.StringTokenizer;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.examples.WordCount2.IntWritableDecreasingComparator;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.map.InverseMapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class CopyOfWordCount {
//定义log变量
public static final Log LOG =
LogFactory.getLog(FileInputFormat.class);
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
LOG.info("map过程 : " + word + "~~~~" + key + "@@@@" + one );
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
LOG.info("val:get()~~~ : " + val.get() + "~~~~" + key );
}
//这里的sum就是每个word的输出词频
result.set(sum);
LOG.info("word!!!! : " + result + "~~~~" + key );
context.write(key, result);
}
}
private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
Path tempDir = new Path("wordcount-temp-" + Integer.toString(
new Random().nextInt(Integer.MAX_VALUE))); //定义一个临时目录
Job job = new Job(conf, "word count");
job.setJarByClass(CopyOfWordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, tempDir);//先将词频统计任务的输出结果写到临时目
//录中, 下一个排序任务以临时目录为输入目录。
job.setOutputFormatClass(SequenceFileOutputFormat.class);
if(job.waitForCompletion(true))
{
Job sortJob = new Job(conf, "sort");
sortJob.setJarByClass(WordCount2.class);
FileInputFormat.addInputPath(sortJob, tempDir);
sortJob.setInputFormatClass(SequenceFileInputFormat.class);
/*InverseMapper由hadoop库提供,作用是实现map()之后的数据对的key和value交换*/
sortJob.setMapperClass(InverseMapper.class);
/*将 Reducer 的个数限定为1, 最终输出的结果文件就是一个。*/
sortJob.setNumReduceTasks(1);
FileOutputFormat.setOutputPath(sortJob, new Path(otherArgs[1]));
sortJob.setOutputKeyClass(IntWritable.class);
sortJob.setOutputValueClass(Text.class);
/*Hadoop 默认对 IntWritable 按升序排序,而我们需要的是按降序排列。
* 因此我们实现了一个 IntWritableDecreasingComparator 类,
* 并指定使用这个自定义的 Comparator 类对输出结果中的 key (词频)进行排序*/
sortJob.setSortComparatorClass(IntWritableDecreasingComparator.class);
System.exit(sortJob.waitForCompletion(true) ? 0 : 1);
}
FileSystem.get(conf).deleteOnExit(tempDir);
}
}
输出结果:

ps:快速排序算法:
分析分析分析!
初始值:
12 3
4 4
1 6
4 6
4 2
6 6处理过程:
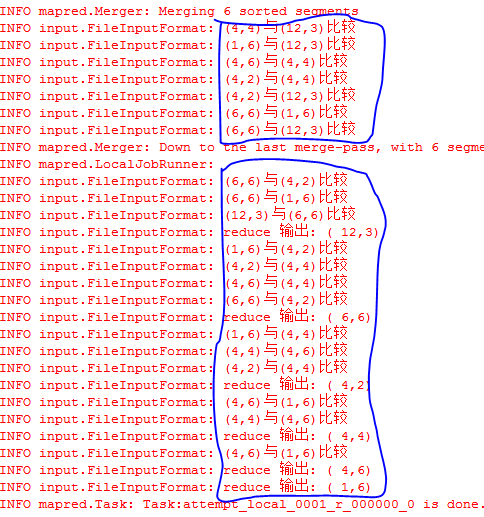
最终值:
12 3
6 6
4 2
4 4
4 6
1 6