python 逻辑回归准确率是1_使用Python进行机器学习:从0到1,构建回归模型(附完整教程)...
摘要
在本文中,我将使用数据科学和Python来解释回归用例的主要步骤,从数据分析到理解模型输出。
我将介绍一些非常有用的Python代码,当你遇到相同的情况时,只需要复制,粘贴,运行,就能轻松使用。在每行代码中都添加注释,复制过去就能使用(下面是完整的代码链接)。
https://github.com/mdipietro09/DataScience_ArtificialIntelligence_Utils/blob/master/machine_learning/example_regression.ipynb
本文使用的数据是“房价数据集”,提供多个解释变量,描述住宅的不同方面,我们的任务是预测每套住房的最终价格。
数据集:https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data
主要步骤包括:
- 环境设置:导入库和读取数据
- 数据分析:了解变量的含义和预测能力
- 特征工程:从原始数据中提取特征
- 预处理:数据分区,处理丢失的值,编码分类变量,缩放
- 特征选择:只保留最相关的变量
- 模型设计:基线、训练、验证、测试
- 绩效评估:阅读指标
- 可解释性:了解模型如何进行预测
安装程序
首先,我们需要导入以下库。
## 用于数据import pandas as pdimport numpy as np## 用于绘图import matplotlib.pyplot as pltimport seaborn as sns##用于统计检验import scipyimport statsmodels.formula.api as smfimport statsmodels.api as sm##用于机器学习from sklearn import model_selection, preprocessing, feature_selection, ensemble, linear_model, metrics, decomposition## 用于解析器from lime import lime_tabular接下来我将数据导入pandas数据框。原始数据集包含81列,但在本教程中,我将使用其中的12列子集。
dtf = pd.read_csv("data_houses.csv")cols ["OverallQual","GrLivArea","GarageCars", "GarageArea","TotalBsmtSF","FullBath", "YearBuilt","YearRemodAdd", "LotFrontage","MSSubClass"]dtf = dtf[["Id"]+cols+["SalePrice"]]dtf.head()
关于列的详细信息可以在提供的数据集链接中找到。
表格中的每一行代表一个特定的房子。
一切准备就绪,我将从分析数据开始,然后选择特征,建立机器学习模型并进行预测。
数据分析
在统计学中,探索性数据分析是一个总结数据集主要特征的过程,以了解数据在形式化建模或假设检验任务之外能告诉我们什么。
一般来说,如果我想知道有多少分类变量和数值变量,以及丢失数据的比例,我都会从对数据集的概述开始。有时候会很难识别变量的类型,因为类别可以表示为数字。为此,我编写了一个简单的函数来帮助我们:
'''Recognize whether a column is numerical or categorical.'''def utils_recognize_type(dtf, col, max_cat=20): if (dtf[col].dtype == "O") | (dtf[col].nunique() < max_cat): return "cat" else: return "num"此函数非常有用,可用于多种场合。为了举例说明,我将绘制数据帧的热图,并可视化列类型和缺少的数据。
dic_cols = {col:utils_recognize_type(dtf, col, max_cat=max_cat) for col in dtf.columns}heatmap = dtf.isnull()for k,v in dic_cols.items(): if v == "num": heatmap[k] = heatmap[k].apply(lambda x: 0.5 if x is False else 1) else: heatmap[k] = heatmap[k].apply(lambda x: 0 if x is False else 1)sns.heatmap(heatmap, cbar=False).set_title('Dataset Overview')plt.show()print("033[1;37;40m Categerocial ", "033[1;30;41m Numeric ", "033[1;30;47m NaN ")
该数据集中共有1460行和12列数据:
表格的每一行代表一个有ID标识的房屋,因此我将其设置为索引。
SalePrice是我们要了解和预测的因变量,因此我将列重命名为“ Y”。
TotalQuall,GarageCars,FullBath和MSSubClass是类别变量,其他则是数字变量。
只有LotFrontage包含丢失的数据。
dtf = dtf.set_index("Id")dtf = dtf.rename(columns={"SalePrice":"Y"})可视化是数据分析的最佳工具,前提是你要知道什么样的图更适合不同类型的变量。因此我们要用代码来为不同的示例绘制适当的可视化效果。
首先,让我们看看单变量分布(只有一个变量的概率分布)。直方图是一种完美的方法,可以粗略地反映单个数值数据的基本分布密度。我建议使用直方图图通过数据组的四分位数以图形方式来进行描述。绘制目标变量:
x = "Y"fig, ax = plt.subplots(nrows=1, ncols=2, sharex=False, sharey=False)fig.suptitle(x, fontsize=20)###分布ax[0].title.set_text('distribution')variable = dtf[x].fillna(dtf[x].mean())breaks = np.quantile(variable, q=np.linspace(0, 1, 11))variable = variable[ (variable > breaks[quantile_breaks[0]]) & (variable < breaks[quantile_breaks[1]]) ]sns.distplot(variable, hist=True, kde=True, kde_kws={"shade": True}, ax=ax[0])des = dtf[x].describe()ax[0].axvline(des["25%"], ls='--')ax[0].axvline(des["mean"], ls='--')ax[0].axvline(des["75%"], ls='--')ax[0].grid(True)des = round(des, 2).apply(lambda x: str(x))box = ''.join(("min: "+des["min"], "25%: "+des["25%"], "mean: "+des["mean"], "75%: "+des["75%"], "max: "+des["max"]))ax[0].text(0.95, 0.95, box, transform=ax[0].transAxes, fontsize=10, va='top', ha="right", bbox=dict(boxstyle='round', facecolor='white', alpha=1))###方块图ax[1].title.set_text('outliers (log scale)')tmp_dtf = pd.DataFrame(dtf[x])tmp_dtf[x] = np.log(tmp_dtf[x])tmp_dtf.boxplot(column=x, ax=ax[1])plt.show()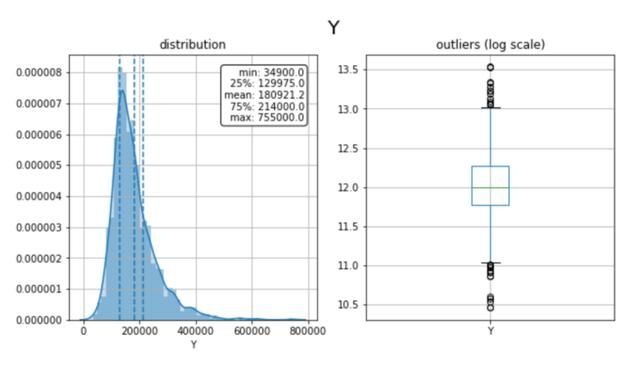
该人群中房屋的平均价格为$181k,分布高度偏斜,并且两边都有异常值。
此外,条形图适合于理解单个分类变量的标签频率。 让我们以FullBath(浴室数量)变量为例:它具有常规性(2个浴室> 1个浴室),但不是连续的(一个家庭不能有1.5个浴室),因此可以将其作为分类进行分析。
x = "Y"ax = dtf[x].value_counts().sort_values().plot(kind="barh")totals= []for i in ax.patches: totals.append(i.get_width())total = sum(totals)for i in ax.patches: ax.text(i.get_width()+.3, i.get_y()+.20, str(round((i.get_width()/total)*100, 2))+'%', fontsize=10, color='black')ax.grid(axis="x")plt.suptitle(x, fontsize=20)plt.show()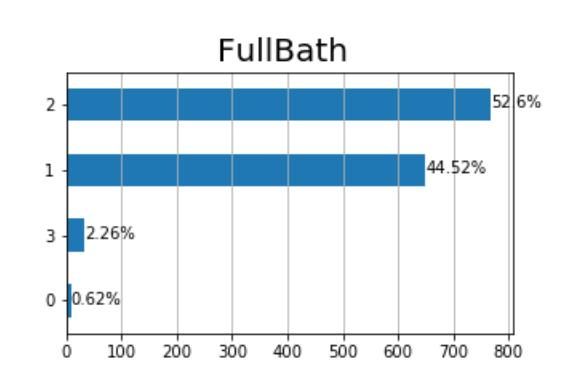
大多数房子都有一个或两个浴室,有0和3个浴室是异常值。
我将把分析提高一个层次来研究二元分布,以了解FullBath是否具有预测Y的预测能力。这将是分类(FullBath)与数值(Y)的情况,因此我将如下进行:
- 将人群(整个观察组)分成4个样本:有0个浴室(FullBath=0)、1个浴室(FullBath=1)的房屋部分,等等…
- 绘制并比较4个样本的密度,如果分布不同,则变量是预测性的,因为4组有不同的模式。
- 将数值变量(Y)分组到容器(子样本)中,并绘制每个容器的组成图,如果所有容器中类别的比例相似,则该变量不具有预测性。
- 绘制并比较4个样本的直方图,以发现异常值的不同行为。
cat, num = "FullBath", "Y"fig, ax = plt.subplots(nrows=1, ncols=3, sharex=False, sharey=False)fig.suptitle(x+" vs "+y, fontsize=20) ### 分布ax[0].title.set_text('density')for i in dtf[cat].unique(): sns.distplot(dtf[dtf[cat]==i][num], hist=False, label=i, ax=ax[0])ax[0].grid(True)###叠放ax[1].title.set_text('bins')breaks = np.quantile(dtf[num], q=np.linspace(0,1,11))tmp = dtf.groupby([cat, pd.cut(dtf[num], breaks, duplicates='drop')]).size().unstack().Ttmp = tmp[dtf[cat].unique()]tmp["tot"] = tmp.sum(axis=1)for col in tmp.drop("tot", axis=1).columns: tmp[col] = tmp[col] / tmp["tot"]tmp.drop("tot", axis=1).plot(kind='bar', stacked=True, ax=ax[1], legend=False, grid=True)### 方块图 ax[2].title.set_text('outliers')sns.catplot(x=cat, y=num, data=dtf, kind="box", ax=ax[2])ax[2].grid(True)plt.show()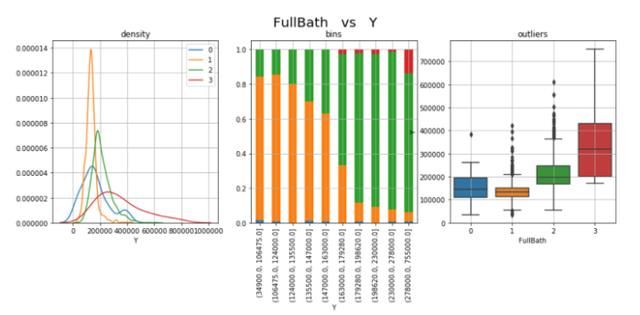
FullBath好像具有预测性,因为这四个样本的分布在价格水平和观察次数上有很大差异。 看起来房屋中的浴室越多,价格就越高,但我想知道0浴室样本和3浴室样本中的观察值是否具有统计意义,因为它们包含的观察值很少。
如果不被“直觉”所信服,你可以使用好的旧统计数据并进行测试。 在分类(FullBath)与数字(Y)的情况下,使用单向ANOVA检验。 基本上,它测试两个或更多个独立样本的均值是否显着不同,因此,如果p值足够小(<0.05),则样本的零假设意味着不相等。
cat, num = "FullBath", "Y"model = smf.ols(num+' ~ '+cat, data=dtf).fit()table = sm.stats.anova_lm(model)p = table["PR(>F)"][0]coeff, p = None, round(p, 3)conclusion = "Correlated" if p < 0.05 else "Non-Correlated"print("Anova F: the variables are", conclusion, "(p-value: "+str(p)+")")我们可以得出结论,浴室的数量决定了房价的高低。这是有一定道理的,因为更多的浴室意味着更大的房子,房子的大小是一个重要的价格因素。
为了检验第一个结论的有效性,我必须分析目标变量相对于GrLivArea(居住面积)的行为。这是数值(grlivrea)与数值(Y)的情况,因此我将生成两个图:
- 首先,我将把GrLivArea值分组到存储箱中,比较每个存储箱中Y的平均值(和中值),如果曲线不是平坦的,那么变量是可预测的,因为存储箱有不同的模式。
- 其次,我将使用一个散点图,其中两边是两个变量的分布。
x, y = "GrLivArea", "Y"###本图dtf_noNan = dtf[dtf[x].notnull()]breaks = np.quantile(dtf_noNan[x], q=np.linspace(0, 1, 11))groups = dtf_noNan.groupby([pd.cut(dtf_noNan[x], bins=breaks, duplicates='drop')])[y].agg(['mean','median','size'])fig, ax = plt.subplots(figsize=figsize)fig.suptitle(x+" vs "+y, fontsize=20)groups[["mean", "median"]].plot(kind="line", ax=ax)groups["size"].plot(kind="bar", ax=ax, rot=45, secondary_y=True, color="grey", alpha=0.3, grid=True)ax.set(ylabel=y)ax.right_ax.set_ylabel("Observazions in each bin")plt.show()### 散点图sns.jointplot(x=x, y=y, data=dtf, dropna=True, kind='reg', height=int((figsize[0]+figsize[1])/2) )plt.show()

GrLivArea是可预测的,有一个明确的模式:平均来说,房屋越大,价格越高,即使有些离群值均高于平均且价格相对较低的离群值。
和上面一样,我们可以测试这两个变量之间的相关性。 由于它们都是数值,因此我将检验皮尔逊的相关系数:假设两个变量是独立的(零假设),它将检验两个样本是否具有线性关系。 如果p值足够小(<0.05),则可以拒绝原假设,并且可以说这两个变量可能是相关的。
x, y = "GrLivArea", "Y"dtf_noNan = dtf[dtf[x].notnull()]coeff, p = scipy.stats.pearsonr(dtf_noNan[x], dtf_noNan[y])coeff, p = round(coeff, 3), round(p, 3)conclusion = "Significant" if p < 0.05 else "Non-Significant"print("Pearson Correlation:", coeff, conclusion, "(p-value: "+str(p)+")")FullBath和GrLivArea是预测特性的示例,因此我将保留这两个变量用于建模。
我们应该对数据集中的每个变量进行此类分析,以确定哪些应该保留为潜在特征,哪些不具有预测性可以删除。
特征工程
我们还可以利用领域知识从原始数据中创建新特性。这里有一个示例:MSSubClass列(building类)包含15个类的大类别,在建模过程中可能会导致多维度的问题:
sns.catplot(x="MSSubClass", y="Y", data=dtf, kind="box")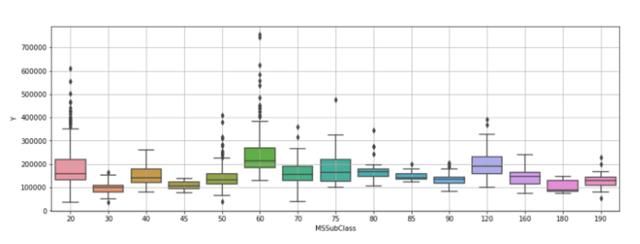
由上图可以看出,类别太多,很难理解每个类别中的分布。 因此,我将这些类别归为一组:Y值较高的类(例如MSSubClass 60和120)将进入“最大”类,价格较低的类(例如MSSubClass 30、45、180)将进入“ 最小”类,其余的将分组为“平均”类。
## 定义类MSSubClass_clusters = {"min":[30,45,180], "max":[60,120], "mean":[]}## 创建新列dic_flat = {v:k for k,lst in MSSubClass_clusters.items() for v in lst}for k,v in MSSubClass_clusters.items(): if len(v)==0: residual_class = k dtf[x+"_cluster"] = dtf[x].apply(lambda x: dic_flat[x] if x in dic_flat.keys() else residual_class)## 输出dtf[["MSSubClass","MSSubClass_cluster","Y"]].head()
这样,类别的数量就从15个减少到3个,对于数据分析是很好的方法:
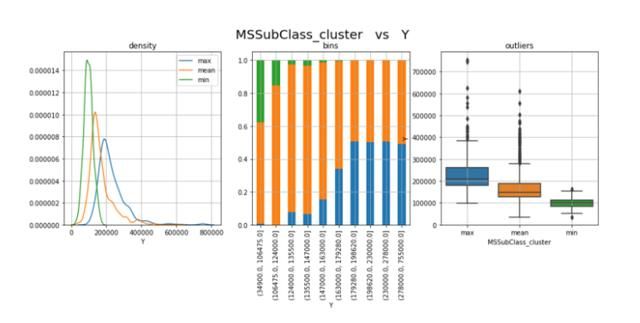
新的分类特性更易于读取,并且保持了原始数据中显示的模式,因此我将保留MSSubClass_集群,而不是MSSubClass列。
预处理
数据预处理是准备原始数据以使其适合机器学习模型的阶段。
- 每个观察值必须用一行表示,换句话说,不能有两行描述同一个乘客,因为它们将由模型单独处理。此外,每一列都应该是一个特征,所以不应该使用Id作为预测值,这就是为什么这种表被称为“特征矩阵”。
- 数据集必须至少分为两组:模型应在数据集的重要部分(所谓的“训练集”)上进行训练,并在较小的集(“测试集”)上进行测试。
- 丢失的值应该替换为某些值,否则,您的模型可能会崩溃。
- 分类数据必须编码,这意味着将标签转换为整数,因为机器学习需要的是数字,而不是字符串。
- 缩放数据是很好的实践,它有助于在特定范围内规范化数据,并加快算法的计算速度。
让我们首先对数据集进行分区。当将数据拆分成列和测试集时,必须遵循一个基本规则:列集中的行不应该出现在测试集中。这是因为模型在训练过程中看到目标值,并用它来理解这种现象。换言之,模型已经知道了训练观察的正确答案,并且对这些结果进行测试就像作弊一样。
## 拆分数据dtf_train, dtf_test = model_selection.train_test_split(dtf, test_size=0.3)##输出信息print("X_train shape:", dtf_train.drop("Y",axis=1).shape, "| X_test shape:", dtf_test.drop("Y",axis=1).shape)print("y_train mean:", round(np.mean(dtf_train["Y"]),2), "| y_test mean:", round(np.mean(dtf_test["Y"]),2))print(dtf_train.shape[1], "features:", dtf_train.drop("Y",axis=1).columns.to_list())
下一步:LotFrontage列包含一些需要处理的丢失数据(17%)。从机器学习的角度来看,首先分为训练和测试,然后用训练集的平均值替换NAs是正确的。
dtf_train["LotFrontage"] = dtf_train["LotFrontage"].fillna(dtf_train["LotFrontage"].mean())我创建的新列MSSubClass_cluster包含应该编码的分类数据。我将使用一个热编码方法,将一个具有n个唯一值的分类列转换为n-1个虚拟列。
## 创建虚拟对象dummy = pd.get_dummies(dtf_train["MSSubClass_cluster"], prefix="MSSubClass_cluster",drop_first=True)dtf_train= pd.concat([dtf_train, dummy], axis=1)print( dtf_train.filter(like="MSSubClass_cluster",axis=1).head() )## 删除原始分类列dtf = dtf_train.drop("MSSubClass_cluster", axis=1)
最后,我需要扩展该功能。 对于回归问题,通常需要同时转换输入变量和目标变量。 我将使用RobustScaler,它通过减去中位数然后除以四分位间距(75%值– 25%值)来变换特征。 这种缩放器的优点是不受异常值的影响。
## 标度XscalerX = preprocessing.RobustScaler(quantile_range=(25.0, 75.0))X = scaler.fit_transform(dtf_train.drop("Y", axis=1))dtf_scaled= pd.DataFrame(X, columns=dtf_train.drop("Y", axis=1).columns, index=dtf_train.index)## 标度YscalerY = preprocessing.RobustScaler(quantile_range=(25.0, 75.0))dtf_scaled[y] = scalerY.fit_transform( dtf_train[y].values.reshape(-1,1))dtf_scaled.head()
特征选择
特征选择是选择相关变量子集建立机器学习模型的过程。它使模型更易于解释,并减少了过度拟合(当模型对训练数据的适应性太强,并且在训练集外表现不佳时)。
在数据分析期间,我已经通过排除不相关的列进行了第一次“手动”特性选择。现在它会有点不同,因为我们必须处理多重共线性问题,指的是多元回归模型中两个或多个解释变量高度线性相关的情况。
我将用一个例子来解释:车库面积与车库高度相关,因为它们都提供相同的信息。让我们计算相关矩阵:
corr_matrix = dtf_train.corr(method="pearson")sns.heatmap(corr_matrix, vmin=-1., vmax=1., annot=True, fmt='.2f', cmap="YlGnBu", cbar=True, linewidths=0.5)plt.title("pearson correlation")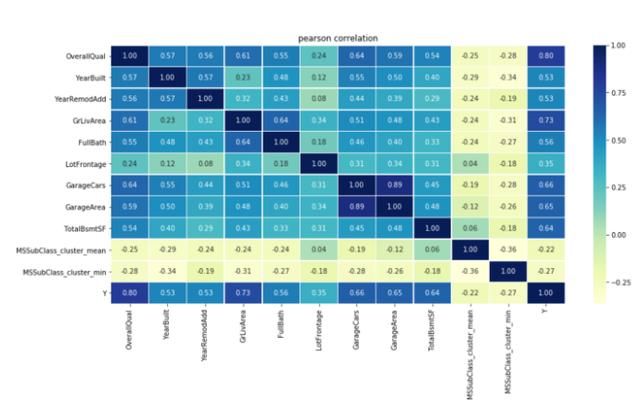
车库和车库区域中的一个可能是不必要的,我们可以决定放弃它,保留最有用的一个(即p值最低的那个或熵降低最大的那个)。
线性回归是建模标量响应与一个或多个解释变量之间关系的线性方法。单变量线性回归检验广泛应用于检验多个回归者的个体效应:首先计算各回归者与目标之间的相关性,然后进行方差分析F检验。
RIDGE正则化对于缓解线性回归中的多重共线性问题非常有用,线性回归通常发生在具有大量参数的模型中。
X = dtf_train.drop("Y", axis=1).valuesy = dtf_train["Y"].valuesfeature_names = dtf_train.drop("Y", axis=1).columns## p值selector = feature_selection.SelectKBest(score_func= feature_selection.f_regression, k=10).fit(X,y)pvalue_selected_features = feature_names[selector.get_support()]## 正则化selector = feature_selection.SelectFromModel(estimator= linear_model.Ridge(alpha=1.0, fit_intercept=True), max_features=10).fit(X,y)regularization_selected_features = feature_names[selector.get_support()] ## 绘图dtf_features = pd.DataFrame({"features":feature_names})dtf_features["p_value"] = dtf_features["features"].apply(lambda x: "p_value" if x in pvalue_selected_features else "")dtf_features["num1"] = dtf_features["features"].apply(lambda x: 1 if x in pvalue_selected_features else 0)dtf_features["regularization"] = dtf_features["features"].apply(lambda x: "regularization" if x in regularization_selected_features else "")dtf_features["num2"] = dtf_features["features"].apply(lambda x: 1 if x in regularization_selected_features else 0)dtf_features["method"] = dtf_features[["p_value","regularization"]].apply(lambda x: (x[0]+" "+x[1]).strip(), axis=1)dtf_features["selection"] = dtf_features["num1"] + dtf_features["num2"]dtf_features["method"] = dtf_features["method"].apply(lambda x: "both" if len(x.split()) == 2 else x)sns.barplot(y="features", x="selection", hue="method", data=dtf_features.sort_values("selection", ascending=False), dodge=False)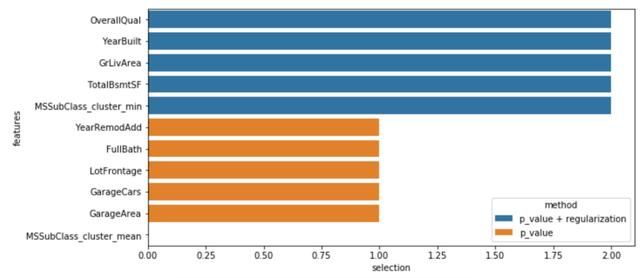
蓝色特征是通过方差分析和RIDGE选择的特征,其他特征是通过第一种统计方法选择的。
或者,可以使用集成方法获取特征重要性。集成方法使用多个学习算法,以获得比单独从任何组成学习算法获得的更好的预测性能。我将给出一个使用梯度提升算法的例子:它以正向阶段的方式构建一个加法模型,并且在每个阶段中,在给定损失函数的负梯度上拟合一个回归树。
X = dtf_train.drop("Y", axis=1).valuesy = dtf_train["Y"].valuesfeature_names = dtf_train.drop("Y", axis=1).columns.tolist()## 呼叫模型model = ensemble.GradientBoostingRegressor()## 重要性model.fit(X,y)importances = model.feature_importances_## 放入Pandas dtfdtf_importances = pd.DataFrame({"IMPORTANCE":importances, "VARIABLE":feature_names}).sort_values("IMPORTANCE", ascending=False)dtf_importances['cumsum'] = dtf_importances['IMPORTANCE'].cumsum(axis=0)dtf_importances = dtf_importances.set_index("VARIABLE") ## 绘图fig, ax = plt.subplots(nrows=1, ncols=2, sharex=False, sharey=False)fig.suptitle("Features Importance", fontsize=20)ax[0].title.set_text('variables') dtf_importances[["IMPORTANCE"]].sort_values(by="IMPORTANCE").plot( kind="barh", legend=False, ax=ax[0]).grid(axis="x")ax[0].set(ylabel="")ax[1].title.set_text('cumulative')dtf_importances[["cumsum"]].plot(kind="line", linewidth=4, legend=False, ax=ax[1])ax[1].set(xlabel="", xticks=np.arange(len(dtf_importances)), xticklabels=dtf_importances.index)plt.xticks(rotation=70)plt.grid(axis='both')plt.show()
很有意思的是,在所有提出的方法中,OverallQual、GrLivArea和TotalBsmtSf占主导地位。
就我个人而言,我总是尽量使用最少的功能,因此在这里,我选择以下功能,并继续设计、训练、测试和评估机器学习模型:
X_names = ['OverallQual', 'GrLivArea', 'TotalBsmtSF', "GarageCars"]X_train = dtf_train[X_names].valuesy_train = dtf_train["Y"].valuesX_test = dtf_test[X_names].valuesy_test = dtf_test["Y"].values请注意,在使用测试数据进行预测之前,你必须像我们对列车数据那样对其进行预处理。
模型设计
最后,是时候建立机器学习模型了。我将首先运行一个简单的线性回归,并将其用作一个更复杂模型的基线,如梯度增强算法。
我通常使用的第一个度量是R的平方,它表示从自变量可以预测的因变量中的方差的比例。
我将使用k倍交叉验证比较线性回归R平方和梯度增强的R平方,这是一个将数据k次分割成训练集和验证集的过程,对于每个分割,模型都经过训练和测试。它用于检查模型是否能够通过某些数据进行训练并预测未看到的数据。
我将通过绘制预测值与实际Y的对比来可视化验证的结果。理想情况下,点应该都靠近预测=实际的对角线。
## 呼叫模型model = linear_model.LinearRegression()## K折验证scores = []cv = model_selection.KFold(n_splits=5, shuffle=True)fig = plt.figure()i = 1for train, test in cv.split(X_train, y_train): prediction = model.fit(X_train[train], y_train[train]).predict(X_train[test]) true = y_train[test] score = metrics.r2_score(true, prediction) scores.append(score) plt.scatter(prediction, true, lw=2, alpha=0.3, label='Fold %d (R2 = %0.2f)' % (i,score)) i = i+1plt.plot([min(y_train),max(y_train)], [min(y_train),max(y_train)], linestyle='--', lw=2, color='black')plt.xlabel('Predicted')plt.ylabel('True')plt.title('K-Fold Validation')plt.legend()plt.show()
线性回归的平均R平方为0.77,让我们看看梯度增强验证是如何进行的:
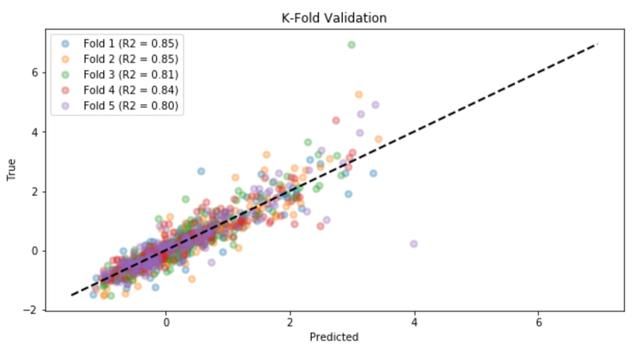
梯度增强模型表现出更好的性能(平均R平方为0.83),因此我将使用它来预测测试数据:
##训练model.fit(X_train, y_train)## 测试predicted = model.predict(X_test)记住,数据是按比例缩放的,因此为了将预测值与测试集中的实际房价进行比较,必须对其进行不缩放(使用反变换函数):
predicted = scalerY.inverse_transform( predicted.reshape(-1,1) ).reshape(-1)模型评估
我们的重点是研究Y模型能解释多大的方差以及误差的分布。
我将使用以下常用度量来评估模型:R平方、平均绝对误差(MAE)和均方根误差(RMSD)。最后两个是表示相同现象的成度观测之间的误差度量。由于误差可以是正值(实际值>预测值)和负值(实际值
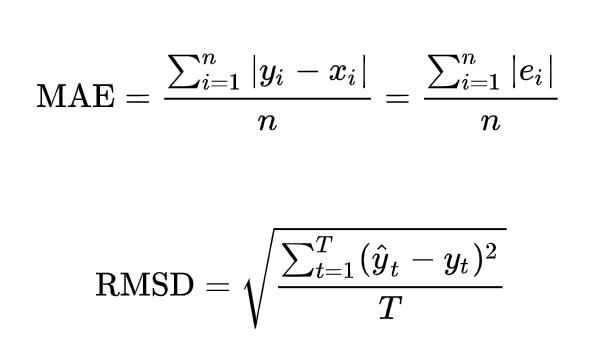
## Kpiprint("R2 (explained variance):", round(metrics.r2_score(y_test, predicted), 2))print("Mean Absolute Perc Error (Σ(|y-pred|/y)/n):", round(np.mean(np.abs((y_test-predicted)/predicted)), 2))print("Mean Absolute Error (Σ|y-pred|/n):", "{:,.0f}".format(metrics.mean_absolute_error(y_test, predicted)))print("Root Mean Squared Error (sqrt(Σ(y-pred)^2/n)):", "{:,.0f}".format(np.sqrt(metrics.mean_squared_error(y_test, predicted))))## 残差residuals = y_test - predictedmax_error = max(residuals) if abs(max(residuals)) > abs(min(residuals)) else min(residuals)max_idx = list(residuals).index(max(residuals)) if abs(max(residuals)) > abs(min(residuals)) else list(residuals).index(min(residuals))max_true, max_pred = y_test[max_idx], predicted[max_idx]print("Max Error:", "{:,.0f}".format(max_error))
模型解释了目标变量86%的方差。平均来说,预测的误差是2万美元,或者是11%。测试集上最大的错误超过17万美元,我们可以通过绘制预测值与实际值以及每个预测值的残差(误差)来可视化错误。
## 预测图 VS 真实图fig, ax = plt.subplots(nrows=1, ncols=2)from statsmodels.graphics.api import abline_plotax[0].scatter(predicted, y_test, color="black")abline_plot(intercept=0, slope=1, color="red", ax=ax[0])ax[0].vlines(x=max_pred, ymin=max_true, ymax=max_true-max_error, color='red', linestyle='--', alpha=0.7, label="max error")ax[0].grid(True)ax[0].set(xlabel="Predicted", ylabel="True", )ax[0].legend() ## 预测 VS 残差图ax[1].scatter(predicted, residuals, color="red")ax[1].vlines(x=max_pred, ymin=0, ymax=max_error, color='black', linestyle='--', alpha=0.7, label="max error")ax[1].grid(True)ax[1].set(xlabel="Predicted", ylabel="Residuals", )ax[1].hlines(y=0, xmin=np.min(predicted), xmax=np.max(predicted))ax[1].legend()plt.show()
在那里,最大误差为-170k:该模型预测的误差约为320k,而该观测值的真实值约为150k。 看来大多数错误都在50k到-50k之间,让我们更好地看一下残差的分布,看看它看起来是否近似正态:
fig, ax = plt.subplots()sns.distplot(residuals, color="red", hist=True, kde=True, kde_kws={"shade":True}, ax=ax)ax.grid(True)ax.set(yticks=[], yticklabels=[], )plt.show()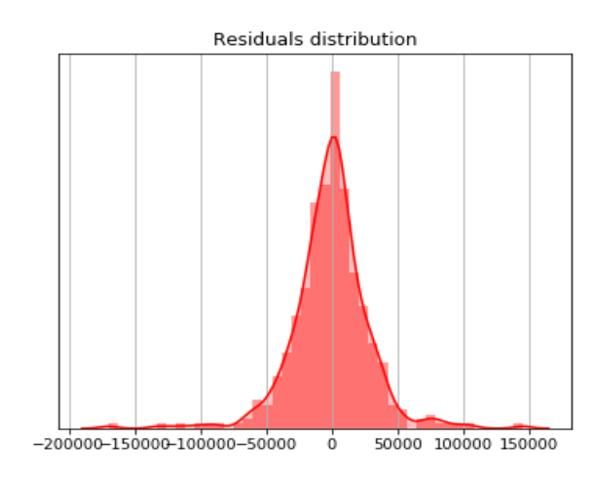
可解释性
你已经分析并理解了数据,训练好模型并进行了测试,甚至对性能感到满意。 你也可以证明你的机器学习模型不是黑匣子。
Lime软件包可以帮助我们构建解释器。 为了举例说明,我将从测试集中随机观察并观察模型的预测结果:
print("True:", "{:,.0f}".format(y_test[1]), "--> Pred:", "{:,.0f}".format(predicted[1]))
模型预测这所房子的价格为194870美元。
explainer = lime_tabular.LimeTabularExplainer(training_data=X_train, feature_names=X_names, class_names="Y", mode="regression")explained = explainer.explain_instance(X_test[1], model.predict, num_features=10)explained.as_pyplot_figure()
这一预测的主要因素是该房屋有一个大的地下室(TotalBsmft>1.3k),它是用优质材料建造的(总体质量>6),它是最近建造的(yearbuild>2001)。
预测与实际值的对比图是一个很好的工具,可以显示测试的进展情况,但我也绘制了回归平面图,以直观地帮助我们发现模型没有正确预测的异常值。因为它更适合线性模型,所以我将使用线性回归来拟合二维数据。为了绘制二维数据,需要进行一些降维(通过获取一组主变量来减少特征数量的过程)。本文以PCA算法为例,将数据归纳为两个变量,通过特征的线性组合得到。
## PCApca = decomposition.PCA(n_components=2)X_train_2d = pca.fit_transform(X_train)X_test_2d = pca.transform(X_test)## 训练2D模型model_2d = linear_model.LinearRegression()model_2d.fit(X_train, y_train)## 绘制回归平面from mpl_toolkits.mplot3d import Axes3Dax = Axes3D(plt.figure())ax.scatter(X_test[:,0], X_test[:,1], y_test, color="black")X1 = np.array([[X_test.min(), X_test.min()], [X_test.max(), X_test.max()]])X2 = np.array([[X_test.min(), X_test.max()], [X_test.min(), X_test.max()]])Y = model_2d.predict(np.array([[X_test.min(), X_test.min(), X_test.max(), X_test.max()], [X_test.min(), X_test.max(), X_test.min(), X_test.max()]]).T).reshape((2,2))Y = scalerY.inverse_transform(Y)ax.plot_surface(X1, X2, Y, alpha=0.5)ax.set(zlabel="Y", , xticklabels=[], yticklabels=[])plt.show()结论
本文演示了如何使用数据科学处理回归用例。我以房价数据集为例,从数据分析到机器学习模型的各个步骤。
在探索阶段中,我分析了单个类别变量,单个数值变量的情况以及它们如何相互作用。我举了一个特征工程示例,从原始数据中提取特征。关于预处理,我解释了如何处理缺失值和分类数据。我展示了选择正确特征的不同方法,如何使用它们构建回归模型以及如何评估性能。在最后一部分中,我对如何提高机器学习模型的可解释性提出了一些建议。
最后,还有一个很重要的事:如果模型通过部署后会发生什么?你只要做一件事:建立一个管道来自动处理定期获取的新数据。
到这里,已经基本说完了用Python解决机器学习中的回归模型问题,赶紧试试吧~
--END--
欢迎大家关注我们的公众号:为AI呐喊(weainahan)
找工作一定少不了项目实战经验,为了帮助更多缺少项目实战的同学入门Python,我们在头条上创建了一个专栏:《7小时快速掌握Pthon核心编程》,通过一个项目,快速掌握Python,欢迎大家点击链接或者阅读原文进行试看~